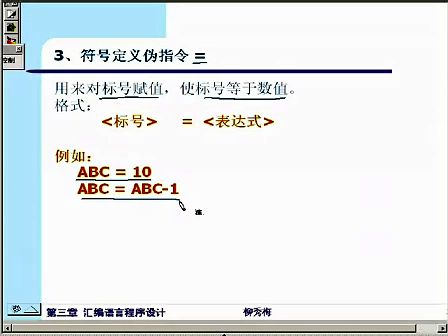
子程序名称恰当
一个恰当的子程序名称应该清楚地描述出于程序所作的每一件事。以下是给子程序有效命名的指导方针:
对于过程的名字,可以用一个较强的动词带目标的形式。一个带有函数的过程往往是对某一目标进行操作。名字应该反映出这个过程是干什么的,而对某一目标进行操作则意味着我们应该使用动宾词组。比如,PrintReport(),Checkotderlnfo()等,都是关于过程的比较恰当的名字。
在面向对象的语言中,不必加上对象名,因为对象本身在被调用时就已经出现了。这时可求助于诸如RePort.Print(),Orderlnfo.Check()和MonthlyRevenu.Cafe()等名字。而像RePort.PrintRePort这类名字则是冗余的。
对于函数名字,可以使用返回值的描述。一个函数返回到一个值,函数应该用它所返回的值命名,例如Cos(),PrinterReady(),CurrentPenColor()等等都是不错的函数名字,因为它精确地描述了函数将返回什么。
避免无意义或者模棱两可的动词。有些动词很灵活,可以有任何意义,比如HandleCalculation(),ProcessInput()等于程序名词并没有告诉你它是作什么的。这些名字至多告诉你,它们正在进行一些与计算或输入等有关的处理。当然,有特定技术情形下使用“handle”等词是个例外。
有时,子程序的唯一问题就是它的名字太模糊了,而子程序本身的设计可能是很好的。假如用FormatAndPrintOutput() 来代替HandleOutPut() ,这是一个很不错的名字。
在有些情况下,所用的动词意义模糊是由于子程序本身要做的工作太模糊。子程序存在着功能不清的缺陷,其名字模糊只不过是个标志而已。假如是这种情况,最好的解决办法是重新构造这个子程序,弄清它们的功能,从而使它们有一个清楚的、精确描述其功能的名字。
描述子程序所做的一切。在子程序名字中,应描述所有输出结果及其附加结果。假如一个子程序用于计算报告总数,并设置一个全局变量来表示所有的数据都已预备好了,正等待打印,那么,ComputeReportTotal()就不是一个充分的名字了。而ComputeReportTotalAndSetPrintingReadyVar()又是一个太长而且太愚蠢的命名。假如子程序带有附加结果,那必然会产生许多又长又臭的名字。解决的办法不应该是使用描述不足名字,而是采用直接实现每件事的原则来编程,从而避免程序带有附加结果。
名字的长度要符合需要。研究表明,变量名称的最佳长度是9到15个字母,子程序往往比变量要复杂,因而其名字也要长些。南安普敦大学的MichaelRees 认为恰当的长度是20 到35个字母。但是,一般来说15 到20 个字母可能更现实一些,不过有些名称可能有时要比它长。
建立用于通用操作的约定。在某些系统中,区分各种不同的操作是非常重要的。而命名约定可能是区分这些操作最简单也是最可靠的方法。比如,在开发0S/2 显示治理程序时,假如子程序是关于直接输入的,就在其名称前面加一个“Get”前缀,假如是非直接输入的则加“Query”前缀,这样,返回当前输入字符的GetlnputChar()将清除输入缓冲区.而同样是返回当前输入字符的QuerylnPutChar()则不清除缓冲区。
对于命名规则,很多书都做过具体的阐述和说明。其中有非常出名的匈牙利命名法,以此为基础,各种语言又派生出多种不同的命名规则,但是在思想上,命名规则假如能让人一眼就把名称代表的意思、功能猜个八九不离十,它就是成功的。上面所说的虽然和你平时接触的规则不完全一样,但它代表的是一种命名的思想,具有很强的通用性。
