摘要:数据挖掘是从存放在数据库、数据仓库或其他信息库中的大量数据中挖掘有用知识的过程,它是一个新兴的边缘学科,其应用领域非常广泛,并且具有良好的应用前景。课题使用JAVA语言、ORM数据访问接口和XML技术设计了跨平台运行、多线程并发处理、架构灵活、支持增量同步更新的数据挖掘系统模型ARFDW和实现方案。
0 引言
数据挖掘从20世纪80年代提出到现在,不过短短20多年的时间,但其应用已非常广泛,不仅用于科研领域,在商业领域的应用也毫不逊色,尤其是用于银行、电信、保险、交通、零售(如超级市场)等领域。数据挖掘在医学领域的应用也有着广泛的前景。在医学领域存在着大量的数据,包括病人病史、诊断、检验、和治疗的临床信息,药品管理信息,医院管理信息等。数据挖掘应用到医学领域,对医学数据进行分析,提取隐含的有价值的信息能够促进医院管理者作出明智决策、医生对病人的正确诊断和治疗。这对促进人类健康、保持健康的生活质量都有积极的意义。
1 基于关联规则数据挖掘技术分析
1.1 数据挖掘概述
1.1.1 数据挖掘的定义
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在的有用信息和知识的过程。这个定义包含几层含义,数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海而皆准的知识,仅需支持特定的发现问题。
1.1.2 数据挖掘的过程
数据挖掘过程一般需要经历数据准备、数据开采、结果表述和解释三个主要步骤。
(1)数据准备。数据准备是数据挖掘中的一个重要步骤,数据准备是否做好将直接影响到数据挖掘的效率、准确度以及最终模式的有效性。这个阶段又可以进一步分为三个子步骤:数据集成、数据选择、数据预处理。
(2)数据开采。数据开采阶段选定某个特定的数据挖掘算法(如关联规则、分类、回归、聚类等算法),用于搜索数据中的模式。这是数据挖掘过程中最关键的一步,也是技术难点。
(3)结果表述和解释。根据最终用户的决策目的,对提取的信息进行分析,把最有价值的信息区分出来,并且通过决策支持工具提交给决策者。因此,这一步骤的任务不仅是把结果表达出来,还要对信息进行过滤处理。如果不能令决策者满意,需要重复以上的数据挖掘过程。
1.2 关联规则概述
给定一个事务(交易)数据库,人们往往希望发现事务中的关联事实,即事务中一些项目的出现必定隐含着同次事务中其他项目的出现,这是关联规则的一个简单的描述。
设I ={t1,t2 ,-,tm} 是由m 个不同项目组成的集合,D 是交易数据库(交易数据库又称事务数据库),其中每一个交易或事务T 是I 中一些项目的集合,即T- I.每一个交易或事务T 都与一个惟一的标识符TID 相联。
对于项目集X-I,如果X-T,则交易或事务T 支持X.
如果X 中有k 个项目,则又称X 为k- 项目集,或X 的长度为k.
关联规则是指形式如下的一种数据隐含关系:X -Y,其中X - I,Y-I,且X-Y = -.
关联规则挖掘的任务是:在给定的交易或事务数据库D 中,发现D 中所有的频繁关联规则。所谓频繁关联规则是指这些规则的支持度、置信度分别不低于用户给定的最小支持度和最小置信度。
2 ARFDW 系统设计与实现
2.1 ARFDW系统框架需求分析
作为通用的数据挖掘框架,ARFDW 要提供对不同操作系统、不同处理平台的支持;对异构数据源的支持;支持多样化、可插拔、可组合的数据转换功能;提供统一的管理和调度功能;处理程序的继承和开放性;要有清晰的框架处理层次以及对元数据的管理等。下面对框架的关键需求进行描述。
2.1.1 建立挖掘主题
系统应该支持挖掘主题的建立。在对被挖掘对象进行充分分析并确定挖掘主题及数据来源后,系统能够通过挖掘主题配置工具来创建挖掘主题及关联维度,并生成相应数据库表及数据记录映射对象。
2.1.2 异构数据源数据抽取
作为通用框架,系统应该支持尽可能多的异构数据源,异构数据源包括不同厂商、不同版本的数据库,不同格式的文本等。如ODBC 数据源、(非ODBC)各种关系型数据库数据源、应用数据、电子商务数据、各种文件格式中数据等;同时提供通用数据访问接口:该接口能够跨平台、网络访问数据,支持在不同类型数据源间建立连接,通过它可以屏蔽各种数据源之间的差异,为后序工作提供一个统一的数据视图。
2.1.3 建立转换规则
由于业务系统的开发一般会有一个较长的时间跨度,这就造成同一种数据在业务系统中可能会有多种完全不同的存储格式。这就要求ETL工具必须对抽取到的数据能进行灵活的计算、合并、拆分等转换操作,系统要能够不断地以插件形式添加转换节点的种类,就可以不断地增强ETL工具的功能,以应付各种各样的数据不一致的问题。
2.1.4 执行定时任务
针对数据源的多样性和可变性,ETL通过对从数据源到目标数据仓库间的映射规则进行元数据级别上的建模,使得整个抽取、转换、装载过程在元数据驱动下能完全自动调度执行,同时也便于维护和扩展。
