优化是一件非常重要的事情。作为一个程序设计者,你肯定希望自己的程序既小又快。DOS时代的许多书中都提到,“某某编译器能够生成非常紧凑的代码”,换言之,编译器会为你把代码尽可能地缩减,如果你能够正确地使用它提供的功能的话。目前,Intel x86体系上流行的C/C++编译器,包括IntelC/C++ Compiler, GNU C/C++Compiler,以及最新的Microsoft和Borland编译器,都能够提供非常紧凑的代码。正确地使用这些编译器,则可以得到性能足够好的代码。
但是,机器目前还不能像人那样做富于创造性的事情。因而,有些时候我们可能会不得不手工来做一些事情。
使用汇编语言优化代码是一件困难,而且技巧性很强的工作。很多编译器能够生成为处理器进行过特殊优化处理的代码,一旦进行修改,这些特殊优化可能就会被破坏而失效。因此,在你决定使用自己的汇编代码之前,一定要测试一下,到底是编译器生成的那段代码更好,还是你的更好。
本章中将讨论一些编译器在某些时候会做的事情(从某种意义上说,本章内容更像是计算机专业的基础课中《编译程序设计原理》、《计算机组成原理》、《计算机体系结构》课程中的相关内容)。本章的许多内容和汇编语言程序设计本身关系并不是很紧密,它们多数是在为使用汇编语言进行优化做准备。编译器确实做这些优化,但它并不总是这么做;此外,就编译器的设计本质来说,它确实没有义务这么做——编译器做的是等义变换,而不是等效变换。考虑下面的代码:
// 程序段1
int gaussianSum(){
int i, j=0;
for(i=0; i<100; i++) j+=i;
return j;
}
好的,首先,绝大多数编译器恐怕不会自作主张地把它“篡改”为
// 程序段1(改进1)
int gaussianSum(){
int i, j=0;
for(i=1; i<100; i++) j+=i;
return j;
}
多数(但确实不是全部)编译器也不会把它改为
// 程序段1(改进2)
inline int gaussianSum(){
return 5050;
}
这两个修改版本都不同于原先程序的语义。首先我们看到,让i从0开始是没有必要的,因为j+=i时,i=0不会做任何有用的事情;然后是,实际上没有必要每一次都计算1+...+100的和——它可以被预先计算,并在需要的时候返回。
这个例子也许并不恰当(估计没人会写出最初版本那样的代码),但这种实践在程序设计中确实可能出现。我们把改进2称为编译时表达式预先计算,而把改进1成为循环强度削减。
然而,一些新的编译器的确会进行这两种优化。不过别慌,看看下面的代码:
// 程序段2
int GetFactorial(int k){
int i, j=1;
if((k<0) || (k>=10)) return -1;
if((k<=1)) return 1
for(i=1; i<k; i++) j*=i;
return j;
}
程序采用的是一个时间复杂度为O(n)的算法,不过,我们可以把他轻易地改为O(1)的算法:
// 程序段2 (非规范改进)
int GetFactorial(int k){
int i, j=1;
static const int FractorialTable[]={1, 1, 2, 6, 24,
120, 720, 5040, 40320, 362880, 3628800};
if((k<0) || (k>=10))return -1;
return FractorialTable[k];
}
这是一个典型的以空间换时间的做法。通用的编译器不会这么做——因为它没有办法在编译时确定你是不是要这么改。可以说,如果编译器真的这样做的话,那将是一件可怕的事情,因为那时候你将很难知道编译器生成的代码和自己想的到底有多大的差距。
当然,这类优化超出了本文的范围——基本上,我把它们归入“算法优化”,而不是“程序优化”一类。类似的优化过程需要程序设计人员对于程序逻辑非常深入地了解和全盘的掌握,同时,也需要有丰富的算法知识。
自然,如果你希望自己的程序性能有大幅度的提升,那么首先应该做的是算法优化。例如,把一个O(n2)的算法替换为一个O(n)的算法,则程序的性能提升将远远超过对于个别语句的修改。此外,一个已经改写为汇编语言的程序,如果要再在算法上作大幅度的修改,其工作量将和重写相当。因此,在决定使用汇编语言进行优化之前,必须首先考虑算法优化。但假如已经是最优的算法,程序运行速度还是不够快怎么办呢?