强内聚性
内聚性指的是在一个子程序中,各种操作之间互相联系的紧密程度。有些程序员喜欢用“强度”一词来代替内聚性,在一个子程序中各种操作之间的联系程度有多强?一个诸如Sin()之类的函数内聚性是很强的,因为整个子程序所从事的工作都是围绕一个函数的。而像SinAndTan()的内聚程度就要低得多了,因为子程序中所进行的是一项以上的工作。强调强相关性的目的是,每一个子程序只需作好一项工作,而不必过分考虑其它任务。
这样作的好处是可以提高可靠性。通过对450个Fortran 子程序的调查表明,50%的强内聚性子程序是没有错误的,而只有18%的弱内聚性子程序才是无错的(Card,carch和Agresti 1986)。
另一项对另外450 个子程序的调查则表明,弱内聚性子程序的出错机会要比强内聚性出错机会高6 倍,而修正成本则要高19 倍(Selby和Basili 1991)。
可取的内聚性
关于内聚性的讨论一般是指几个层次。理解概念要比单纯记住名词重要得多。可以利用这些概念来生成内聚性尽可能强的子程序。
内聚性的想法是由wayne stevens,Glenford Myers和Larry Constantine 等人在1974年发表的一篇论文中提出来的,从那以后,这个想法的某些部分又逐渐得到了完善。以下是一些通常认为是可以接受的一些内聚类型:
功能内聚性。功能内聚性是最强也是最好的一种内聚,当程序执行一项并且仅仅是一项工作时,就是这种内聚性,这种内聚性的例子有: sin(), GetCustomerName(), EraseFile(),CaldoanPayment()和GetIconlocation()等等。当然,这个评价只有在子程序的名称与其实际内容相符时才成立。假如它们同时还作其它工作,那么它们的内聚性就要低得多而且命名也不恰当。
顺序内聚性。顺序内聚性是指在子程序内包含需要按特定顺序进行的、逐步分享数据而又不形成一个完整功能的操作,假设一个子程序包括五个操作:打开文件、读文件、进行两个计算、输出结果、关闭文件。假如这些操作是由两个子程序完成的,DoStep1()打开文件、读文件和计算操作,而DoStep2()则进行输出结果和关闭文件操作。这两个子程序都具有顺序内聚性。因为用这种方式把操作分隔开来,并没有产生出独立的功能。
但是,假如用一个叫作GetFileData()的子程序进行打开文件和读文件的操作,那么这个子程序将具有功能 内聚性。当操作来完成一项功能时,它们就可以形成一个具有功能内聚性的子程序。实际上,假如能用一个很典型的动宾词组来命名一个子程序,那么它往往是功能内聚性,而不是顺序内聚性。给一个顺序内聚性的子程序命名是非常困难的,于是便产生了像Dostep1()这种模棱两可的名字。这往往意味着你需要重新组织和设计子程序,以使它是功能内聚性的。
通讯内聚性。通讯内聚性是在一个子程序中,两个操作只是使用相同数据,而不存在其它任何联系时产生的。比如,在GetNameAndChangePhoneNumber()这个子程序中,假如Name 和PhoneNumber 是放在同一个用户记录中的,那么这个子程序就是通讯内聚性。这个子程序从事的是两项而不是一项工作,因此,它不具备功能内聚性。Name 和PhoneNamber 都存储在用户记录中,不必按照某一特定顺序来读取它们,所以,它也不具备顺序内聚性。
这个意义上的内聚性还是可以接受的。在实际中,一个系统可能需要在读取一个名字的同时变更电话号码。一个含有这类子程序的系统可能有些显得别扭,但仍然很清楚且维护性也不算差,当然从美学角度来说,它与那些只作一项工作的子程序还有一定差距。