2.2 ARFDW总体框架设计
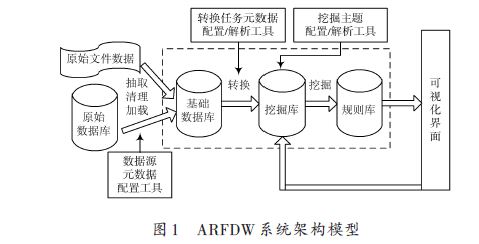
ARFDW 系统架构模型如图1 所示。首先,对被挖掘对象进行充分分析,确定挖掘主题及数据来源,通过挖掘主题配置工具创建挖掘主题及关联维度,并生成相应数据库表及数据记录映射对象;其次,通过数据源配置工具对等待抽取的数据源数据的相关连接格式参数进行配置,数据源配置好后系统会将输入的数据通过数据对象化工具转换为统一的XML 描述数据格式,并根据映射在基础数据库中创建数据保存表记录;再次,通过转换任务元数据配置工具生成数据转换规则及对应目标主题,该部分实现需要用到功能节点以及设定任务中各个功能节点的执行流程。配置好的任务将在任务列表中列出,可以手动执行,也可以通过总控调度配置自动执行。数据经过ETL处理后会加载到挖掘库对应的主题中去。最后,通过基于关联规则的挖掘算法对目标数据进行挖掘,并将条件的规则保存到规则库。
2.3 ARFDW框架实现
整个系统框架结构按照分层设计、实现。现对关键层的实现进行逐一描述。
数据持久层采用Hibernate,负责存储、更新、删除数据库记录等。Hibernate是一个用来处理O/R Mapping的持久层框架。技术本质上是一个提供数据库服务的中间件,该中间件屏蔽了不同数据库之间的差异。它的工作原理是通过文件把值对象和数据库表之间建立起一个映射关系,这样,只需要通过操作这些值对象和Hibernate提供的一些基本类,就可以达到使用数据库的目的。
Hibernate 使用数据库和配置信息来为应用程序提供持久化服务(以及持久的对象)。在这里,创建了接口IdaoSupport,该接口定义了所有对数据库进行的原子操作,DaoSupportHibernate3Imp 是其实现类,该类继承了HibernateDaoSupport类,通过调用该类提供的方法来完成对数据库的操作。
业务逻辑层采用Spring.Spring框架是一个分层架构,它的核心提供了一个管理业务对象以及它们之间依赖关系的方法。例如,应用控制反转(IOC),它可以特定一个数据访问对象(DAO)去依赖于某一个数据源。
同时,它允许开发者实现接口并在XML 文件中去定义其实现类。同时为了避免EJB的高度侵入性,实现无侵入性的目标,Spring 大量引入了JAVA 的Reflection 机制,通过动态调用的方式避免硬编码方式的约束,并在此基础上建立了其核心组件BeanFactory,以此作为其依赖注入机制的实现基础。
表示层采用基于MVC模式的Struts框架。MVC(模型-视图-控制)设计模式将WEB层分为三类对象:代表数据的模型(Model)对象,显示模型的视图(View)对象以及响应用户输入、处理业务流程的控制器(Controller)对象。
整个系统处理流程如下:
(1)当系统第一次启动时,应用会根据部署描述文件Web.xml指向的applicationContext.xml中定义的内容初始化数据库连接池、进行O-R Mapping映射、根据IoC实例化业务逻辑类。
(2)操作员登陆时,进行相应的权限验证,如果验证通过,则初始化单例对象(InitSingleton),该对象保存了一些全局实例,用户信息、角色信息、权限信息等。
(3)操作员通过系统界面(JSP)提交业务请求(业务信息保存在FormBean中),并通过struts-config.xml中的描述定位到控制器(Action),业务请求包括:业务编号、当前步骤、执行动作等。
(4)控制器接收用户请求,将FormBean中的信息传递到BO中,同时调用权限验证模块(RightControl)进行操作员权限验证。权限验证接口判断当前用户对于请求的业务是否具有权限(只读、可写),将结果反馈给控制器。
(5)如果验证通过,控制器将根据用户请求信息,调用系统启动时实例化的业务逻辑类进行相应业务处理。
(6)业务处理逻辑对象处理特定业务逻辑,当需要CRUD(即Create、Read、Update、Delete)时,会根据appli-cationContext.xml中通过set方法注入的DAO实例,执行相应的CRUD操作。
(7)业务处理完成后,控制器根据返回结果,将用户页面导向特定JSP,如果有需要,将返回的结果封装成FormBean(与用户界面相对应的JavaBean,其属性与用户界面元素相对应)一并返回特定JSP.
3 结语
课题根据目前国内外数据集成工具暴露出的问题,及目前医生诊疗数据挖掘的现状、技术及特点提出了ARFDW 自适应模型框架的概念。该框架使用JAVA语言、对象持久化技术和XML技术构建出跨平台、多线程并发运行、支持增量数据更新、灵活的数据挖掘系统架构模型,并给出了设计和实现方案。(作者:王珏)