好的,现在,假定你已经使用了已知最好的算法,决定把它交给编译器,让我们来看看编译器会为我们做什么,以及我们是否有机会插手此事,做得更好。
5.1 循环优化:强度削减和代码外提
比较新的编译器在编译时会自动把下面的代码:
for(i=0; i<10; i++){
j = i;
k = j + i;
}
至少变换为
for(i=0; i<10; i++);
j=i; k=j+i;
甚至
j=i=10; k=20;
当然,真正的编译器实际上是在中间代码层次作这件事情。
原理 如果数据项的某个中间值(程序执行过程中的计算结果)在使用之前被另一中间值覆盖,则相关计算不必进行。
也许有人会问,编译器不是都给咱们做了吗,管它做什么?注意,这里说的只是编译系统中优化部分的基本设计。不仅在从源代码到中间代码的过程中存在优化问题,而且编译器生成的最终的机器语言(汇编)代码同样存在类似的问题。目前,几乎所有的编译器在最终生成代码的过程中都有或多或少的瑕疵,这些瑕疵目前只能依靠手工修改代码来解决。
5.2 局部优化:表达式预计算和子表达式提取
表达式预先计算非常简单,就是在编译时尽可能地计算程序中需要计算的东西。例如,你可以毫不犹豫地写出下面的代码:
const unsigned long nGiga = 1024L * 1024L * 1024L;
而不必担心程序每次执行这个语句时作两遍乘法,因为编译器会自动地把它改为
const unsigned long nGiga = 1073741824L;
而不是傻乎乎地让计算机在执行到这个初始化赋值语句的时候才计算。当然,如果你愿意在上面的代码中掺上一些变量的话,编译器同样会把常数部分先行计算,并拿到结果。
表达式预计算并不会让程序性能有飞跃性的提升,但确实减少了运行时的计算强度。除此之外,绝大多数编译器会把下面的代码:
// [假设此时b, c, d, e, f, g, h都有一个确定的非零整数值,并且,
// a[]为一个包括5个整数元素的数组,其下标为0到4]
a[0] = b*c;
a[1] = b+c;
a[2] = d*e;
a[3] = b*d + c*d;
a[4] = b*d*e + c*d*e;
优化为(再次强调,编译器实际上是在中间代码的层次,而不是源代码层次做这件事情!):
// [假设此时b, c, d, e, f, g, h都有一个确定的非零整数值,并且,
// a[]为一个包括5个整数元素的数组,其下标为0到4]
a[0] = b*c;
a[1] = b+c;
a[2] = d*e;
a[3] = a[1] * d;
a[4] = a[3] * e;
更进一步,在实际代码生成过程中,一些编译器还会对上述语句的次序进行调整,以使其运行效率更高。例如,将语句调整为下面的次序:
// [假设此时b, c, d, e, f, g, h都有一个确定的非零整数值,并且,
// a[]为一个包括5个整数元素的数组,其下标为0到4]
a[0] = b*c;
a[1] = b+c;
a[3] = a[1] * d;
a[4] = a[3] * e;
a[2] = d*e;
在某些体系结构中,刚刚计算完的a[1]可以放到寄存器中,以提高实际的计算性能。上述5个计算任务之间,只有1, 3, 4三个计算任务必须串行地执行,因此,在新的处理器上,这样做甚至能够提高程序的并行度,从而使程序效率变得更高。
5.3 全局寄存器优化
[待修订内容] 本章中,从这一节开始的所有优化都是在微观层面上的优化了。换言之,这些优化是不能使用高级语言中的对应设施进行解释的。这一部分内容将进行较大规模的修订。
通常,此类优化是由编译器自动完成的。我个人并不推荐真的由人来完成这些工作——这些工作多半是枯燥而重复性的,编译器通常会比人做得更好(没说的,肯定也更快)。但话说回来,使用汇编语言的程序设计人员有责任了解这些内容,因为只有这样才能更好地驾驭处理器。
在前面的几章中我已经提到过,寄存器的速度要比内存快。因此,在使用寄存器方面,编译器一般会做一种称为全局寄存器优化的优化。
例如,在我们的程序中使用了4个变量:i, j, k, l。它们都作为循环变量使用:
for(i=0; i<1000; i++){
for(j=0; j<1000; j++){
for(k=0; k<1000; k++){
for(l=0; l<1000; l++)
do_something(i, j, k, l);
}
}
}
这段程序的优化就不那么简单了。显然,按照通常的压栈方法,i, j, k,l应该按照某个顺序被压进堆栈,然后调用do_something(),然后函数做了一些事情之后返回。问题在于,无论如何压栈,这些东西大概都得进内存(不可否认某些机器可以用CPU的Cache做这件事情,但Cache是写通式的和回写式的又会造成一些性能上的差异)。
聪明的读者马上就会指出,我们不是可以在定义do_something()的时候加上inline修饰符,让它在本地展开吗?没错,本地展开以增加代码量为代价换取性能,但这只是问题的一半。编译器尽管完成了本地展开,但它仍然需要做许多额外的工作。因为寄存器只有那么有限的几个,而我们却有这么多的循环变量。
把四个变量按照它们在循环中使用的频率排序,并决定在do_something()块中的优先顺序(放入寄存器中的优先顺序)是一个解决方案。很明显,我们可以按照l, k, j,i的顺序(从高到低,因为l将被进行1000*1000*1000*1000次运算!)来排列,但在实际的问题中,事情往往没有这么简单,因为你不知道do_something()中做的到底是什么。而且,凭什么就以for(l=0; l<1000;l++)作为优化的分界点呢?如果do_something()中还有循环怎么办?