临时内聚性。因为同时执行的原因才被放入同一个子程序里,这时产生临时内聚性。典型的例子有;Startup(),CompleteNewEmployee(),Shutdown()等等,有些程序员认为临时内聚性是不可接受的,因为它们有时与拙劣的编程联系在一切,比如,在像Startup()这类子程序中往往含有东拼西凑的杂烩般的代码。
要避免这个问题,可以把临时内聚性子程序设计成一系列工作的组织者。前述的Startup()子程序进行的操作可能包括:读取一个配置文件、初始化一个临时文件、建立内存治理、显示初始化屏幕。要想使它最有效地完成这些任务,可以让这个子程序去调用其它的专门功能的子程序,而不是由它自己直接来完成这些任务。
一个子程序只完成一个基本功能听起来很简单,但是操作起来你可能会因为这样或者那样的原因忽略了对子程序内聚性的关注。其实,你只需要在正式写程序前花一些时间设计好架构、写好头文件和makefile文件。想清楚你的公用函数放在哪里,你的商业规则如何分配提炼,在写程序的时候,花一些时间来一点点整理你的代码。所有这些时间都会为你带来你意想不到的益处。想想你是如何治理你庞大的收藏夹的。
不可取的内聚性
其余类型的内聚性,一般来说都是不可取的。其后果往往是产生一些组织混乱而又难以调试和改进的代码。假如一个子程序具有不良的内聚性,那最好重新创建一个较好的子程序,而不要去试图修补它。知道应该避免什么是非常重要的,以下就是一些不可取的内聚性:
过程内聚性。当子程序中的操作是按某一特定顺序进行的,就是过程内聚性。与顺序内聚性不同,过程内聚性中的顺序操作使用的并不是相同数据。比如,假如用户想按一定的顺序打印报告,而所拥有的子程序是用于打印销售收入、开支、雇员电话表的。那给这个子程序命名是非常困难的,而模棱两可的名字往往代表着某种警告。
逻辑内聚性。当一个子程序中同时含有几个操作,而其中一个操作又被传进来的控制标志所选择时,就产生了逻辑内聚性。之所以称之为逻辑内聚性,是因为这些操作仅仅是因为控制流,或者说“逻辑”的原因才联系到一起的,它们都被包括在一个很大的if或者case语句中,它们之间并没有任何其它逻辑上的联系。
举例来说,一个叫作InputAll()的子程序,程序的输入内容可能是用户名字、雇员时间卡信息或者库存数据,至于到底是其中的哪一个,则由传入子程序的控制标志决定。其余类似的子程序还有ComputeAll(),EditAll(),PrintAll()等等。这类子程序的主要问题是一定要通过传入一个控制标志来决定子程序处理的内容。解决的办法是编写三个不同的子程序,每个子程序只进行其中一个操作。假如这三个子程序中含有公共代码段,那么还应把这段代码放入一个较低层次的子程序中,以供三个子程序调用。并且,把这三个子程序放入一个模块中。
但是,假如一个逻辑内聚性的子程序代码都是一系列if和case语句,并且调用其它子程序,那么这是答应的。在这种情况下,假如程序的唯一功能是调度命令,而它本身并不进行任何处理,那么这可以说是一个不错的设计。对这种子程序的专业叫法是“事物处理中心”,事物处理中心往往被用作基础环境下的事件处理,比如,Apple Macintosh和Microsoft Windows。
偶然内聚性。当同一个子程序中的操作之间无任何联系时,为偶然内聚性。也叫作“无内聚性”。本章开始时所举的Pascal例程,就是偶然内聚性。
以上这些名称并不重要,要学会其中的思想而不是这些名词。写出功能内聚性的子程序几乎总是可能的,因此,只要重视功能内聚性以获取最大的好处就可以了。
偶然内聚性虽然有个好听的名字,但是在程序中它就像是“恶棍”,使你的程序晦涩难懂。