导读: 本文提出了一种在Linux平台下开发脸识别系统的方案,通过QT 来开发用户界面,调用OpenCV图像处理库对相机进行采集和处理采集图像,从而实现了人脸检测、身份识别、简单表情识别的功能。
人脸识别的研究可以追溯到上个世纪六、七十年代,经过几十年的曲折发展已日趋成熟,构建人脸识别系统需要用到一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份查找等 。而人脸识别在基于内容的检索、数字视频处理、视频检测等方面有着重要的应用价值,可广泛应用于各类监控场合,因此具有广泛的应用前景。OpenCV是Intel 公司支持的开源计算机视觉库。它轻量级而且高效--由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法,作为一个基本的计算机视觉、图像处理和模式识别的开源项目,OpenCV 可以直接应用于很多领域,其中就包括很多可以应用于人脸识别的算法实现,是作为第二次开发的理想工具。
1 系统组成
本文的人脸识别系统在Linux 操作系统下利用QT库来开发图形界面,以OpenCV 图像处理库为基础,利用库中提供的相关功能函数进行各种处理:通过相机对图像数据进行采集,人脸检测主要是调用已训练好的Haar 分类器来对采集的图像进行模式匹配,检测结果利用PCA 算法可进行人脸图像训练与身份识别,而人脸表情识别则利用了Camshift 跟踪算法和Lucas–Kanade 光流算法。
2 搭建开发环境
采用德国Basler acA640-100gc 相机,PC 机上的操作系统是Fedora 10,并安装编译器GCC4.3,QT 4.5和OpenCV2.2 软件工具包,为了处理视频,编译OpenCV 前需编译FFmpeg,而FFmpeg 还依赖于Xvid库和X264 库。
3 应用系统开发
程序主要流程如图1 所示。
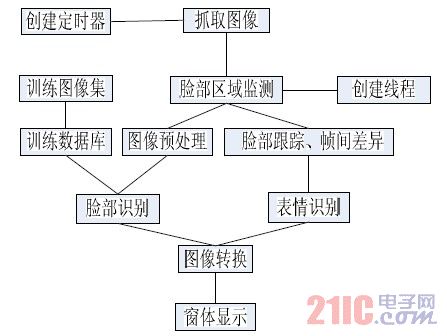
图1 程序流程(visio)
3.1 图像采集
图像采集模块可以通过cvCaptureFromAVI()从本地保存的图像文件或cvCaptureFromCam()从相机得到图像,利用cvSetCaptureProperty()可以对返回的结构进行设置:
IplImage *;CvCapture* cAMEra = 0;
camera = cvCaptureFromCAM( 0 );
cvSetCaptureProperty(camera,
CV_CAP_PROP__WIDTH, 320 );
cvSetCaptureProperty(camera,
CV_CAP_PROP__HEIGHT, 240 );
然后利用start()函数开启QTimer 定时器,每隔一段时间发送信号调用自定义的槽函数,该槽函数用cvGrab()从视频流中抓取一帧图像放入缓存,再利用CvRetrieve()从内部缓存中将帧图像读出用于接下来的处理与显示。在qt 中显示之前,需将IplImage* source 转换为QPixmap 类型。
uchar *qImageBuffer = NULL;
/*根据图像大小分配缓冲区*/
qImageBuffer = (uchar*) malloc(source-》width *
source->height * 4 * sizeof(uchar));
/*将缓冲区指针拷贝到存取Qimage 的指针中*/
uchar *QImagePtr = qImageBuffer;
/* 获取源图像内存指针*/Const uchar*
iplImagePtr=reinterpret_cast/<uchar*》>(source->imageDat
a);
/*通过循环将源图像数据拷贝入缓冲区内*/
for (int y = 0; y < source->height; ++y){
for (int x = 0; x < source->width; ++x){
QImagePtr[0] = iplImagePtr[0];
QImagePtr[1] = iplImagePtr[1];
QImagePtr[2] = iplImagePtr[2];
QImagePtr[3] = 0;
QImagePtr += 4;
iplImagePtr += 3; }
iplImagePtr+=source->widthStep–3*source->width; }
/*将Qimage 转换为Qpixmap*/QPixmap local =
QPixmap::fromImage(QImage(qImageBuffer,source-》wi
dth,source-》height, QImage::Format_RGB32));
/*释放缓冲区*/
free(qImageBuffer);
最后利用QLabel 的setPixmap()函数进行显示。
3.2 图像预处理
由于大部分的脸部检测算法对光照,脸部大小,位置表情等非常敏感, 当检测到脸部后需利用cvCvtcolor()转化为灰度图像,利用cvEqualizeHist()进行直方图归一化处理。
3.3 脸部检测方法
OpenCV采用一种叫做Haar cascade classifier 的人脸检测器,他利用保存在XML 文件中的数据来确定每一个局部搜索图像的位置,先用cvLoad()从文件中加载CvHaarClassifierCascade 变量, 然后利用cvHaarDetectObjects()来进行检测,函数使用针对某目标物体训练的级联分类器在图像中找到包含目标物体的矩形区域,并且将这些区域作为一序列的矩形框返回,最终检测结果保存在cvRect 变量中。