如此复杂的计算问题交给计算机来做通常会有比较满意的结果。一般说来,编译器能够对程序中变量的使用进行更全面地估计,因此,它分配寄存器的结果有时虽然让人费解,但却是最优的(因为计算机能够进行大量的重复计算,并找到最好的方法;而人做这件事相对来讲比较困难)。
编译器在许多时候能够作出相当让人满意的结果。考虑以下的代码:
int a=0;
for(int i=1; i<10; i++)
for(int j=1; j<100; j++){
a += (i*j);
}
让我们把它变为某种形式的中间代码:
00: 0 -> a
01: 1 -> i
02: 1 -> j
03: i*j -> t
04: a+t -> a
05: j+1 -> j
06: evaluate j < 100
07: TRUE goto 03
08: i+1 -> i
09: evaluate i < 10
10: TRUE goto 02
11: [继续执行程序的其余部分]
程序中执行强度最大的无疑是03到05这一段,涉及的需要写入的变量包括a, j;需要读出的变量是i。不过,最终的编译结果大大出乎我们的意料。下面是某种优化模式下Visual C++ 6.0编译器生成的代码(我做了一些修改):
xor eax, eax ; a=0(eax: a)
mov edx, 1 ; i=1(edx: i)
push esi ; 保存esi(最后要恢复,esi作为代替j的那个循环变量)
nexti:
mov ecx, edx ; [t=i]
mov esi, 999 ; esi=999: 此处修改了原程序的语义,但仍为1000次循环。
nextj:
add eax, ecx ; [a+=t]
add ecx, edx ; [t+=i]
dec esi ; j--
jne SHORT nextj ; jne 等价于 jnz. [如果还需要,则再次循环]
inc edx ; i++
cmp edx, 10 ; i与10比较
jl SHORT nexti ; i < 10, 再次循环
pop esi ; 恢复esi
这段代码可能有些令人费解。主要是因为它不仅使用了大量寄存器,而且还包括了5.2节中曾提到的子表达式提取技术。表面上看,多引入的那个变量(t)增加了计算时间,但要注意,这个t不仅不会降低程序的执行效率,相反还会让它变得更快!因为同样得到了计算结果(本质上,i*j即是第j次累加i的值),但这个结果不仅用到了上次运算的结果,而且还省去了乘法(很显然计算机计算加法要比计算乘法快)。
这里可能会有人问,为什么要从999循环到0,而不是按照程序中写的那样从0循环到999呢?这个问题和汇编语言中的取址有关。在下两节中我将提到这方面的内容。
5.4 x86体系结构上的并行最大化和指令封包
考虑这样的问题,我和两个同伴现在在山里,远处有一口井,我们带着一口锅,身边是树林;身上的饮用水已经喝光了,此处允许砍柴和使用明火(当然我们不想引起火灾:),需要烧一锅水,应该怎么样呢?
