当数据在传送中出错,且错帧被漏检时,就意味着错误的数据被送到应用层,除非应用层有额外的数据识别措施,这个数据就可能引起不可预测的结果。CAN协议声称有很低的错帧漏检率(4.7×10-11×出错率)[1],有的宣传材料在一定条件下推出要1000年才有1次漏检,这是不正确的。错帧漏检率是一个十分重要的指标,很多应用就是看到Bosch CAN2.0规范上的说明才选用CAN的。但是对这个指标的来源仅有极少的公开资料[2],以及很少的讨论[3],使用户很难对它确认或验证,这给用户带来风险。本文采用了重构出错漏检实例的方法,导出了CAN的漏检错帧概率下限,它比CAN声称的要大几个数量级。在许多应用中,CAN已是可靠性和价格平衡下的不二选择,或者已被长期生产和使用,面对这个新发现的问题,在CAN本身未作改进之前,迫切需要一种“补丁”来加以改善。由于篇幅有限,所以只能摘要介绍错帧漏检率的推导过程,重点在提供解决方案。
1 关于CAN漏检错帧概率文献的讨论
Bosch CAN2.0规范[1]说它的漏检错帧概率小于错帧率(message error rate)×4.7×10-11。它的来源见参考文献[2],其中没有提供产生漏检的分析算法,仅提到用大量仿真得到了公式。要判断一个帧出错后是否会漏检,至少要计算2次CRC,对每一bit仅就汇编语言也需要几条指令,以该文考虑的80~90 bit的帧,CRC覆盖58~66 bit就要循环58~66次,以1989年时常用的PDP11或VAX机,一条机器指令要0.1 μs左右,一帧的判断要0.07 ms,即使不停机做一年,能作2.20×1011帧,考虑58 bit可构成258=2.88×1017种不同的帧,再加有58×57种不同的加入2位bit错的位置组合,所以能作的仿真只是可能情况的微乎其微的一部分(百万分之一)。由于样本太小,归纳的公式也就很难把影响因素考虑完整。
1999年Tran[3]对错帧漏检率也作了研究,鉴于分析困难,他也采用计算机大量仿真的办法,针对11位ID 、8字节数据帧,他用的是600 MB的Alpha服务器。与上述讨论一样,虽然仿真量很大,仍然是可能情况的极小部分。
CAN有关的另一个标准CANopen Draft Standard 304 (2005)给出的错帧漏检率是(7.2×10-9)[4]。同样来自CAN自动化协会的不同数据,使人无可适从。
2 新错帧漏检率的导出
本文的研究方法是构造出漏检的实例,确定该种实例占可能的帧的概率,乘以与该实例相应的出多位错的概率,然后求出所有可能的实例,得到CAN的错帧漏检率。本文对最有可能造成漏检的二位错情况进行分析,然后扩大为有多位错。数据域取8字节,并假定错都发生在数据域内。它并没有将超过CRC校验能力时的分散的多bit错漏检率考虑进去,所以得到的是漏检错帧概率的下界。
2.1 CAN位填充中有错时的位序错开
在有可能产生填充的位流中有bit错时,就有可能造成发送方与接收方只有一方执行填充规则,造成填充位与信息位理解的错乱。图1(a)的第3位传送中出错,结果发送方的填充位1被接收方误读为数据1,整个接收数据比发送数据长了1位。图1(b)的第3位传送中的错使接收方产生了删除填充位的条件,因此它把发送的数据1删去,接收数据流短了1位。

图1 CAN的位填充规则使出错后接收位流变化
从位流变化可以知道,如果发生的2个bit错正好一次是图1(a)的类型,一次是图1(b)的类型,那么发送数据流和接收数据流的长度将仍然相等,如果2个错都发生在数据域,CAN的其他检验是发现不了它们的。
2.2 发生漏检的条件
发送的位流与接收的位流可写为多项式形式Tx(x)和Rx(x),CRC检验就是用CAN的生成多项式G(x)除这2个式子,得到的余数称为CRC值,如果2个余数相同,CRC检验通过。当发生传送错误,Rx (x)= Tx(x)+U(x)×G(x)时,对Tx(x)和Rx(x)求到的余数是相同的,这时就发生了错帧的漏检。因此只要找到U(x),就可以构造出漏检的实例。
2.3 由Ec(x)尾部确定漏错多项式U(x)
为了使读者了解推导过程的合理性,以下是举例。在前面已经发生过图1(b)的错后,Tx的i位被Rx收到为第i-1位。尾部发生的错对应图1(a)的情况如图2所示。图中Tx的这6位构成漏检实例的尾部,第1位1用于隔离前面位值的影响,使后面5位0后一定产生填充位。由于传送中有错,Rx不再有连续5位0。Tx的填充位被Rx视为数据位,Rx和Tx就对齐,在此以后的传送不再有位序错。由bit错发生位置的不同,Rx也不同,错误序列Ec也不同。这个Ec也是整个错误序列的尾部,用Ec,t表示。由图2可以看到,共有5种不同的错误序列尾部。显然,将Tx中的0/1取反并不改变错误序列尾部Ec,t的形式。

