引言
许多嵌入式开发人员对ARMCortex处理器架构颇为熟悉,但很少有人能够对这种流行架构了如指掌,从而可以充分发挥它独特的特性和性能。新型ARM Cortex-M4处理器尤为如此,它拥有引以为豪的增强架构、天生的数字信号处理(DSP)能力和可选的浮点加速器,使精于此道的程序设计人员或硬件工程师可以充分发挥它的优势。本文接下来将就Cortex-M3/M4微控制器(MCU)的一些更有趣的(但经常遭到忽视的)特性展开详细的论述。
大部分采用Cortex-M3/M4 MCU的目标应用是便携式的,并且供电电源来自电池或能源收集系统,因此我们所探讨的大部分概念涉及如何减少系统整体能耗的技术。然而,在许多情况下,这些节能技术也是处理器应用设计的有力工具,可提供:
●更符合成本效益的解决方案
●更大的升级和采用新特性的设计冗余
●有助于产品在激烈竞争市场上脱颖而出的性能和特性
ARM Cortex基本介绍
就像Advanced RISC Machines(ARM)公司在20世纪80年代所推出的第一代16位处理器内核一样,ARM Cortex系列以哈佛式RISC架构为基础,采用适度的硅封装工艺获得更高性能,以及代码和内存效率。该架构在过去十年间大有进展,扩展出了三种不同的子系列,以满足特定应用的需求:
●A型系列处理器针对高效能开放应用平台而优化设计。
●R型系列处理器注重提升实时应用的性能和可靠度。
●M型系列处理器特别为采用嵌入式MCU的应用而设计,其性能必须在能源效率和降低解决方案成本之间加以平衡。适用于Cortex M系列的常见应用包括智能电表、人机接口设备、汽车与工业控制系统、白色家电、消费电子产品和医疗器材等。
Cortex-M3对比Cortex-M4
Cortex-M3架构背后的指导思路是设计一种既要满足应用的成本效益又要提供高性能计算和控制1的处理器。类似的应用包括汽车车身系统、工业控制系统和无线网络/传感器产品等。M3系列为32位的ARM处理器架构引进了多项重要特性,包括:
●不可屏蔽式中断
●高度确定性、嵌套、向量式中断
●原子位操作
●可选的存储保护(MPU)
除了绝佳的计算性能,Cortex-M3处理器先进的中断结构还能确保系统迅速响应真实世界的事件,同时仍然提供极低的动态与静态功耗2.

图1:Cortex-M3与M4处理器内核的比较。
Cortex-M3和M4处理器共享许多相同的设计要素,包括先进的片内调试特性,以及执行完整ARM指令集或ARM指令子集(用于THUMB2处理器)的能力。Cortex-M4处理器的指令集具有增强的高效DSP特性库,包括扩展的单周期16/32位乘法累加器(MAC)、双16位MAC指令、优化的8/16位SIMD运算及饱和运算指令。总体来说,M3与M4最显著的差别在于,M4具有可选的单精度(IEEE-754)浮点单元(FPU)。
多项秘诀造就巧妙解决方案
嵌入式设计的成败经常取决于如何在系统性能、能耗和解决方案成本之间找到适当的平衡。许多情况下,开发人员可以采用Cortex-M处理器上的独特特性来优化产品成本或能源需求,同时维持、甚至提升它的性能。例如,Cortex-M内核天生的串行I/O能力能够用于节省能源、简化开发、释放外设以用于其它应用任务。
除了传统的串行调试(Serial Wire Debug)功能之外,基于ARM Cortex-M的MCU还可以通过它的单引脚串行监视器输出(Serial Wire Viewer Output,SWO)3提供指令跟踪接口,如图2所示。这个接口可以直接把“printf格式的”调试信息传递给应用代码。SWO允许调试信息直接在任何标准的IDE中浏览。此外,这些信息也可以用独立的SWO监视器(例如,Segger的J-Link SWO Viewer软件4,或是Silicon Labs的energyAware Commander 4)进行浏览。由于SWO输出内建于内核硬件本身,因此它是Cortex-M内核与生俱来的优点。SWO不占用MCU的任何UART接口,这些接口它们可能早已被分配给了应用。

图2:专用ARM Cortex SWO接口节省I/O引脚并加速调试。
基于SWO的调试还有一个重要的优势在于,它让微控制器在进入最低的休眠模式时,保持调试连接有效,而在大多数情况下,传统的调试连接这时是不能正常工作的。SWO的指令追踪还可以用于跟踪程序计数器,以帮忙IDE统计出程序各项功能所占用的时间。这些统计数字能够与电流测量结合起来,帮助开发人员对设计功耗进行微调。
基于Cortex-M的微控制器供应商正在开始重新认识这项优点,而且有些厂商已经为了这个目的而把功耗模式和电流测量硬件纳入到本身的开发平台。例如,Silicon Labs的EFM32 Gecko MCU入门级和开发级工具包都包含功耗测量输出,并可搭配energyAware Profiler工具6中的程序代码追踪功能。图3显示了如何让设计人员精确定位到哪个程序功能块最耗费能源,并且能够快速调试其它与能源有关的问题。