一种方案是,三个人一起搭灶,一起砍柴,一起打水,一起把水烧开。
另一种方案是,一个人搭灶,此时另一个人去砍柴,第三个人打水,然后把水烧开。
这两种方案画出图来是这样:
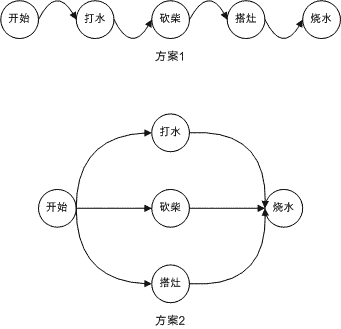
仅仅这样很难说明两个方案孰优孰劣,因为我们并不明确三个人一起打水、一起砍柴、一起搭灶的效率更高,还是分别作效率更高(通常的想法,一起做也许效率会更高)。但假如说,三个人一个只会搭灶,一个只会砍柴,一个只会打水(当然是说这三件事情),那么,方案2的效率就会搞一些了。
在现实生活中,某个人拥有专长是比较普遍的情况;在设计计算机硬件的时候则更是如此。你不可能指望加法器不做任何改动就能去做移位甚至整数乘法,然而我们注意到,串行执行的程序不可能在同一时刻同时用到处理器的所有功能,因此,我们(很自然地)会希望有一些指令并行地执行,以充分利用CPU的计算资源。
CPU执行一条指令的过程基本上可以分为下面几个阶段:取指令、取数据、计算、保存数据。假设这4个阶段各需要1个时钟周期,那么,只要资源够用,并且4条指令之间不存在串行关系(换言之这些指令的执行先后次序不影响最终结果,或者,更严格地说,没有任何一条指令依赖其他指令的运算结果)指令也可以像下面这样执行:
指令1 取指令 取数据 计算 存数据 指令2 取指令 取数据 计算 存数据 指令3 取指令 取数据 计算 存数据 指令4 取指令 取数据 计算 存数据
这样,原本需要16个时钟周期才能够完成的任务就可以在7个时钟周期内完成,时间缩短了一半还多。如果考虑灰色的那些方格(这些方格可以被4条指令以外的其他指令使用,只要没有串行关系或冲突),那么,如此执行对于性能的提升将是相当可观的(此时,CPU的所有部件都得到了充分利用)。
当然,作为程序来说,真正做到这样是相当理想化的情况。实际的程序中很难做到彻底的并行化。假设CPU能够支持4条指令同时执行,并且,每条指令都是等周期长度的4周期指令,那么,程序需要保证同一时刻先后发射的4条指令都能够并行执行,相互之间没有关联,这通常是不太可能的。
最新的Intel Pentium 4-XEON处理器,以及Intel Northwood Pentium 4都提供了一种被称为超线程(Hyper-Threading TM)的技术。该技术通过在一个处理器中封装两组执行机构来提高指令并行度,并依靠操作系统的调度来进一步提升系统的整体效率。
由于线程机制是与操作系统密切相关的,因此,在本文的这一部分中不可能做更为深入地探讨。在后续的章节中,我将介绍Win32、FreeBSD5.x以及Linux中提供的内核级线程机制(这三种操作系统都支持SMP及超线程技术,并且以线程作为调度单位)在汇编语言中的使用方法。
关于线程的讨论就此打住,因为它更多地依赖于操作系统,并且,无论如何,操作系统的线程调度需要更大的开销并且,到目前为止,真正使用支持超线程的CPU,并且使用相应操作系统的人是非常少的。因此,我们需要关心的实际上还是同一执行序列中的并发执行和指令封包。不过,令人遗憾的是,实际上在这方面编译器做的几乎是肯定要比人好,因此,你需要做的只是开启相应的优化;如果你的编译器不支持这样的特性,那么就把它扔掉……据我所知,目前在Intel平台上指令封包方面做的最好的是Intel的C++编译器,经过Intel编译器编译的代码的性能令人惊异地高,甚至在AMD公司推出的兼容处理器上也是如此。
5.5 存储优化
从前一节的图中我们不难看出,方案2中,如果谁的动作慢,那么他就会成为性能的瓶颈。实际上,CPU也不会像我描述的那样四平八稳地运行,指令执行的不同阶段需要的时间(时钟周期数)是不同的,因此,缩短关键步骤(即,造成瓶颈的那个步骤)是缩短执行时间的关键。
至少对于使用Intel系列的CPU来说,取数据这个步骤需要消耗比较多的时间。此外,假如数据跨越了某种边界(如4或8字节,与CPU的字长有关),则CPU需要启动两次甚至更多次数的读内存操作,这无疑对性能构成不利影响。
基于这样的原因,我们可以得到下面的设计策略:
程序设计中的内存数据访问策略
尽可能减少对于内存的访问。在不违背这一原则的前提下,如果可能,将数据一次处理完。 尽可能将数据按4或8字节对齐,以利于CPU存取 尽可能一段时间内访问范围不大的一段内存,而不同时访问大量远距离的分散数据,以利于Cache缓存*
第一条规则比较简单。例如,需要求一组数据中的最大值、最小值、平均数,那么,最好是在一次循环中做完。
“于是,这家伙又攒了一段代码”……
int a[]={1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9,0};
int i;
int avg, max, min;
avg=max=min=a[0];
for(i=1; i<(sizeof(a)/sizeof(int)); i++){
avg+=a[i];
if(max < a[i])
max = a[i];
else if(min > a[i])
min = a[i];
}
avg /= i;
Visual C++编译器把最开始一段赋值语句翻译成了一段简直可以说是匪夷所思的代码:
; int a[]={1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9,0};
