首先说明一下集合的ADT,肯定有包括基本的创建、删除操作。以及某一个元素的插入和删除操作。集合的一个重要特征就是元素的不重复性。这种方式我在实现的过程中通过链表管理一个集合,按照元素的大小进行排列,之所以排列主要是为了方便删除、查找元素的操作。实质上集合对元素的顺序是没有要求的。
集合的交集:是指两个集合元素相同的部分构成的集合。
集合的差集:是指其中一个集合中除去另一个集合相同元素以后剩余的元素构成的集合。
集合的并集:是指两个集合的所有元素构成的集合。
其中需要注意的就是集合的元素是不能重复的,本来我打算采用二叉查找树的方式实现,因为这种树型结构便于快速的查询,但是我采用元素的升序排序就能避免集合中漫无目的的查询操作。毕竟实现二叉查找树也增加了一个指针成员,而且还需要大量的操作。
简要的说明一下我的过程:
基本的集合结构体:
typedef struct linknode
{
struct linknode *next;
int value;
}Node_t, *Node_handle_t;
typedef struct set
{
unsigned int size;
Node_handle_t head;
}Set;
集合的创建,该函数的实现是集合实现的最复杂的一个函数,之所以这么复杂是因为很多的操作都是基于该函数完成的,当然也可以采用更精细的函数来实现,我开始的想法是将元素插入和创建操作合并,都基于一个函数进行操作,但是写完以后发现函数太长,而且比较烂,不够必将还是完成了一些基本的操作。采用了升序存储的方式,主要是为了后续的查找操作,注意链表的更新操作。
bool create_set(Set **sets, int data)
{
Set * temp = (Set *)malloc(sizeof(Set)/sizeof(char));
Node_t *node = NULL;
Node_t *head = NULL;
if(*sets == NULL)
{
temp->size = 0;
temp->head = NULL;
*sets = temp;
node = (Node_t *)malloc(sizeof(Node_t)/sizeof(char));
if(node != NULL)
{
node->next = NULL;
node->value = data;
/*更新集合指针*/
temp->head = node;
temp->size ++;
*sets = temp;
temp = NULL;
return true;
}
}
else/*已经存在部分集合*/
{
/******************************
采用顺序存储的方式插入新的元素
首先查找是否存在值,有不做任何操作
不存在,则按值大小找到合适的位置
******************************/
/*遍历*/
if((*sets)->head != NULL)
{
/*更新表头*/
if((*sets)->head->value > data)
{
node = (Node_t *)malloc(sizeof(Node_t)/sizeof(char));
if(node == NULL)
return false;
node->next = (*sets)->head;
node->value = data;
(*sets)->head = node;
(*sets)->size ++;
return true;
}
else if((*sets)->head->value == data)
{
return true;
}
/*从下一个节点开始*/
head = (*sets)->head;
node = head;
while(head->next != NULL)
{
/*已经存在*/
if(head->next->value == data)
{
return true;
}
/*找到合适的位置,并插入*/
else if(head->next->value > data)
{
node = (Node_t *)malloc(sizeof(Node_t)/sizeof(char));
if(node == NULL)
return false;
node->value = data;
node->next = head->next;
head->next = node;
(*sets)->size ++;
return true;
}
else
{
head = head->next;
}
}
/*说明以上不存在该值*/
node = (Node_t *)malloc(sizeof(Node_t)/sizeof(char));
if(node == NULL)
return false;
node->value = data;
node->next = NULL;
head->next = node;
(*sets)->size ++;
return true;
}
else
{
node = (Node_t *)malloc(sizeof(Node_t)/sizeof(char));
if(node == NULL)
return false;
node->value = data;
node->next = NULL;
(*sets)->head = node;
(*sets)->size ++;
return true;
}
}
return false;
}
查找、删除元素操作,充分利用了前面的升序存储关系。
/***************************************
删除集合中的某个元素
参数: 指向集合指针的指针
需要删除的元素
返回值: 是否删除成功
***************************************/
bool delete_setElement(Set **s, int element)
{
Node_t *head = NULL;
Node_t *temp = NULL;
assert(*s);
head = (*s)->head;
// assert(head);
if(head == NULL)
{
return false;
}
/*表头更新*/
if(head->value == element)
{
temp = head;
if(head->next != NULL)
head = head->next;
else
head = NULL;
(*s)->head = head;
(*s)->size --;
free(temp);
temp = NULL;
return true;
}
while(head->next != NULL)
{
/*删除元素*/
if(head->next->value == element)
{
temp = head->next;
head->next = head->next->next;
free(temp);
(*s)->size --;
temp = NULL;
break;
}
/*不存在当前元素*/
else if(head->next->value > element)
break;
else
head = head->next;
}
return true;
}
/****************************************
判断元素是否在集合中
参数: 集合指针
元素值
返回值: 是否存在
*****************************************/
bool findElement(const Set *s, int Element)
{
// assert(s);
if(s == NULL)
{
return false;
}
Node_t *head = s->head;
while(head != NULL)
{
/*找得到当前值*/
if(head->value == Element)
return true;
/*不存在当前值*/
else if(head->value > Element)
break;
head = head->next;
}
return false;
}
最重要的一个函数,我认为是集合的复制函数,这有点类似在C++中的复制构造或者赋值操作符函数。
/****************************************
实现集合的复制操作
参数: 一个指向被创建集合的指针
一个集合指针
返回: 判断是否成功
****************************************/
bool copySet(Set **dst,const Set *src)
{
Node_t *head = NULL;
assert(src);
head = src->head;
creat_nullset(dst);
while(head != NULL)