图2 第2个传送错造成填充位误读为信息位的5种漏检错序列尾部形式
在已知错误序列尾部形式Ec,t后便可以求出满足它的漏错多项式尾部Ut。将各多项式的系数表示为:

为满足Ec,t=G×Ut的尾部,那么系数有如下关系:

实际上将Ec,t、G均作逆序排列:
![]()
类似于求CRC值时的方法,将Ec,tR×x5除以GR就可以得到Ut的逆序系数,也就得到了Ut。由CAN生成多项式G的系数(1100,0101,1001,1001)以及Ec,t系数便得到了满足错误序列尾部形式的漏错多项式Ut,如表1所列。
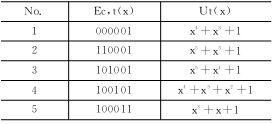
表1 错误序列尾部形式和漏错多项式Ut(x)
2.4 Ut的扩充形成Ec头部
在Ut中增加高于x5的项成为U,它不会影响Ec尾部的形式,但是它会增加错误序列的长度。由此U生成的Ec与Tx序列也将被漏检。Tx在数据域内不同位置的集合就构成了所有漏检实例。发生第一次bit错后并不立即开始TxRx位序的错位,要等到有填充位发生时才会有位序错。
2.5 构造出错实例Tx
以Ut= x4+x3+1为例,对应尾部第1位处出了传送错,Ut加上x6后有U=x6+x4+x3+1,计算得Ec=U×G=(1110,1111,0101,1010,0000,01),整个错误序列的长度为22位。该Ec确定头部出第1个传送错的位置是6,假定为漏删填充位错,则在尾部应取误删信息位错。假定在头部出现的是Tx送100000,在第6位处Rx收到的是1,出了第1个bit错,第7位Rx得到填充位1而未删去,Tx第7位可由Ec及Rx求得为0,然后逐位反推,得到Tx发生漏检错的实例,如图3所示。

