语音识别ASR(Automatic Speech Recognition)系统的实用化研究是近十年语音识别研究的一个主要方向。近年来,消费类电子产品对低成本、高稳健性的语音识别片上系统的需求快速增加,语音识别系统大量地从实验室的PC平台转移到嵌入式设备中。
语音识别技术目前在嵌入式系统中的应用主要为语音命令控制,它使得原本需要手工操作的工作用语音就可以方便地完成。语音命令控制可广泛用于家电语音遥控、玩具、智能仪器及移动电话等便携设备中。使用语音作为人机交互的途径对于使用者来说是最自然的一种方式,同时设备的小型化也要求省略键盘以节省体积。
嵌入式设备通常针对特定应用而设计,只需要对几十个词的命令进行识别,属于小词汇量语音识别系统。因此在语音识别技术的要求不在于大词汇量和连续语音识别,而在于识别的准确性与稳健性。
对于嵌入式系统而言,还有许多其它因素需要考虑。首先是成本,由于成本的限制,一般使用定点DSP,有时甚至只能考虑使用MPU,这意味着算法的复杂度受到限制;其次,嵌入式系统对体积有严格的限制,这就需要一个高度集成的硬件平台,因此,SoC(System on Chip)开始在语音识别领域崭露头角。SoC结构的嵌入式系统大大减少了芯片数量,能够提供高集成度和相对低成本的解决方案,同时也使得系统的可靠性大为提高。
语音识别片上系统是系统级的集成芯片。它不只是把功能复杂的若干个数字逻辑电路放入同一个芯片,做成一个完整的单片数字系统,而且在芯片中还应包括其它类型的电子功能器件,如模拟器件(如ADC/DAC)和存储器。
笔者使用SoC芯片实现了一个稳定、可靠、高性能的嵌入式语音识别系统。包括一套全定点的DHMM和CHMM嵌入式语音识别算法和硬件系统。

1 硬件平台
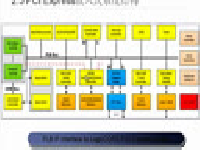
本识别系统是在与Infineon公司合作开发的芯片UniSpeech上实现的。UniSpeech芯片是为语音信号处理开发的专用芯片,采用0.18μm工艺生产。它将双核(DSP MCU)、存储器、模拟处理单元(ADC与DAC)集成在一个芯片中,构成了一种语音处理SoC芯片。这种芯片的设计思想主要是为语音识别和语音压缩编码领域提供一个低成本、高可靠性的硬件平台。
该芯片为语音识别算法提供了相应的存储量和运算能力。包括一个内存控制单元MMU(Memory Management Unit)和104KB的片上RAM。其DSP核为16位定点DSP,运算速度可达到约100MIPS.MCU核是8位增强型8051,每两个时钟周期为一个指令周期,其时钟频率可达到50MHz。
UniSpeech芯片集成了2路8kHz采样12bit精度的ADC和2路8kHz采样11bit的DAC,采样后的数据在芯片内部均按16bit格式保存和处理。对于语音识别领域,这样精度的ADC/DAC已经可以满足应用。ADC/DAC既可以由MCU核控制,也可以由DSP核控制。
2 嵌入式语音识别系统比较
以下就目前基于整词模型的语音识别的主要技术作一比较。
(1)基于DTW(Dynamic Time Warping)和模拟匹配技术的语音识别系统。目前,许多移动电话可以提供简单的语音识别功能,几乎都是甚至DTM和模板匹配技术。
DTW和模板匹配技术直接利用提取的语音特征作为模板,能较好地实现孤立词识别。由于DTW模版匹配的运算量不大,并且限于小词表,一般的应用领域孤立数码、简单命令集、地名或人名集的语音识别。为减少运算量大多数使用的特征是LPCC(Linear Predictive Cepstrum Coefficient)运算。
DTW和模板匹配技术的缺点是只对特定人语音识别有较好的识别性能,并且在使用前需要对所有词条进行训练。这一应用从20世纪90年代就进入成熟期。目前的努力方向是进一步降低成本、提高稳健性(采用双模板)和抗噪性能。
(2)基于隐含马尔科夫模型HMM(Hidden Markov Model)的识别算法。这是Rabiner等人在20世纪80年代引入语音识别领域的一种语音识别算法。该算法通过对大量语音数据进行数据统计,建立识别条的统计模型,然后从待识别语音中提取特征,与这些模型匹配,通过比较匹配分数以获得识别结果。通过大量的语音,就能够获得一个稳健的统计模型,能够适应实际语音中的各种突发情况。因此,HMM算法具有良好的识别性能和抗噪性能。
基于HMM技术的识别系统可用于非特定人,不需要用户事先训练。它的缺点在于统计模型的建立需要依赖一个较大的语音库。这在实际工作中占有很大的工作量。且模型所需要的存储量和匹配计算(包括特征矢量的输出概率计算)的运算量相对较大,通常需要具有一定容量SRAM的DSP才能完成。
在嵌入式语音识别系统中,由于成本和算法复杂度的限制,HMM算法特别CHMM(Continuous density HMM)算法尚未得到广泛的应用。
(3)人工神经网络ANN(Artificial Neural Network)。ANN在语音识别领域的应用是在20世纪80年代中后期发展起来的。其思想是用大量简单的处理单元并行连接构成一种信息处理系统。这种系统可以进行自我更新,且有高度的并行处理及容错能力,因而在认知任务中非常吸引人。但是ANN相对于模式匹配而言,在反映语音的动态特性上存在重大缺陷。单独使用ANN的系统识别性能不高,所以目前ANN通常在多阶段识别中与HMM算法配合使用。