图3:软硬件工具精确定位耗能最大的功能,无需示波器和万用表,快速排除问题。
智能休眠节省每一微瓦
ARM Cortex-M处理器的Sleep-on-Exit(中断完成时直接进入休眠)是另一项“一箭双雕”的功能,可同时节省CPU周期和能耗。这点在由中断所驱动的应用中格外有用,因为处理器的大部分时间不是在执行中断处理,就是在中断事件之间休眠。在进入中断服务例程(ISR)时,MCU必须花费好几个指令周期把当前线程状态入栈,然后在退出中断处理返回时恢复原有线程状态,即“出栈”。当应用需要处理器在退出ISR后直接进入休眠状态时,传统MCU仍然必须恢复原先存储的状态信息,然后线程代码才能让MCU进入休眠状态。同样地,当下次的中断唤醒MCU时,它的状态必须再次入栈。
而当使能ARM Cortex-M微控制器上的Sleep-on-Exit功能后,MCU就会在中断处理完成后直接进入休眠状态,而不用先返回到原有线程上(见图4)。这会使处理器仍然保持在中断状态,因为消除了唤醒再入栈过程,因而节省下许多宝贵的机器周期。消除入栈出栈过程既节省了时间也节省了能耗,否则电能就会被不必要的指令周期白白消耗,也包括哪些传统MCU在休眠和唤醒之间管理堆栈的代码。而且,当处理器被中止调试请求(Halt Debug Request)唤醒时,出栈过程将会自动进行。
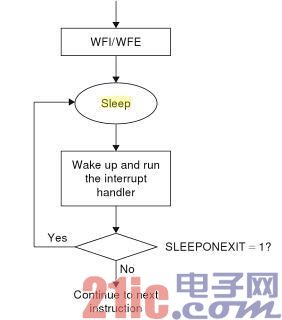

图4:ARM Cortex-M的Sleep-on-Exit功能通过避免不必要的代码执行和减少出栈入栈操作降低功耗。(引自:《The Definitive Guide to the ARM Cortex-M31》)
ARM Cortex-M4运行更快、休眠功耗更低
像许多MCU一样,Cortex-M3/4处理器通常能够采用高时钟速率的方法在中断驱动的应用中节省能耗。如果处理器大部分时间处于休眠状态,这种看似违背直觉但普遍采用的节能策略就会很好,因为运行时间减少所节省的能耗远远大于稍高的操作电流。简单来说,多花10%的电可以省掉20%的时间,总体来说是节能了。
这种技术可以应用在任何Cortex-M系列的处理器上,而涉及密集运算任务的应用也能从Cortex-M4处理器的额外能力中受益。它的单周期DSP指令和可选的浮点加速器能大大减少诸如数字信号处理、过滤、分析或波形合成等功能所需要的执行周期数。
一些应用仅仅需要DSP处理能力。例如,有些安全系统采用一种以声学分析来感测玻璃破损的装置。玻璃破损时会发出一连串独特的声音和振动,并且在玻璃特有的固有频率时达到最大,在这个例子中是13kHz。大多数采用传感器接口的系统只有在所监测的频率被监测到时,才唤醒处理器。但是当设计中使用带DSP功能的Cortex-M4时就能额外节能,因为它在执行实际的玻璃破损分析时比软件解决方案更快。
甚至,这些使用基于M4微控制器的应用可以更加节能,因为MCU中所包含的高级休眠模式和自治外设可以在CPU休眠时执行许多日程任务。例如,以Cortex-M4为内核的Wonder Gecko MCU7具有五种不同的低功耗模式,包括20nA的关机状态和950nA的深度休眠模式(实时时钟有效、RAM和寄存器内容保持、使能掉电检测)。
上面提及的节能特性也能带来其它优势。例如,在超音波/声学水表之类的应用中,它们必须在小电池供电下运行多年,需要MCU尽可能长的保持在休眠状态。除了有助于减少MCU唤醒时间之外,Cortex-4 DSP和浮点算术指令也能使用成熟的滤波功能从廉价声学传感器输出中获得所需的信息,从而避免采用昂贵的超声波流量传感器。在这个应用实例中,Wonder Gecko MCU的外设还能够作为模拟状态机提供额外的能量节省,它仅仅在需要时才唤醒Cortex-M4处理器。
结论
虽然并不完备,但这些林林总总的秘诀与妙方应该能让各位产生好的思路,可以在下一次设计中充分利用Cortex-M系列中一些较不为人知的特性所带来的好处。为了发挥ARM Cortex-M系列的这些和其它重要功能,可参考本文末段的参考资料,它们提供了所需的更多细节。
此外,如何通过选择搭配有合适I/O、加速器和其它先进外设的ARM MCU来改善设计性能、功耗和解决方案成本,来自Silicon Labs的EFM32 Gecko和Wonder Gecko MCU系列产品提供了极佳范例。