引
TI公司低功耗高性能的DSPTMS320VC5410具有3条独立的数据总线和1条程序总线,提供高度并行性,其多通道缓冲串口McBSP(MultichannelBufferedSerialPort)可以很容易地接口数字交换系统中常用的ST-BUS链路,DMA控制器可以最大限度地减少DSP内部CPU的占用时间,片上RAM可以方便地提供程序运行空间和McBSP的收发数据缓冲区,因此本文中采用该DSP实现会议电话功能。
算法设计实现
会议电话的实现可以采用最大值输出法。这种方法是将同一帧内到达的通话各方的话音幅度进行比较,一般是讲话人的幅度最大,找出幅度最大的话音和幅度第二大的话音后将幅度第二大的话音送给讲话人,而将幅度最大的话音送给其他用户。

图1 最大值输出法会议电话示意图
图1是最大值输出法会议电话的示意图。图中是以四方会议为例,A、B、C、D四方的第M帧PCM编码送入TMS320VC5410后在第M+1帧期间进行比较,假定判断出A的话音幅度最大,B的话音幅度第二大,于是在第M+2帧B的话音送给用户A,A的话音送给B、C、D三方用户,A用户听到的是B用户的声音,其他用户听到的是A用户的声音。
图2给出了会议电话的DSP数据处理流程图。

图2 会议电话的DSP数据处理流程图
首先DSP同时启动McBSP的收发端口,当McBSP的接收端口收到ST-BUS链路送来的第M帧对应于某一用户时隙的8bitA律(或m律,下面以我国的A律编码为例)PCM话音数据后,先将其转成13bit线性码,然后在线性码的右端补上3bit的0送给接收寄存器DRR1,这是因为TMS320VC5410是16位的,只能对片上RAM按16bit访问,为提高算法效率,设计中使用了线性码进行话音幅度比较。线性码转换完成后McBSP通知分配给它的接收DMA控制器,此时,DRR1的数据已就绪,接收DMA控制器立即将此16bit数据按照其对应的地址写入接收缓冲区中。我们在DSP的片上RAM中给McBSP的接收和发送端口各分配了2帧的数据缓冲区。为方便软件处理,配置DMA时,在分配给它的数据缓冲区达到半满和全满时,向DSP内的CPU发送中断,因此DMA接收完第M帧话音数据后向CPU发送中断。
当CPU收到DMA中断时,表明DMA已经接收到了第M帧全部时隙的数据,CPU在第M+1帧的期间依据每一个会议电话中与会用户所对应的时隙号,对存于接收数据缓冲区的用户的第M帧话音数据取绝对值后进行幅度大小比较,找到最大的话音和第二大的话音,分别将它们写入第M+2帧与会用户对应的发送数据缓冲区的地址内。
在第M+2帧时发送DMA控制器从它的数据缓冲区内依次读出相应的数据送给McBSP的发送端口,发送端口首先将此线性码语音数据转成A律语音数据,然后完成PCM话音数据发送。
DSP配置
TMS320VC5410有3个McBSP和6个DMA,可以全部用于会议电话的实现。可以将DMA0~2依次分给McBSP0~2的接收端口,DMA3~5依次分给McBSP0~2的发送端口。
片上RAM分配
TMS320VC5410具有8K字16-bit片上双访问RAM(DARAM)和56K字16-bit片上单访问RAM(SARAM)。DARAM由4块组成,每块大小为2K字。每块可以在同一个时钟周期内读两次或者读写各一次,因此适合用于DSP与Host之间的消息缓冲区,故将数据空间的0080h-1FFFh映射为DARAM。SARAM由7块组成,每块大小为8K字。SARAM可以在同一个时钟周期内读一块,写另一块,因此适合用于运行程序区和数据区,程序空间的2000h?FFFh映射为SARAM,数据空间的8000h蠪FFFh映射为SARAM。对于片上RAM的分配见图3,具体分配如下所示:

