摘要:在C语言编程的过程中,我们经常用到多维数组,指针的加减运算等等。如果我们想把一个二维数组传递给一个函数,为什么不能用“a[][]”这样的形参模式?而把一维数组传递给函数可以用int a[]这样的形式?内核代码中,我们常常能看到,有两个page类型的结果体指针pagea和pageb,那么pageb-pagea数值上等于多少?是地址差还是index的差值?本文主要为你解答这些问题。
本文来源:C语言指针类型、指针大小、指针所指元素大小、指针加减运算
http://blog.csdn.net/trochiluses/article/details/13288651
1.指针类型
在编程中,我们经常使用这样的定义:
?
1
2
3
int *a;
double *dh;
struct student * mystudent;
当提到a、dh、mystudent的时候,我们常说他们是一个指针,潜意识里并没有区分指针类型其实并不是一个类型而是一系列类型的统称。为什么指针类型至关重要呢?因为这涉及到指针所指变量的大小和指针的加减运算。
如果指针a是指向int类型,那么对a进行地址解析的时候,会根据a的类型决定地址解析会解析对应地址内容往后的多少字节。
2.指针大小
所有指针的大小在32位机器上都是4个字节。
3.指针所指元素的大小
有一道经典的体系结构相关的C语言试题:如何判断机器的大小端?
我们都知道,假如有一个int数据a,数值是0x12345678,需要存储到地址100外后的4个字节中,那么从低位到高位,大小端的存储方法如下:
78563412(小端),12345678(大段)。我们是不是可以用char *chp=(char *)&a,然后对chp进行地址解析,(*chp)=?是否能判断机器的大小端呢?
分析:对a取得地址,得到低位地址,然后把这个地址赋值给char *p,对p进行地址解析就能得到地位地址存储的数值,从而判断机器是大还是小端。
4.指针运算
先来看看下面这个程序:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
6 int a[3][3]={
7 [0]={1,2,3 },
8 [1]={4,5,6 },
9 [2]={7,8,9 },
10 };
11 int b[3][3]={
12 [0]={1,2,3 },
13 [1]={4,5,6 },
14 [2]={7,8,9 },
15 };
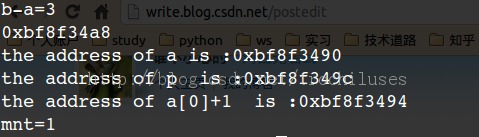
16 printf("b-a=%d\n",b-a );
17 printf("%p\n",a[2]);
18 int (*p)[3]=a+1;
19
20 printf("the address of a is :%p\n",a);
21 printf("the address of p is :%p\n",p);
22 printf("the address of a[0]+1 is :%p\n",a[0]+1);
23
24 int mnt=p-a;
25 printf("mnt=%d",mnt);
26 return 0;
分析这个程序的输出:
首先,a是一个3*3的int数组,那么a是一个指针,指向数组(数组由3个int而不是3*3个int)的指针,很明显b和a的地址相差3*3*4个字节,那么b-a是多少呢?36,9,3,还是1?
分析清楚了这个结果,基本上就明白了指针所指元素大小的意义。让我们来看结果:
总结:b-a的数值,并不等于b,a对应地址算术相减的结果,而是这个结果除以他们对应指针所指元素大小。