引言
语音识别技术的目的是使机器能理解人类语言,最终使人机通信成为现实。在过去几十年,自动语音识别(AutomaticSpeech Recognition,ASR)技术已经取得了非常重大的进步。
ASR系统已经能从处理像数字之类的小词汇量到广播新闻之类的大词汇量。然而针对识别效果来说,ASR 系统则相对较差。尤其在会话任务上,自动语音识别系统远不及人类。因此,语音识别技术的应用已成为一个极具竞争性和挑战性的高新技术产业。
随着DSP技术的快速发展及性能不断完善,基于DSP的语音识别算法得到了实现,并且在费用、功耗、速度、精确度和体积等方面有着PC机所不具备的优势,具有广阔的应用前景。
1 系统参数选择
一般情况下,语音识别系统按照不同的角度、不同的应用范围、不同的性能要求有不同的分类方法。针对识别对象不同有孤立词识别、连接词识别、连续语音识别与理解和会话语音识别等。针对识别系统的词汇量有小词汇量语音识别(1~20个词汇)、中词汇量识别(20~1 000个词汇)和大词汇量(1 000以上个词汇)语音识别。针对发音人范围来分,分为特定人语音识别、非特定人语音识别、自适应语音识别。
本文主要研究非特定人小词汇量连续语音实时识别系统。
1.1 语音识别系统
语音识别本质上是一种模式识别的过程,即未知语音的模式与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。语音识别系统一般包括前端处理、特征参数提取、模型训练和识别部分。图1所示是基于模式匹配原理的语音识别系统框图。
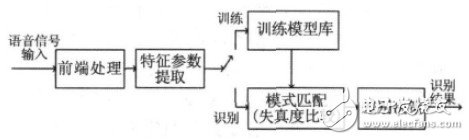
图1 语音识别系统基本框图
1.2 特征参数
语音信号中含有非常丰富的信息,包括影响语音识别的重要信息,也包括对语音识别无关紧要甚至会降低识别率的冗余信息。特征提取则可以去除冗余信息,将能准确表征语音信号特征的声学参数提取出来用于后端的模型建立和匹配,大大减少了存储空间、训练和测试时间。对特定人语音识别来说,希望提取的特征参数尽可能少的反映语义信息,尽可能多的反映说话人的个人信息,而对非特定人语音识别来说,则相反。
现在较常用的特征参数有线性预测参数(LPCC)、线谱对(LSP)参数、Mel频率倒谱参数(MFCC)、感觉加权的线性预测(PLP)参数、动态差分参数和高阶信号谱类特征等,尤其是LPCC和MFCC两种参数最为常用。本文选择MFCC作为特征参数。
1.3 模型训练及模式识别
在识别系统后端,从已知模式中获取用以表征该模式本质特征的模型参数即形成模式库,再将输入的语音提取特征矢量参数后与已建立的声学模型进行相似度比较,同时根据一定的专家知识(如构词规则,语法规则等)和判别规则决策出最终的识别结果。
目前,语音识别所应用模型匹配技术主要有动态时间规整(DTW)、隐马尔可夫模型(HMM)、人工神经元网络(ANN)和支持向量机(SVM)等。DTW 是基本的语音相似性或相异性的一种测量工具,仅仅适合于孤立词语音识别系统中。在解决非特定人、大词汇量、连续语音识别问题时较之HMM 算法相形见绌。HMM 模型是随机过程的数学模型,它用统计方式建立语音信号的动态模型,将声学模型和语言模型融入语音识别搜索算法中,被认为是语音识别中最有效的模型。
然而由Vapnik和co-workers提出来的SVM 基于结构风险最小化准则和非线性和函数,具有更好的泛化能力和分类精确度。目前,SVM 已经成功应用于语音识别与话者识别。
除此之外,Ganapathiraju等人已经将支持向量机成功运用到复杂的大词表非特定人连续语音识别上来。因此本文选择SVM结合VQ完成语音模式识别。
2 系统构建及实现
