7. 配置 preload 门限,参见本文 1.2 节的叙述。
2.2.2 创建生产者/消费者场景
前面介绍过,在 OpenEM 中,消费者就是 execution object,沟通生产者和消费者的管道就是queue。本小节介绍怎样创建 execution object 和 queue 以及怎样把它们关联起来。 关于怎样产生 event,本文在下一小节描述。OpenEM 有下列 API 供应用调用:
• 调用 em_eo_create()可以创建 execution object
• 调用 em_queue_create()可以创建 queue
• 调用 em_eo_add_queue()可以把 queue 和 execution object 映射起来
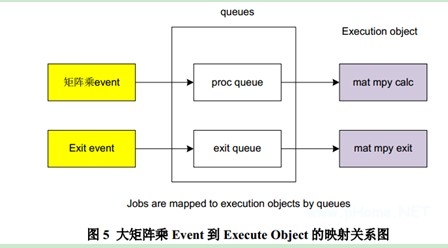
本演示用例通过参数配置表列出 execution object, queue group object 和 queue object 的参数,然后通过解析函数解析配置表再调用 OpenEM的 API,这样各个软件对象的参数在配置表中一目了然,代码的可读性较好。图 5 是本演示用例的映射关系。

需要注意的是 coremask 总共有 64 个比特,但是目前 6678 最多也只有 8 个 DSP 核。所以大量 mask 比特是用不到的,目前。核 0~7 对应的 mask 比特是位于 byte[4]的 bit0:7
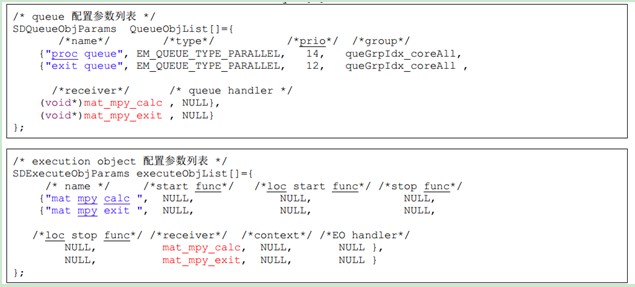
需要注意的是 queue 到 execution object 的映射是通过 receiver 函数关联起来,如红色高亮显示部分。
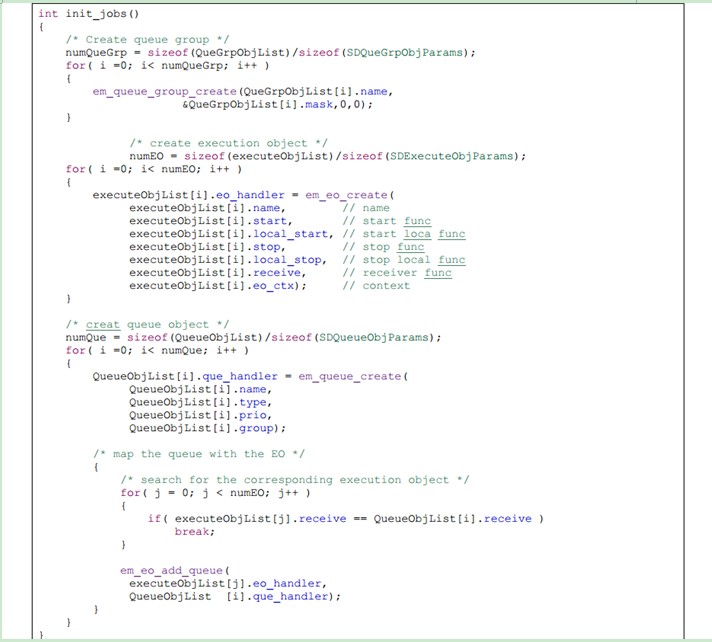
初始化job的伪代码如下:
2.2.3 产生 event
本文的演示用例把 matrix Y 切分成了 128 个 2048*16 的子块,每个 event 对应一个子块。Event被发送给 execution object 以后,receive 函数计算 Matrix X 乘与 matrix Y block,即 100*2048 ×2048*16 的矩阵乘,产生 100*16 个输出。event 的产生包括下面几个简单步骤:
• 调用 em_alloc 函数,从 public pool 获取 free 的 event 描述符并且 enable preloading。
• 把待处理的数据缓冲区挂到描述符上,也就是把描述符的 buffer 指针指向这个数据缓冲区。
• 在描述符的 software info 域填上 job index。
• 调用 em_send,把 event 发送到对应的 queue,也就是 proc queue。
下面是产生 event 的代码:
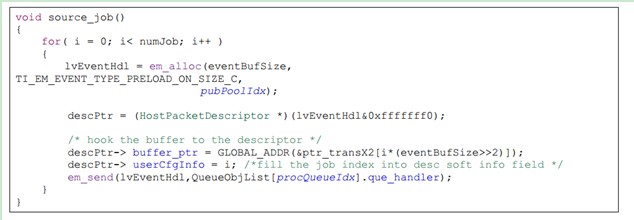
需要注意的是 Event 产生的时候,它被哪一个 execution object 处理还没有确定。因为 execution object 只是和 queue 关联的。当把 event 发送到一个 queue 的时候,负责处理 event 的 execution object 就确定了。所以在调用 em_send()发送 event 到 queue 的时候参数之一就是要发送到的queue 的 handler。
2.2.4 运行和 exit
