随着嵌入式系统应用要求的不断提高, 系统资源的进一步丰富, 系统的复杂程度也不断提高。文件系统在嵌入式操作系统中占据着越来越重要的位置, 因为像数据采集、多媒体应用等这样一类涉及大量数据的存储、加工、转换等, 需要文件系统的支持。
一般来说, 嵌入式系统处理大容量临时数据的有效方法是设计一个内存文件系统存储这些数据。和普通磁盘文件系统相比, 内存文件系统具有存取速度快、可动态改变文件系统大小和数据掉电即丢失的优点, 因此它适用于高速的临时数据处理。Linux 下的Tmpfs、Proc 文件系统以及Freebsd 下的MFS 都是一种内存文件系统。但是, 这些通用操作系统上的内存文件系统不能直接运用到嵌入式系统中, 因此探索了适合嵌入式大容量数据处理的嵌入式内存文件系统的实现。本文阐述了嵌入式内存文件系统的设计要点, 并分析了将其移植到uCOS II操作系统上的主要技术。
1 嵌入式文件系统的建立
嵌入式系统一般都用大容量电子盘( Flash) 做永久存储介质, 这种设备的特性就是数据只能被整块(Block) 地改写, 所以数据需要按照整块存储, 不同的电子盘每块的大小也不同, 如4KB、16KB 等。
在本文设计的系统中, 把文件作为一种无结构的字节序列, 用户任务可以在文件中加入任何内容, 并且以任何方式来处理它们。为了便于管理和提高访问速度, 不设置子目录管理; 文件以“簇” (Cluster) 为单位, 分块存储, 每个簇的大小根据实际系统的电子盘特性固定为整块的大小。本文件系统对文件的主要管理方式为:
(1) 文件的各个属性单独存储在文件信息表(file status table) 中;
(2) 文件数据块用链表来分配和管理, 文件数据块大小可以动态改变, 这样可以避免在系统运行过程中产生大量的碎片;
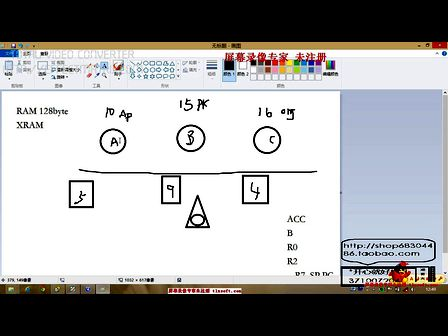
(3) 为了提高文件的读写和查找速度, 设置一个全局散列表(Hash 表) 作为文件的读写及查找入口;每个文件根据其文件名、文件长度计算出一个Hash 值; 然后在Hash 表找到文件对应的Hash 项, 这样就可以读出文件的属性和数据。图1表示了此文件系统在内存中的组织结构。
全局Hash 表 文件状态表 数据块链表 文件数据块

图1 文件的组织结构
每一个存储于此系统中的文件在全局Hash 表都有个对应的入口项。其文件属性和文件名、文件长度、创建时间等存入文件状态表, 文件内容存储在从空闲块链表申请到的数据块中。文件的Hash 表、状态表和数据块通过指针链接起来, 如图2 所示, 下面分别介绍文件系统的Hash 表、状态表和数据块链表。
图2 文件系统中的文件组织方式
1.1Hash 表
Hash 表是整个文件系统读写和查找的入口, 通过计算文件的Hash 值来找到其在Hash 表中的位置, 从而访问文件状态表和数据块。因此文件系统的查找效率主要体现在如何通过文件信息计算其对应的Hash 值以及如何有效地组织Hash 表。每个文件对应8 字节的Hash 值。其中前2 个字节是文件名长度和文件名第一个字节的ASC II码值, 接下来的2 个字节是文件名的16CRC (循环冗余校验编码) , 最后4 个字节是文件名的32CRC 编码。为获得较高的查找效率, 本文采用链地址法组织全局Hash 表, 将全局Hash 表分为两部分: 基本表和溢出表。其基本思想为: 首先分配一个固定大小(设为K项) 的顺序表作为基本表, 每个文件计算得出的Hash 值通过对K取模得到介于0 - K之间的模值。如果此模值在基本表中的对应项没有被占用, 那么该项就作为此文件的Hash 项; 如果此模值在基本表中的对应项已被其它文件占用, 那么就溢出表中申请一个此文件的Hash 项, 并将此Hash 项链接到具有相同模值的链表中。通过这种顺序表和链表相结合的结构, 既不会影响查找速度又不会增加额外存储空间, 从而提高文件系统的查找效率。
1.2 文件状态表
文件状态表用来存放系统中文件的各个属性, 包括文件名称、文件大小、读写标志、创建和修改时间。同时, 为了提高内存空间的利用率, 可以对文件进行选择性压缩存储, 因此文件状态表也包括文件压缩标志, 压缩前的原始大小和压缩后的文件大小。从图2 可以看到, 文件状态表是和Hash 表以及数据块链表连在一起的, 那么一旦定位到文件对应的Hash 项, 就可以对文件状态表进行读写。
1.3 数据块链表
在此文件系统中, 数据内容保存在内存数据块中, 内存数据块的大小可以在建立文件系统时动态设定。数据块链表的作用是对内存块进行管理。由于数据块链表中每一项对应一个内存块, 所以当添加文件时, 系统根据文件大小在链表中动态地申请一定数量的数据块; 当删除文件时, 系统将数据块插入到链表中。
2 内存文件系统在uCOS II中的实现
uCOS II是一个可裁减的实时多任务内核, uCOS 公开了它的实时性内核源码, 同时提供了内存管理的接口和函数, 在其实时内核的基础上进行少量的修改, 便可将此文件系统移植到uCOS 系统中。图3 是文件系统在uCOS 下的初始化流程。
图3 在uCOS II下的初始化流程
为了加载的文件系统跟内核很好地配合工作, 需要在uCOS II内核中增加一些相关数据结构, 并对原来的相关数据结构进行必要的修改。
用户任务对文件进行读写操作时, 系统必须维护当前被用户任务所打开的所有文件, 用文件控制块来登记这些被打开的文件, 其定义如下:
typedef struct //占用6 字节大小
{
OS_FCB *pNext ; //指向下一个控制块
OS_DIRITEM *DirItem; // 文件目录项的内容
INT8U LinkCount ; // 打开此文件的用户数量
INT8U *PathName ; // 文件的绝对路径
} OS_FCB ;
一个用户任务可能同时打开几个文件, 对文件读写时要记录下文件的当前位置, 以便在挂起后重新调度运行时能从这个位置继续进行。用打开文件数据结构来描述:
typedef struct // 占用8 字节
{
OS_OPENFILE *pNext ; // 下一个打开的文件
OS_FCB *pFCB ; //被打开的文件的文件控制块
INT32U Position ; //文件的当前读写位置
} OS_OPENFILE;
修改原有的任务控制块OS_TCB , 增加一个指向打开文件的指针OS_FILE *pFile 。修改系统初始化OSInit () 过程, 增加初始化文件系统OSFileInit() 的调用。
3 结论
本文提出了嵌入式系统下的一种大容量内存文件系统的实现方案, 并从文件的平均查找次数和系统内存利用率等方面对文件系统进行了测试和性能分析。测试结果表明, 此系统具有较快地查找定位速度和较高的内存利用率, 所以本系统能够有效地应用于嵌入式系统, 尤其是那些产生较多临时文件或处理大容量数据的嵌入式系统。