为了更好地体现DSP的实时性,选择的合适参数相当重要。考虑到DSP的存储容量和实时性要求,本文首先选用Matlab平台对系统进行仿真以比较选取合适的参数。
2.1 Matlab平台上的仿真实现
2.1.1 实验数据的建立
基于Matlab平台,本文实验语音信号在安静的实验室环境下用普通的麦克风通过Windows音频设备和Cool edit软件进行录制,语速一般,音量适中,文件存储格式为wav文件。语音采样频率为8kHz,采样量化精度为16bit,双声道。
由于无调音节有412个,有调音节为1 282个,若采用SVM 对所有音节进行分类,数据量很庞大,故本文选择10个人对6个不固定的连续汉语数字进行发音,每人发音15次,音节切分后共900个样本,其中600个样本作为训练样本集,其余300个样本用于特定人的识别;另外选择5个人对汉语数字0~9发音,每人发音3次,共150个测试样本作为非特定人的识别。此外,以上选取的训练或测试样本均考虑到0~9共10个数字的均匀分布,并且样本类型通过手工标定。
2.1.2 基于Matlab的语音识别系统的仿真及性能分析
首先对语音信号进行了预处理及时域分析:使用H(Z)=1-0.9375z-1 进行预加重处理;同时考虑语音信号的短时平稳性,进行分帧加窗---选用Hamming窗,帧长32ms,帧移是10ms.本文所设计系统为小词汇量的连续语音识别,考虑到训练时的工作量和运算量,选用音节作为基本识别单元。语音特征参数矢量采用12维MFCC、12维一阶MFCC以及每帧的短时归一化能量共25维构成。
本文构造了基于SVM 的连续语音识别系统。系统前端采用MFCC特征参数、并用遗传算法(GA)与矢量量化(VQ)混合算法对其进行聚类得到优化码本,然后将所得码本作为 SVM 模式训练和识别算法的输入,按照相应的准则最终得到识别的结果。语音识别系统流程图如图2所示。
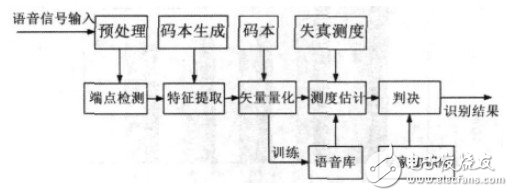
图2 语音识别系统流程图
首先对不同初始种群数的语音识别系统性能进行了分析。表1给出了不同初始种群下的识别系统性能,从表中可以得出,在迭代次数为100、初始种群数为100时,种群最终平均适应度和正识率最高,之后随着初始种群数继续增加,平均适应度和正识率都在降低。综合考虑迭代所需时间和正识率,本文折衷采用初始种群数为80进行系统的仿真和实现。
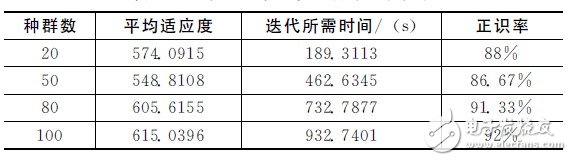
表1 不同初始种群下的识别系统性能
种群数平均适应度迭代所需时间/ (s) 正识率系统设计中考虑到MFCC参数数据量太大,对模型训练和识别的时间有很大的影响,因此选择矢量量化对数据进行分类。矢量量化的关键问题是如何获取VQ码本及码本长度的确定,对此进行了仿真比较。
表2给出了不同VQ算法对正识率的影响比较。由表可以采用种群数为80,码本长度为16,核函数为 RBF,选用的改进遗传算法(GA)时系统的正识率要明显高于LBG和传统GA.LBG容易陷入局部最优,传统GA 具有全局搜索能力,但收敛速度慢。实验证明,改进的GA较好地解决了这两者的问题,收敛速度较快,正识率也有较为明显的提高。
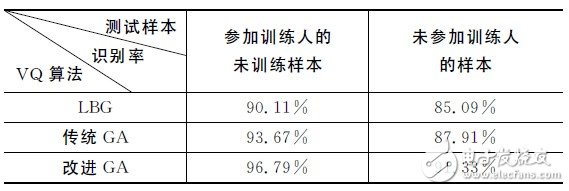
表2 不同VQ算法对正识率的影响比较
在此基础上比较了传统GA和优化后GA对不同码本长度失真测度的影响,如图3所示。由图可知,在码本平均失真测度上,改进的GA比传统GA在整体上明显有所降低,即种群平均适应度更高。从图3还可以发现码本长度为32时失真测度达到最低,但相比码本长度为16时的值减少的并不太明显。 考虑到迭代时间问题,本文所采用的码本长度为16.