mov edi, 2 ; 此时edi没有意义
mov esi, 3 ; esi也是!临时变量而已。
mov DWORD PTR _a$[esp+92], edi
mov edx, 5 ; 黑名单加上edx
mov eax, 7 ; eax也别跑:)
mov DWORD PTR _a$[esp+132], edi
mov ecx, 9 ; 就差你了,ecx
; int i;
; int avg, max, min;
; avg=max=min=a[0];
mov edi, 1 ; edi摇身一变,现在它是min了。
mov DWORD PTR _a$[esp+96], esi
mov DWORD PTR _a$[esp+104], edx
mov DWORD PTR _a$[esp+112], eax
mov DWORD PTR _a$[esp+136], esi
mov DWORD PTR _a$[esp+144], edx
mov DWORD PTR _a$[esp+152], eax
mov DWORD PTR _a$[esp+88], 1 ; 编译器失误 此处edi应更好
mov DWORD PTR _a$[esp+100], 4
mov DWORD PTR _a$[esp+108], 6
mov DWORD PTR _a$[esp+116], 8
mov DWORD PTR _a$[esp+120], ecx
mov DWORD PTR _a$[esp+124], 0
mov DWORD PTR _a$[esp+128], 1
mov DWORD PTR _a$[esp+140], 4
mov DWORD PTR _a$[esp+148], 6
mov DWORD PTR _a$[esp+156], 8
mov DWORD PTR _a$[esp+160], ecx
mov DWORD PTR _a$[esp+164], 0
mov edx, edi ; edx是max。
mov eax, edi ; 期待已久的avg, 它被指定为eax
这段代码是最优的吗?我个人认为不是。因为编译器完全可以在编译过程中直接把它们作为常量数据放入内存。此外,如果预先对a[0..9]10个元素赋值,并利用串操作指令(rep movsdw),速度会更快一些。
当然,犯不上因为这些问题责怪编译器。要求编译器知道a[0..9]和[10..19]的内容一样未免过于苛刻。我们看看下面的指令段:
; for(i=1; ...
mov esi, edi
for_loop:
; avg+=a[i];
mov ecx, DWORD PTR _a$[esp+esi*4+88]
add eax, ecx
; if(max < a[i])
cmp edx, ecx
jge SHORT elseif_min
; max = a[i];
mov edx, ecx
; else if(min > a[i])
jmp SHORT elseif_min
elseif_min:
cmp edi, ecx
jle SHORT elseif_end
; min = a[i];
mov edi, ecx
elseif_end:
; [for i=1]; i<20; i++){
inc esi
cmp esi, 20
jl SHORT for_loop
; }
; avg /= i;
cdq
idiv esi
; esi: i
; ecx: 暂存变量, =a[i]
; eax: avg
; edx: max
; 有趣的代码...并不是所有的时候都有用
; 但是也别随便删除
; edi: min
; i++
; i与20比较
; avg /= i
上面的程序倒是没有什么惊人之处。唯一一个比较吓人的东西是那个jmpSHORT指令,它是否有用取决于具体的问题。C/C++编译器有时会产生这样的代码,我过去曾经错误地把所有的此类指令当作没用的代码而删掉,后来发现程序执行时间没有明显的变化。通过查阅文档才知道,这类指令实际上是“占位指令”,他们存在的意义在于占据那个地方,一来使其他语句能够正确地按CPU觉得舒服的方式对齐,二来它可以占据CPU的某些周期,使得后续的指令能够更好地并发执行,避免冲突。另一个比较常见的、实现类似功能的指令是NOP。
占位指令的去留主要是靠计时执行来判断。由于目前流行的操作系统基本上都是多任务的,因此会对计时的精确性有一定影响。如果需要进行测试的话,需要保证以下几点:
计时测试需要注意的问题
测试必须在没有额外负荷的机器上完成。例如,专门用于编写和调试程序的计算机 尽量终止计算机上运行的所有服务,特别是杀毒程序 切断计算机的网络,这样网络的影响会消失 将进程优先级调高。对于Windows系统来说,把进程(线程)设置为Time-Critical; 对于*nix系统来说,把进程设置为实时进程 将测试函数运行尽可能多次运行,如10000000次,这样能够减少由于进城切换而造成的偶然误差 最后,如果可能的话,把函数放到单进程的系统(例如FreeDOS)中运行。
对于绝大多数程序来说,计时测试是一个非常重要的东西。我个人倾向于在进行优化后进行计时测试并比较结果。目前,我基于经验进行的优化基本上都能够提高程序的执行性能,但我还是不敢过于自信。优化确实会提高性能,但人做的和编译器做的思路不同,有时,我们的确会做一些费力不讨好的事情。