3 基于HMM的语音识别系统
下面详细介绍基于HMM的语音识别系统。首先在UniSpeech芯片上实现了基于DHMM的识别系统,然后又在同一平台上实现了基于CHMM的识别系统。
3.1 前端处理
语音的前端处理主要包括对语音的采样、A/D变换、分帧、特片提取和端点检测。
模拟语音信号的数字化由A/D变换器实现。ADC集成在片内,它的采样频率固定为8kHz。
特征提取基于语音帧,即将语音信号分为有重叠的若干帧,对每一帧提取一次语音特片。由于语音特征的短时平稳性,帧长一般选取20ms左右。在分帧时,前一帧和后一帧的一部分是重叠的,用来体现相邻两帧数据之间的相关性,通常帧移为帧长的1/2。对于本片上系统,为了方便做FFT,采用的帧长为256点(32ms),帧移为128点(16ms)。
特征的选择需要综合考虑存储量的限制和识别性能的要求。在DHMM系统中,使用24维特征矢量,包括12维MFCC(Mel Frequency Cepstrum Coefficient)和12维一阶差分MFCC;在CHMM系统中,在DHMM系统的基础上增加了归一化能量、一阶差分能量和二阶差分能量3维特征,构成27维特征矢量。对MFCC和能量分别使用了倒谱均值减CMS(Cepstrum Mean Subtraction)和能量归一化ENM(Energy Normalization)的处理方法提高特征的稳健性。
3.2 声学模型
在HMM模型中,首先定义了一系列有限的状态S1…SN,系统在每一个离散时刻n只能处在这些状态当中的某一个Xn。在时间起点n=0时刻,系统依初始概率矢量π处在某一个状态中,即:
πi=P{X0=Si},i=1..N
以后的每一个时刻n,系统所处的状态Xn仅与前一时刻系统的状态有关,并且依转移概率矩阵A跳转,即:
系统在任何时刻n所处的状态Xn隐藏在系统内部,并不为外界所见,外界只能得到系统在该状态下提供的一个Rq空间随机观察矢量On。On的分布B称为输出概率矩阵,只取决于Xn所处状态:
Pxn=Si{On}=P{On|Si}
因为该系统的状态不为外界所见,因此称之为“稳含马尔科夫模型”,简称HMM。
在识别中使用的随机观察矢量就是从信号中提取的特征矢量。按照随机矢量Qn的概率分布形时,其概率密度函数一般使用混合高斯分布拟合。
其中,M为使用的混合高斯分布的阶数,Cm为各阶高期分布的加权系数。此时的HMM模型为连续HMM模型(Continuous density HMM),简称CHMM模型。在本识别系统中,采用整词模型,每个词条7个状态同,包括首尾各一个静音状态;每个状态使用7阶混合高斯分布拟合。CHMM识别流程如图1所示。
由于CHMM模型的复杂性,也可以假定On的分布是离散的。通常采用分裂式K-Mean算法得到码本,然后对提取的特征矢量根据码本做一次矢量量化VQ(Vector Quantization)。这样特征矢量的概率分布上就简化为一个离散的概率分布矩阵,此时的HMM模型称为离散HMM模型(Discrete density HMM),简称DHMM模型。本DHMM识别系统使用的码本大小为128。DHMM识别流程如图2所示。
DHMM虽然增加了矢量量化这一步骤,但是由于简化了模型的复杂度,从而减少了占用计算量最大的匹配计算。当然,这是以牺牲一定的识别性能为代价。
笔者先后自己的硬件平台上完成了基于DHMM和CHMM的识别系统。通过比较发现,对于嵌入式平台而言,实现CHMM识别系统的关键在于芯片有足够运算太多的增加。因为词条模型存储在ROM中,在匹配计算时是按条读取的。
3.3 识别性能
笔者使用自己的识别算法分别对11词的汉语数码和一个59词的命令词集作了实际识别测试,识别率非常令人满意,如表1所示。
汉语数码识别率
DHMM
CHMM
特征矢量维数
24
27
识别率
93.40%
98.28%
识别速度(11词)
10ms
50ms
模型大小(1个词条)
1.5KB
<5.5KB
码本
6KB
无
对于59词命令词集的识别,还增加了静音模型。由于基线的识别率已经很高,所以静音模型的加入对于识别率的进一步提高作用不大,如表2所示。但静音模型的加入可以降低对端点判断的依赖。这在实际使用中对系统的稳健性有很大的提高。
59词命令词集识别率
浮点
定点
无静音模型
98.59%
98.28%
有静音模型
98.83%
98.55%
可以看到,在硬件能够支持的情况下,CHMM的识别率比DHMM有很大的提高,同时识别速度也完全可以满足使用要求。
目前嵌入式语音识别领域使用HMM模型的还比较少,使用通常限于DHMM。由于集成电路制造技术的发展,目前主流DSP都可以提供100MIPS以上的运算速度,完全可以满足CHMM对计算能力的要求。
笔者在使用SoC芯片的硬件平台上实现了DHMM和CHMM算法。其中定点CHMM语音识别算法在16位定点DSP硬件平台上达到很高的识别率,同时系统资源消耗也比较合理,安全可以替代DHMM算法。非常适合50词以内的命令词识别。以上算法已经在芯片上实现,该方案在家电语音遥控、玩具、PDA、智能仪器以及移动电话等领域内有非常好的应用前景。