不同SVM 核函数对语音识别系统性能也会有影响。SVM分类器的目的是设计一个具有良好性能的分类超平面,以满足在高维特征空间中能通过这个分类超平面区分多类数据样本。
已有文献证明一对一分类器在边界距离上比一对多分类器更精确,故本文采用一对一方法对多类数据样本进行训练和识别。
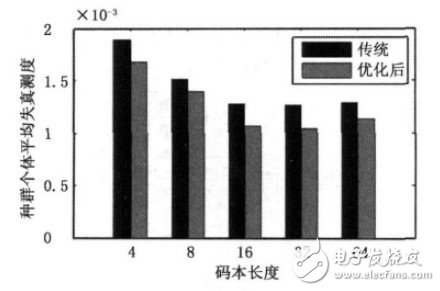
图3 码本长度的失真测度对比
表3给出了针对非特定人的不同SVM 核函数的识别系统性能。表中显示,在取C =3,γ= 125(这里的25为特征参数维数)情况下,尽管核函数为RBF时所需的支持向量数要略高于核函数为Sigmoid时,但系统的正确识别率要明显高于采用其他核函数的系统,因此本文选取RBF作为核函数。
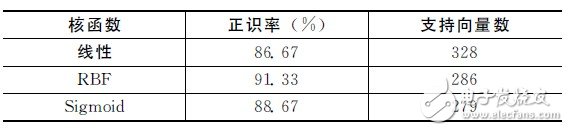
表3 不同SVM 核函数的识别系统性能
通过Matlab仿真分析了不同的矢量量化算法、SVM 核函数和初始种群数对语音识别系统性能产生的影响,为语音识别系统在DSP上的实现提供了参数和模型的选择。
2.2 语音识别系统在DSP上的实现
2.2.1 实验数据的建立
所有语音信号在安静的实验室环境下获得。基于DSP 平台的实时识别实验系统,语音信号通过麦克风输入,使用TLV320AIC23对模拟语音信号进行采样。语音采样频率为8kHz,采样量化精度为 16bit,双声道。考虑到Flash存储空间有限,本文选用自建语音库中900个样本中的40个样本作为训练样本建立模型参数。
2.2.2 语音识别系统的硬件结构
由于语音识别系统算法复杂度较高,同时考虑到实时性,本文选择TI公司的TMS320C6713DSK 作为硬件开发平台。
TMS320C6713DSK是一款低成本独立开发应用板,其最高工作时钟频率可以达到225MHz,且是高性能的浮点数字信号处理器。且带有TLV320AIC23 立体编解码器,8M 字节32bit的SDRAM,512k字节,8bit的非易失性Flash存储器。
本系统针对的是非特定人小词汇量连续语音的识别,硬件结构如图4所示,主要包括语音数据采集模块、数据传输模块、数据处理模块、程序数据存储及Flash引导装载模块、数据存储器RAM 模块及其他相关模块。
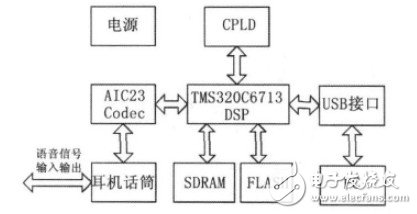
图4 系统硬件结构图
数据采集模块主要采用TLV320AIC23编解码器来实现对语音数据的采集。由AIC23采集的数字信号数据通过McBSP1存入SDRAM 中,数据传输方式为EDMA方式下的McBSP数据传输。数据处理模块是系统的核心模块,用TMS320C6713DSP芯片来完成语音识别算法的实现。训练时,DSP完成语音信号MFCC特征参数的提取、SVM 建模并存入Flash中;识别时,DSP读取待识别语音信号数据并将获得的模型参数与训练模型参数进行比较,进而得到识别结果。
