3 图像处理算法在CORTEX-A8 平台上的优化
本系统是Cortex-A8和Linux系统上搭建,Linux下使用的编译器为GCC.本文中使用普通C 语言优化和NEON编程优化对图像相关函数进行了优化,并进行了测试对比,下面给出方差函数variance代码进行优化前后的对比说明,如图5优化前的代码。

3.1 C语言级别优化
对于一般C语言级别的优化,对于图像这类矩阵数据而言,主要针对循环优化。以第一个循环为例,如图6对于C语言级别循环优化后的代码如图6所示。
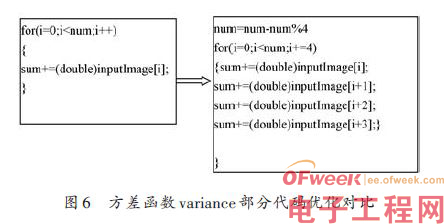
由优化后的结果可见,通过对循环展开,有效的减少了循环跳转次数,跳转为原来的1 4 .但是也可以发现,加法运算次数,几乎和原来相同并没有减少。对于其他for循环和其他函数进行优化后,测试时间对比如表2所示。
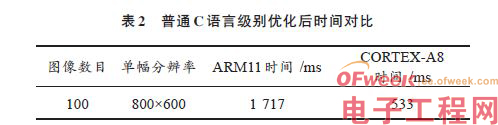
由表中数据可见,使用普通C 语言界别优化,并没有明显提升,原因是在Linux系统上使用GCC编译器进行编译的,在选择-O2 级别优化的时候,已经对循环进行了优化,所以运行速度没有明显提升。
3.2 使用NEON技术的优化
GCC 编译器从4.3 版本开始,很好地提供了对ARM NEON 技术的支持。例如GCC 中的函数:
uint32x2_t vadd_u32(uint32x2_t,uint32x2_t),对应汇语言:vadd.i32 d0,d0,d0.uint32x2_t代表这个数据类型是2 个32 位无符号整型。在使用GCC 编译器中的NEON 技术时,需要包含头文件<arm_neon.h>.NEON增强指令集是在Cortex-A系列发布后才具有的功能,因此ARM11 无法使用NEON 技术。对方差函数variance第一个for循环优化后的代码对比如图7所示。

由优化后程序代码可见,循环跳转次数为原来的1 4 ,但是由于使用了NEON 相关的vld1q_u32 函数,一次可在NEON的128位寄存器中装入4个32位数值,调用vaddq_u32可对4个数据时同时进行加法运算,在一个指令周期就完成了4次加法运算,理论上加法运算次数为原来的1 4 ,大大提高了运算性能。
对于第二个for循环也可以采用类似方法优化,只是调用的函数略有不同,具体考参考GCC的技术文档,有详细的使用说明。
其他函数如预处理、角点、相关度函数的优化和此方法类似,重点针对循环和可以并行运算的代码进行优化。
表3 中给出了Cortex-A8 平台使用NEON 技术优化后与ARM11测试时间的对比。

4 结语
通过使用ARM NEON 技术,对于图像处理这类矩阵运算进行并行优化,可大大提高处理速度,进行优化后,速度较优化前提升了达2倍之多,较ARM11提升了8 倍的速度。ARM COTEX-A 系列所使用的NEON 技术,不仅使车位图像检测算法的速度有很大提升,在信号处理等多媒体处理算法中,也有广阔的应用前景。



![[马上学Android]安卓开发视频教程020-Android](/Uploads/2014_12/video/vi11e2863f15fba4208eeb76787c67b452_s.jpg)






