3.4 脸部识别方法
识别步骤及所需函数如图2 所示。

图2 识别步骤(visio)
PCA 方法(即特征脸方法)是M.Turk 和A.Pentland在文献中提出的,该方法的基本思想是将图像向量经过K-L 变换后由高维向量转换为低维向量,并形成低维线性向量空间,即特征子空间,然后将人脸投影到该低维空间,用所得到的投影系数作为识别的特征向量。识别人脸时,只需将待识别样本的投影系数与数据库中目标样本集的投影系数进行比对,以确定与哪一类最近。
PCA 算法分为两步:核心脸数据库生成阶段,即训练阶段以及识别阶段。
3.4.1 训练阶段
主要需要经过如下的几步:
(1) 需要一个训练人脸照片集。
(2) 在训练人脸照片集上计算特征脸,即计算特征值,保存最大特征值所对应的的M 张图片。这M 张图片定义了“特征脸空间”(原空间的一个子空间)。当有新的人脸添加进来时,这个特征脸可以进行更新和重新计算得到。
(3) 在“特征脸空间”上,将要识别的各个个体图片投影到各个轴(特征脸)上,计算得到一个M 维的权重向量。简单而言,就是计算得到各个个体所对应于M 维权重空间的坐标值。
OpenCV 实现为:先用cvLoadImage()载入图片并利用cvCvtcolor()转换为灰度图片,建立自定义的迭代标准CvTermCriteria,调用cvCalcEigenObjects()进行PCA 操作,计算出的Eigenface 都存放在向量组成的数组中,利用cvEigenDecomposite()将每一个训练图片投影在PCA 子空间(eigenspace)上,结果保存在矩阵数组中,用cvWrite《datatype》()将训练结果保存至XML文件中。下面图3 为训练得到的部分特征脸图像。

图3 特征脸图像
3.4.2 身份识别阶段
在识别新的人脸图片时,具体的操作方法流程如下:
(1) 基于前面得到的M 个特征脸,将新采集的图片投影到各个特征脸,计算得到一个权重集合(权重向量)。
(2) 判断新图片是否是一幅人脸图像,即通过判断图像是否足够靠近人脸空间。
(3) 如果是人脸图像,则根据前面计算的权重集合(权重向量),利用权重模式将这个人脸分类划归到初始时计算得到的各个个体或者是成为一个新 的个体照片。简单而言,就是计算新权重到原来各个个体权重的距离,选择最近的,认为是识别成这个个体;如果最近的距离超出阈值,则认为是一个新的个体。
(4) 更新特征脸或者是权重模式。
(5) 如果一个未知的人脸,出现了很多次,也就意味着,对这个人脸没有记录,那么计算它的特征权重(向量),然后将其添加到已知人脸中[6]。
OpenCV 实现调用cvRead《datatype》()加载训练结果XML 文件,调cvEigenDecomposite()将采集图片映射至PCA 子空间,利用最近距离匹配方法SquaredEuclidean Distance,计算要识别图片同每一个训练结果的距离,找出距离最近的即可。
3.5 脸部表情识别
脸部运动跟踪利用了Camshift 算法,该算法利用目标的颜色直方图模型将图像转换为颜色概率分布图,初始化一个搜索窗的大小和位置,并根据上一帧得到的结果自适应调整搜索窗口的位置和大小, 从而定位出当前图像中目标的中心位置。
Camshift 能有效解决目标变形和遮挡的问题,对系统资源要求不高,时间复杂度低,在简单背景下能够取得良好的跟踪效果。
Camshift 的OpenCV 实现分以下几步:
(1)调用cvCvtColor()将色彩空间转化到HSI 空间,调用cvSplit()获得其中的H 分量。
(2) 调用cvCreateHist()计算H 分量的直方图,即1D 直方图。
(3) 调用cvCalcBackProject()计算Back Projection.
(4) 调用cvCamShift()输出新的Search Window 的位置和面积。
我们利用光流算法评估了两帧图像的之间的变化,Lucas–Kanade 光流算法是一种两帧差分的光流估计算法。它计算两帧在时间t 到t +δt 之间每个每个像素点位置的移动。是基于图像信号的泰勒级数,就是对于空间和时间坐标使用偏导数。
首先要用到shi-Tomasi 算法,该算法主要用于提取特征点,即图中哪些是我们感兴趣需要跟踪的点,对应函数为cvGoodFeaturesToTrack(),可以自定义第一帧特征点的数目,函数将输出所找到特征值。接下来是cvCalcOpticalFlowPyrLK 函数, 实现了金字塔中Lucas-Kanade 光流计算的稀疏迭代版本。 它根据给出的前一帧特征点坐标计算当前视频帧上的特征点坐标。输入参数包括跟踪图像的前一帧和当前帧,以及上面函数输出的前一帧图像特征值,自定义的迭代标准,输出所找到的当前帧的特征值点。这些点可以确定面部局部区域的特征 如眼部,鼻子高度与宽度,嘴部两侧与底部的夹角等等,利用与前一帧的特征比较,可得出反应脸部动态变化的参数,这些数据可以与脸部的一些简单表情相关联。下面图4 为跟踪眼睛上下眨动的图像。
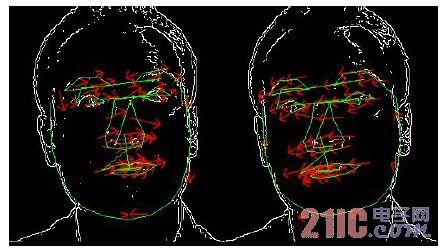
图4 跟踪眼部上下眨动图像
4 总结
本文以OpenCV 图像处理库为核心,以QT 库所提供的界面框架为基础,提出了人脸识别系统设计方案,实验证明本方案具有较好的实用性,可移植性。但仍有许多不足之处,如身份与表情识别部分可以通过引入神经网络或支持向量机SVM 进行分类,可以使识别准确率与识别种类数得到提高,这些也是后续工作中步需要改进的。