图3 片上RAM分配示意图
1.0x0080~0x1FFF,DSP与Host的消息缓冲区。
2.0x2000~0x4FFF,DSP程序区,包括目标文件的.text和.cinit段。其中0x2000~0x2080为DSP的中断向量表。
3.0x5000~0x7FFF,DSP数据区,包括DSP文件的.bss和.stack段。
4.0x8000~0x803F,DMA0缓冲区,用于McBSP0的接收。
5.0x8040~0x807F,DMA1缓冲区,用于McBSP1的接收。
6.0x8080~0x80BF,DMA2缓冲区,用于McBSP2的接收。
7.0x80C0~0x80FF,DMA3缓冲区,用于McBSP0的发送。
8.0x8100~0x813F,DMA4缓冲区,用于McBSP1的发送。
9.0x8140~0x817F,DMA5缓冲区,用于McBSP2的发送。
McBSP的配置
McBSP支持2M和8MST-BUS链路,这里我们以4.096M输入时钟的2.048MST-BUS链路为例,见图4ST-BUS链路示意图。McBSP的配置主要涉及以下四个寄存器。
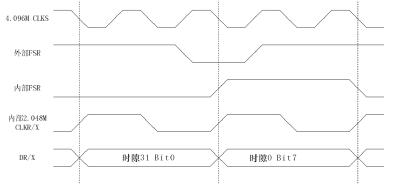
图4 ST-BUS链路示意图
1.引脚控制寄存器(PCR)
CLK(R/X)M=1,由内部采样率发生器产生内部收发时钟CLK(R/X);FS(R/X)P=1,帧同步低有效。
2.接收/发送控制寄存器(RCR/XCR)
(RX)PHASE=0,单相位帧;(R/X)FRLEN1=11111,每帧32字;(R/X)WDLEN1=0,字宽度8-bit;(R/X)COMPAND=11,接收/发送数据使用A律压扩;(R/X)DATDLY=0,无数据延迟。
3.采样率发生寄存器(SRGR)
CLKGDV=1,接收/发送时钟CLK(R/X)的频率是CLKS的1/2;
GSYNC=1,外部接收帧同步FSR同步CLKG;CLKSP=1,CLKS的下降沿产生采样率发生器的CLKG,进而产生CLK(R/X);CLKSM=1,外部时钟CLKS驱动采样率发生器。
4.多通道控制寄存器(MCR1,2)
RMCM=0,接收全部时隙使能。XMCM=00,发送全部时隙使能。
DMA的配置
DMA0~2依次分配给McBSP0~2的接收,DMA3~5依次分配给McBSP0~2的发送。具体配置如下描述:
1.DMA源地址寄存器(DMSRC)
接收DMA的DMSRC存放其对应的McBSP的DRR的地址;
发送DMA的DMSRC存放其对应的数据缓冲区的首地址。
2.DMA目的地址寄存器(DMDST)
接收DMA的DMDST存放其对应的数据缓冲区的首地址;
发送DMA的DMDST存放其对应的McBSP的DXR的地址。
3.DMA通道单元计数寄存器(DMCTR)
DMCTR的值设置了DMA数据缓冲区的大小,取为0x40,即两数据帧所包含的用户时隙数。
4.DMA同步事件和帧计数寄存器(DMSFC)
DSYN[3:0]=0001,同步事件为McBSP0的接收事件REVT0;
DBLW=0,单字模式,每一项是16bit。
5.DMA传输模式控制寄存器(DMMCR)
AUTOINIT=0,禁止自动初始化;DMA0的DINM=1,IMOD=1,DMA的缓冲区半满和全满时产生中断;
DMA1~5的DIMM=0,IMOD=X,不产生DMA中断;
CTMOD=1,DMA工作于ABU模式;
DMA0~2的SIND=000,接收DMA取为源地址不变;
DMA3~5的SIND=001,发送DMA取为源地址递增;
DMS=01,DMA源地址空间为数据空间;
DMA0~2的DIND=000,接收DMA取为目的地址递增;
DMA3~5的DIND=001,发送DMA取为目的地址不变;
DMD=01,DMA目的地址空间为数据空间。
性能计算
会议电话要求在每一帧所产生的DMA中断服务程序中必须完成对所有会议的与会用户的话音处理。我们以运算速度100MIPS的TMS320VC5410为例,该DSP一个指令周期的时间为10ns,因此在ST-BUS一帧125ms内可处理的指令数为125ms/10ns=12500条。由于所有用户均参加同一个会议并且话音幅度按照时隙数递增时DSP的运算处理量最大,因此我们按照上述条件来计算处理能力。假设一个会议发起时,可同时参加的用户数为x,则有如下不等式:
26x+254≤12500
其中254为中断服务程序的公共指令周期数,26为每个用户对应的指令周期数。
由上式推算出x≤471,而三条McBSP链路可同时处理3×32=96个用户(2MST-BUS链路)或者3×128=384个用户(8MST-BUS链路),所以会议电话的最大用户数最终由McBSP决定,即采用2MST-BUS链路时支持96个用户,采用8MST-BUS链路时支持384个用户。
使用汇编语言代码效率高,程序执行速度快。上述算法DMA中断服务程序是采用汇编语言来实现的,实践证明该算法是高效的。
结语
本文介绍的基于TMS320VC5410的会议电话解决方案已成功地应用于CDMA系统MSC中,网上实际运行充分验证了该方案具有大容量和高性能价格比的特点。
参考文献:
1.TI,TMS320C54x_DSPFunctionalOverview.
2.TI,TMS320VC5410Fixed-PointDigitalSignalProcessorDataManual.
3.TI,TMS320C54xDSPReferenceSetVolume5:EnhancedPeripherals.
4.TI,TMS320C54xDSPReferenceSetVolume1:CPUandPeripherals.
5.MITEL,MT9042CMultitrunkSystemSynchronizer.