如前所述,“矩阵乘 event”是通过 proc queue 发给 scheduler 的,所以它被 proc queue 映射到mat_mpy calc 这个 execution object 上。Dispatcher 收到这个 event 后就调用“mat_mpy calc”对应的 receiver 函数计算矩阵相乘。因为 proc queue 所属的 queue group 是映射到所有 DSP 核的,所以 128 个“矩阵乘 event”是在所有核上并行处理的。每个核处理完 event 后就把它释放回global free pool。这样这个 event 又成为一个 free 的 event。
如 2.2.3 节所述,主核可以通过查询 global free pool 的描述符个数是否恢复来判断是否所有“矩阵乘 event”已经处理完。
当所有“矩阵乘 event”处理完后,主核再产生 8 个“exit event”发送到 exit queue。理论上scheduler 可以把 exit job 调度给任意一个核,而不会保证每个核一个 exit job。所以 exit job 中的处理比较特殊。exit job 的 receiver 函数直接执行系统调用 exit(0)。这样就不会返回到 Dispatcher,也不会再发出 prefetch command。而另一方面,scheduler 是在收到 DSP 核的 prefetch command 以后才把 event 调度给这个核的。这个机制保证了每个核收到且仅收到一个“exit event”。
在 exit job 的 receiver 函数中,主核执行的分支稍有差异。主核需要先做完结果的校验再执行系统调用 exit(0)。所以在板上运行是会观察到其他核很快(小于 1s)就从 run 状态转换到 abort 状态,而主核保持 run 了很长时间(大约 50s)才进入 abort 状态。原因是:在主核上执行结果验证工作时产生校验结果的函数计算耗时比较长。
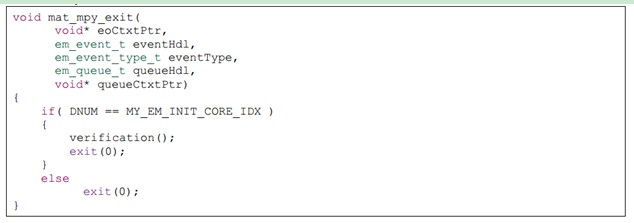
下面是 exit job 的 receiver 函数的代码主干:
2.3 基于 OpenEM 的大矩阵乘性能测试结果
2.3.1 算法代码和 cycle 数的理论极限
设 r1 是 X 矩阵的行数,c1 是 X 矩阵的列数,c2 是 Y 矩阵的列数。在我们的演示用例中 r1 =100, c1 = 2048, c2 = 2048。如前所述,Receiver 函数要计算 100*2048 × 2048*16 的矩阵乘,对应下面的伪代码:

循环内核是 4 个 cycle。 如果只考虑循环内核消耗的 cycle 数,计算 100*2048 × 2048*16 的矩阵乘需要的 cycle 数是 100/2*16/2*2048/4*4 = 819,200 cycle。整个 X*Y=Z 包括计算 128 个这样的矩阵乘。所以总的 cycle 数是 819,200*128 = 104,857,600 cycles。在 1Ghz 的 C66 核上这相当于104.8ms。但是我们的上述理论计算没有考虑循环的前后缀消耗的 cycle 数,也没有考虑 cache miss stall 的等待时间。在 6678EVM 板的单个 DSP 核上实测,计算 X*Y=Z 消耗的实际时间是190,574,214 cycles。相当于 190ms。
2.3.2 基于 OpenEM 的性能测试结果
基于 OpenEM的演示用例实现过程中,DSP 代码中嵌入了少量测试代码收集运行的 cycle 信息。每个核把自己处理每个 event 的起始和结束时间记录在内存(我们通过一个全局 timer 来保证所有DSP 核记录的时间戳在时间轴上是同步的)。这些时间戳用 CCS 存到主机做后处理分析。通过分析,我们可以得到 8 个 DSP 核并行处理消耗的时间。还可以分析每个 DSP 核的忙/闲区间。