{
if(!create_set(dst,head->value))
return false;
head = head->next;
}
return true;
}
最后是集合的三个操作:主要是利用了前面定义的一些函数实现的,所以说前面的问题处理好了,基本的操作就是手到擒来的事。
/****************************************
实现两个集合的并集
参数:
分别是两个Set集合的指针
返回值:
一个集合的指针
*****************************************/
Set * OrSets(const Set * s1, const Set *s2)
{
Set *news = NULL;
const Set *searchset = NULL;
Node_t *head = NULL;
assert(s1 != NULL || s2 != NULL);
if(get_setlength(s1) > get_setlength(s2))
{
copySet(&news,s1);
searchset = s2;
}
else
{
copySet(&news, s2);
searchset = s1;
}
head = searchset->head;
while(head != NULL)
{
if(!create_set(&news, head->value))
break;
head = head->next;
}
return news;
}
/*******************************************
实现两个集合的交集
参数: 两个集合指针
返回值: 新的集合
*******************************************/
Set * AndSets(const Set *s1, const Set *s2)
{
Set *newset = NULL;
const Set *searchset = NULL;
Node_t *head = NULL;
assert(s1 != NULL && s2 != NULL);
if(s1->head == NULL || s2->head == NULL)
{
/*空集合*/
creat_nullset(&newset);
return newset;
}
if(get_setlength(s1) > get_setlength(s2))
{
searchset = s1;
head = s2->head;
}
else
{
searchset = s2;
head = s1->head;
}
while(head != NULL)
{
if(findElement(searchset, head->value))
{
create_set(&newset, head->value);
}
head = head->next;
}
return newset;
}
/*********************************************
集合的差集操作
参数: 两个集合的指针
返回值: 新的集合指针
*********************************************/
Set * XorSets(const Set *s1, const Set *s2)
{
Set *newset = NULL;
Node_t *head = NULL;
assert(s1 != NULL && s2 != NULL);
if(s1->head == NULL)
{
/*空集合*/
creat_nullset(&newset);
return newset;
}
if(s2->head == NULL)
{
copySet(&newset,s1);
return newset;
}
/*newset和s1是相同的*/
copySet(&newset,s1);
head = s1->head;
while(head != NULL)
{
/*如果s2中存在当前元素,删除*/
if(findElement(s2, head->value))
{
delete_setElement(&newset,head->value);
}
head = head->next;
}
return newset;
}
集合打印操作、集合的删除操作
/*********************************************
打印集合
参数: 集合指针
返回: void
**********************************************/
void print_set(const Set *s)
{
Node_t * head = NULL;
int i = 0;
assert(s);
head = s->head;
printf("{ ");
while(head != NULL)
{
++i;
printf("%d ",head->value);
if(i % 5 == 0 && i != 0)
{
i = 0;
// printf("\n");
}
head = head->next;
}
printf("}\n");
}
/*********************************************
删除一个集合
参数: 指向集合指针的指针
返回值: void
**********************************************/
void delete_set(Set **s)
{
Node_t *head = NULL;
Node_t *temp = NULL;
// assert(*s);
if(*s == NULL)
return;
head = (*s)->head;
while(head != NULL)
{
temp = head;
head = head->next;
free(temp);
(*s)->size --;
temp = NULL;
}
free(*s);
*s = NULL;
}
最后是我的测试程序:
/************************************************
主函数
完成各个函数的测试工作
最后需要完成内存的释放
************************************************/
int main()
{
Set* sets1 = NULL;
Set* sets2 = NULL;
Set* sets3 = NULL;
Set* sets4 = NULL;
int i = 0;
int j = 0;
for(i = 0; i < 10; ++ i)
{
if(!create_set(&sets1, i+10))
break;
j = i + 10 - 5;
if(!create_set(&sets2, j))
break;
}
printf("Set1 : ");
print_set(sets1);
printf("Set2 : ");
print_set(sets2);
sets3 = OrSets(sets1,sets2);
printf("Set1 + Set2: ");
print_set(sets3);
sets3 = OrSets(sets2,sets1);
printf("Set2 + Set1: ");
print_set(sets3);
delete_set(&sets3);
sets3 = AndSets(sets1,sets2);
printf("Set1 * Set2: ");
print_set(sets3);
delete_set(&sets3);
sets3 = AndSets(sets2,sets1);
printf("Set2 * Set1: ");
print_set(sets3);
delete_set(&sets3);
sets3 = XorSets(sets1,sets2);
printf("Set1 - Set2: ");
print_set(sets3);
delete_set(&sets3);
// creat_nullset(&sets4);
sets3 = XorSets(sets2,sets1);
printf("Set2 - Set1: ");
print_set(sets3);
delete_set(&sets1);
delete_set(&sets2);
delete_set(&sets3);
delete_set(&sets4);
return 0;
}
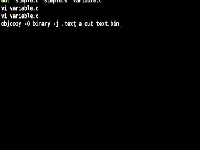
实验效果:

总结:
该实现并没有考虑性能方面,基本上实现了集合的简单操作。后面有时间再想想如何优化查找和删除操作。