2.2.2 基于DSP的语音识别系统的实现及分析
本系统设计主要涉及到语音数据段、执行代码段、载入Flash的程序段和模型参数段等。在编程中主要以C语言编程为主,配合使用汇编语言,使程序运行效率更高。
实验结果及其性能分析:
训练时,系统上电,加入工程项目。图5所示为读取“12345”的语音时部分主程序、对音节切分后数字“1”提取的语音及其第10帧的MFCC参数、mfcc子程序等。
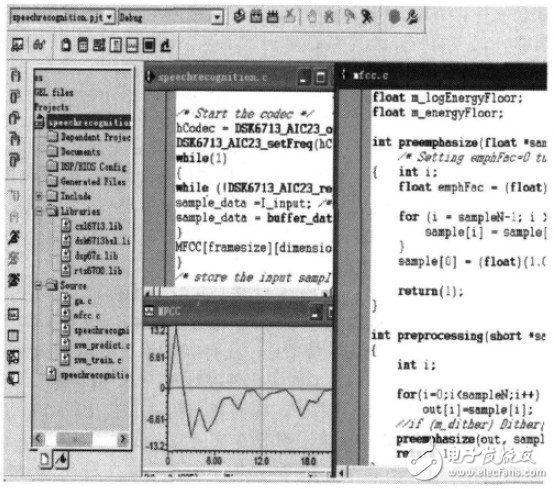
图5 MFCC参数
识别过程中,将存入Flash中的训练模型参数依次读出,与待识别语音信号的MFCC参数比较,最后得到识别结果。
实验中读取20句话,每句话含有6个不同汉语数字的连续语音,通过对其进行测试,得到识别率为76.7%.图6是对音节切分后的数字“2”的识别情况,在STD栏输出了最后识别结果即数字“2”。
3 结论
本文通过在Matlab平台上进行仿真实验选取合适的参数及模型,并将其移植到 TMS320C6713DSK上实现了非特定人小词汇量连续语音识别系统。其中基于TLV320AIC23完成了对语音数据的采集,借助SDRAM 和Flash进行数据存储,并采用短时能量和短时过零率进行语音信号的初步判定,结合起来进行测试,在Windows7操作系统中使用DirectX SDK 9.0b进行视频显示,QR解码程序为自行编制,并与TPS自动测试台集成。连续地采集视频,在计算机显示屏上实时显示影像图的同时进行条码解码定位,结果显示单帧图像的平均解码时间为630ms,使用帧相关算法后,平均解码时间为124ms.
图6为在单码定位时预估未定位条码的结果,q1为已定位码,q2,q3,q4为未定位码,由q1预估q2,q3,q4的结果为图中的加亮框表示,对框区域外扩使其包含完整条码,然后把扩域后的子区域独立出来,作为下一帧条码解码的有效区域以提高图像处理速度。

图5 视频辅助探针定位

图6 单码定位的预估结果
本方法在采用帧相关及位置相关算法后,在普通PC上实现实时视频,并具有如下特点:
a)无需夹具,允许遮挡,允许测试板和探头位置变化;探针和目标点标记同时出现影像图上,直接引导,无需在影像和实板上对照查找,提高探测效率,减小出错机会。
b)QR码定位符含测试板信息,可以在PCB板制作过程中通过丝印到PCB板上,也可以在后期纸制粘贴到PCB板上(但要精确地保证每块板上的QR码位置相同),允许同一板面任意多定位码,以区分不同PCB板及不同板面,用作PCB加电前预检测,可保证加电安全。