测试结果是,从第一个 event 开始处理到最后一个 event 处理完,总时间是 31,433,438 cycle,也就是 31.4ms。也就是说,通过 OpenEM把单 DSP 核的工作负载平衡到 8 个 DSP 核上能达到的DSP 核利用率是 190,574,214/(31,433,438*8)= 76%。
通过对时间戳的处理我们得到下面的运行图,“-”表示 receiver 函数处理 event 的区间,本文称之为有效时间。“#”表示 receiver 之外的区间(也就是代码在 dispatcher 中执行的区间),本文称之为调度开销。每个“-”和“#”刻度表示 100,000 CPU cycle。

从上面的执行图看,调度开销不小,占了大约 15~20%的时间。但是这只是表面的现象。实际上,调度开销的大部分时间里,Dispatcher 是在查询 hardware queue,等待新的 event。这是因为preload 没能及时完成导致的。因为同时给 8 个核做 preload 需要很大的数据搬移的流量。根据以往的测试结果。使用 QMSS 的 packet DMA 从 DDR3 输入数据到 local L2 的流量大约是 4G bytes 每秒。那么 preload 8 个 event 总的数据量是 4byte * 2048 rows * 16 columns * 8 core = 1M bytes,需要的时间是 1/4 ms。因为每个“-”和“#”刻度表示 100,000 CPU cycle,运行图中红线长度就代表 preload 8 个 event 的时间,它非常接近 250,000 cycle。理论计算和实际值基本吻合,所以我们认为调度延迟是 packet DMA 的传输流量不足导致的。
我们也测试了不使用 pre-load 的场景。观测到 scheduler 调度一个 event 的延迟大约是 1200 个C66 CPU cycle。但是 DSP 核处理一个 event 的耗时增大到原来的 10 倍。所以,pre-load 虽然会导致 QMSS packet DMA 流量不足成为凸显的瓶颈,但是从总体效率来看还是非常必要的。
细心的读者可能会发现 76% + 20% = 96%,并不是 100%。我们分析时间戳发现,8 个 DSP 核同时运行的场景下,每个核处理一个 100*2048 × 2048*16 的矩阵乘的时间比只有一个 DSP 核运行的场景下的时间稍长。原因是: 我们的演示用例中 X 矩阵和 Z 矩阵是存储在 shared L2 的, 8 个核同时运行就会同时读写这两个 buffer,导致产生 shared L2 的 bank 冲突。 所以性能下降了。
3、总结
OpenEM具有使用简单,功能实用,执行高效的特点。能在 KeyStone 多核 DSP 上实现动态的负载平衡。它一方面提供了强大的功能,另一方面也给应用留出了很大的灵活性。例如,通过让应用初始化 free pool 方便了 buffer 的管理。OpenEM 的现有功能已经能够支持基本的应用。随着版本更新功能还将不断完善。
Reference
Ref[1] ti.openem.white.paper.pdf 位于 OpenEM 安装目录
![[郭天祥十天学会PIC单片机]lesson1-1—PIC单片机简介](/Uploads/2014_12/video/vi4b9a970eb7c588e68e43ad74f603acc6_s.jpg)