图3 构造的会出漏检错的Tx实例
这个例子中Tx序列的长度为27 bit。此种长度的Tx可以有227种,每一种都可能出错,但重构出的这一种在特定位发生2个bit错时会漏检。这个Tx在别的位置发生bit错时,将可以检出错,因此它是一个可能被漏检的可疑实例。Tx头部共有4种可能:Tx=10000(0),10000(1),01111(1),01111(0)。(括号中的位在传送中出了错)。因此这几种可疑实例占可能Tx的2-25。可疑Tx在64 bit的数据域中会有64-27+1=38种位置。对头部Tx=100000和100001,其高4位可以与CAN的DLC重合,对Tx=011111和011110,其最高位可和DLC0重合,因此此种Tx实例在8字节数据域的帧中出现的可能数目是39种。于是这一种漏检实例有概率39×2-25=1.16×10-6。当误码率为0.02时,64 bit内出2个bit错的概率是(1-0.02)62×0.022=1.14×10-4,由这一个实例引起的CAN错帧漏检率就是1.32×10-10,已经大于Bosch的指标。考虑U中可增加的xk中k可由6一直到43,各种xk项有237=1.37×1011种组合,需要对每一种U进行计算,虽然它们的漏检实例概率不同,其增量还是很大的。还要考虑不同Ut的贡献,可见CAN错帧漏检率是非常大的。
2.6 计算结果
根据上述分析编制了在MATLAB中运行的程序pcan.m,在MATLAB中设置format long e格式,运行pcan(ber)即可得到不同误码率ber时的结果,如表2所列。
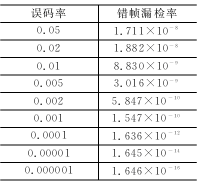
表2 典型的CAN漏检错帧概率
表中ber=0.02的错帧漏检率为1.882×10-8,而参考文献[2]在同样误码率下给出的漏检率是:低速系统4.7×10-14和高速系统8.5×10-14。可见差别极大。对500 kbps的系统,假定总线利用率为40%,帧长为135 bit,那么按这个结果,CAN系统将在9.96小时出1个漏检错帧。
3 改善错帧漏检率的方法
在本文的分析中可以见到,由于填充位规则需要收发同步执行,不同步时会极大干扰CRC校验,例如CRC校验本来可以将所有奇数个错检测出的,小于5位的多bit错是可以检测出的,但只要有了成对的填充位错位,增加的奇数个错也可以是漏检的,增加的多bit错也可以是漏检的,如图4所示。
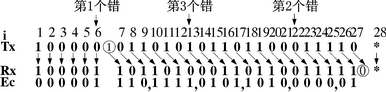
图4 有多位错的例子
漏检错的根源是CAN的CRC在执行填充位规则前生成,最根本的解决办法是像参考文献[3]指出的那样,要把CRC校验放在执行填充位规则之后。但是这样作就会根本修改CAN协议,在已经大量应用的情况下如何作到的改进前后的兼容性是个艰难的课题。作为局部的改正,参考文献[3]建议加附加的检验。在数据域添加一个新的不同的CRC检验时,根据本文的分析方法,当误差多项式Ec是这个新CRC和CAN的CRC的公倍数时,仍然可以构造出漏检的实例,并计算出新条件下的漏检错帧概率。例如采用8位的DARC8生成多项式x8+x5+x4+x3+1,它不含x+1因子,所以与CAN生成多项式的最小公倍数构成的漏错多项式Ec将有24阶,此时如2.5节所分析的那样,总帧数将增大28倍,而漏检帧数不变,漏检率就减少28。但是这种方法的缺点是不能实现自动报错,无法使节点间取得数据的一致性:有局部错的节点在添加上述措施后在收完帧后才能发现错,已无法要其他节点也丢弃该帧并要求自动重发。
本文建议采用7b/8b的编码办法,牺牲一些带宽,换取错帧漏检的避免。具体做法是在8b代码中选取不会发生填充位条件的部分,供原来7b编码使用。
其他的编码办法也是可行的,类似7b/8b的还有6b/7b、5b/6b、4b/5b,它们的区别是软件实现时的复杂程度以及开销占用数据域的多少,当用7b/8b时CAN可以每帧送7字节数据,而用4b/5b时每帧只能送6字节数据。
在附加数据域的软件补丁后,若发生在ID域和CRC域的填充位规则只有单边执行情况时,夹在它们中间的控制域就会左移或右移,帧长就会变大或变小。帧长的单位是1字节,它会使CRC域移入EOF域,CRC最多连续5位相同,就破坏了EOF的格式,或者EOF域移入CRC域,EOF的连续8位破坏了CRC的填充格式,所以此时单边执行填充位规则的错的后果是能被发现的。也就是说加软件补丁后不再有错帧漏检可能。
如果可疑Tx只发生在ID域,由于Tx有一个最短长度,相应于Ec,t= x3+x+1,这个长度是3+15+6=24位,所以对CAN2.0B的29位ID可能会出错,那么产生的后果就是接收节点收到的ID有错,这是一种假冒错(Masquerade)。在参考文献[6]中提到了CAN防止假冒错的方法,实际上将ID分为二部分,一部分是一个附加的CRC,只要这个CRC生成多项式与CAN的不同,就不会产生假冒ID通过接收滤的可能。
4 小结
CAN的错帧漏检率对应用的可靠性有非常大的影响,本文发现了可能出错漏检的可疑帧重构的方法,从而求出的错帧漏检率高于Bosch提供的数据几个数量级。对于已经在应用的大量可靠性要求高的系统,迫且需要应对的方案,2007年CAN芯片1年的出货量为6亿[7],可见影响之广。本文提出了对数据添加7b/8b编码/译码的中间软件补丁的方法。这种方法在牺牲部分带宽,增加一些个复杂性的付出后,根本上解决了填充规则对CRC检验的干扰,使CAN的错帧漏检率回到与一般通信协议中CRC检验同等的水平。数据域牺牲的带宽为8 bit,相对可能出现16 bit填充位而言,这算不了什么,而且减少了送达时间的抖动,可说是有好处的。不利之处是编码/译码需要的时间与空间。
这个方法也可以在将来加入到芯片中去,利用CAN的保留位,识别有无7b/8b编码/译码功能,从而实现与原有CAN2.0的兼容。有7b/8b编码/译码功能时,需要的7b/8b编码/译码、字长圆整以及帧长修正均可由硬件自动完成。