摘要:上世纪60年代初,香农的学生Gallager在他的博士毕业论文中首次提出了LDPC码的概念和完整的译码方法,但是直到上世纪末期,随着LDPC码译码理论的进步和计算机技术的发展,LDPC码才以其优良的误码性能和良好的可实现性成为人们研究的焦点。针对QC类LDPC码进行研究的时候,注意到很多码的循环子矩阵中不只有一组1,这就产生了水平运算后判断运算结果属于哪个存储模块的问题;另外,由于校验矩阵中每个循环子矩阵的列初始位置都是不同的,而且通常LDPC码的校验矩阵的循环子矩阵的数目都是非常庞大的,因此如果通过程序固化的方法,不但容易出现不易排查的错误,而且开发效率会大大下降。为解决该问题,并将解决方案通用化,文中以校验矩阵中循环子矩阵中1的排列特点为研究对象,找到引起变化的量之间的共性特征,从而实现通用化模块的设计。
关键词:LDPC;通用;准循环;数据分配
近几年,人们对可靠高效的信息传输和存储技术提出了越来越高的要求。差错控制编码作为一种纠正由信道噪声带来传输错误的有效方式,被广泛应用与数字通信和存储等领域。Low-Density Parity-Check(LDPC)码发明于上世纪60年代初期,它是一类性能接近香农极限的差错控制编码,采用置信传播的译码方式进行译码。随着VLSI和计算机技术革命性进步的到来,LDPC码的实现成为了可能,并且由于在AWGN信道下的极佳误码性能和高并行度实现引起了人们的强烈关注。目前,LDPC码的普及程度大大增加,很多标准也都将LDPC码纳入进来,这都导致了与LDPC码泽码的相关课题与日俱增,随之而来的问题是大量的重复性的开发工作,因此需要将一些共性的开发工作进行通用的模块化设计,以提高开发效率。
1 传统的译码方案在通用性方面的不足
在LDPC码的实现过程中,水平运算结果利用4维定位方法,存储了最小值、次小值、最小值位置和符号位。然而像CCSDS近地通信码这样的LDPC码的校验矩阵中的每个循环子矩阵都有两组1,它们都按照准循环的方式排列,如图1所示。
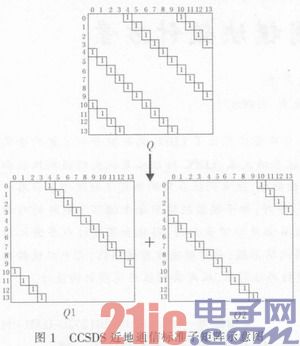
图中所示0为校验矩阵的一个列重为2的循环子矩阵,该矩阵可以拆分成两个列重为1的循环子矩阵Q1和Q2,这一结构对下文所述的数据分配策略和改进的垂直运算过程有决定性的影响。
图2中给出了一个循环子矩阵数据读取的示意图。从该图中可以看出,在实线所示的仞始状态时,读取的数据顺序是存储器1中数据在前而存储器2中的数据在后,但是到了虚线所示的时刻,读取的数据顺序变成了存储器2中的数据在前,存储器1中的数据在后。
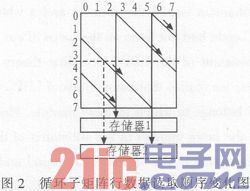
在每个循环子矩阵中只有一组1或没有1的情况下,只需要按照存储器中数据存储的顺序读取,然后进行水平运算即可,然而若循环子矩阵中的1不止一组的时候,数据的读取就会发生混乱,有时存储器1的数据在前,而有时存储器2中的数据在前,这对判断最小值属于哪个存储器极为不利。
因此需要开发一种通用化的辨识数据先后顺序的模块,该模块附着在校验矩阵中的每一个列块上,对输出的数据自动做好标识,使得水平运算的结果能够精确的反应数据的来源。
2 文中所采用的范例码
基于EG(欧式几何)的QC(准循环)LDPC码属于QCLDPC码,该类码的构造是基于欧式几何有限域分解的。(8176,7154)LDPC码最初是为NASA设计的,它是一个规则的QC LDPC码,行重32,列重4。目前(8176,7154)LDPC码是CCSDS推荐的近地通信码,它具有很好的规则性,目前已
被应用于遥感卫星等航天器的近地通信领域。
本部分内容给出的CCSDS近地通信(8176,7154)QC-LDPC码的译码方法,同样适用于其他的每个循环子矩阵中有1组或2组1的OC-LDPC码情况。
3 文中所采用的译码算法
LDPC码的译码算法主要分为软译码算法和硬译码算法,软译码算法主要是指Gallager最早提出的LDPC码概率译码算法、BP算法以及BP算法的改进型最小和算法;硬译码算法主要是指BF算法。
采用软译码算法泽码获得的编码增益比较高,在绝大多数情况下,众多软译码算法中具备实现价值的译码方法之一仍是BP算法的改进算法之一,最小和算法。传统最小和算法的水平运算公式。

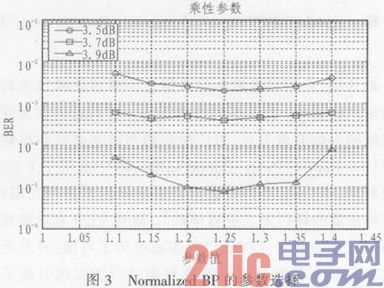
后来人们改进了最小和算法,提出了Normalized BP和Offset BP两种算法,这两种算法在本质上是等价的,都极大地改进了最小和算法的译码精度,使得最小和算法的编码增益更加接近传统的BP算法,目前这两种算法中以NormalizedBP算法应用较为广泛。文中采用了Norma lized BP算法,图3给出了Normalized BP的参数选择情况,如图所示,在参数值为1.25时得到了最小和算法的最好修正结果,但是通常在实现过程中,为了利于硬件功能的实现,会将(1/λk)的值设为0.75,这样便于硬件乘法的实现。
硬件实现的过稃中该参数的实现手段如图4所示。

经过对原数值的两次移位,得到该数值的四分值,通过减法达到(1/λk)为0.75的目的。
4 通用化模块设计
下面的讨论不失一般性,以每个循环子矩阵巾有3组1为例进行说明。
如图5所示。A,B,C 3条线从“初始列号”开始向右侧进行编排,由于C线的ver_pos_C(ver_pos_A、ver_pos_B、ver_pos_C分别指循环子矩阵中每组1的列初始位置)值最大,即C线在最右端.这也就意味着在经过511—1—ver_pos_C(511是每个循环子矩阵的大小)行的运算之后,C线首先将要从最左边重新开始循环。因此,下面进行的数据初始化顺序从A,B,C,变为C,A,B,以此类推。
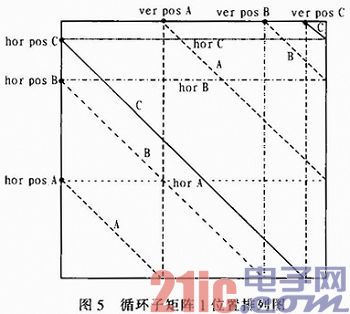
总而言之,每当排在最右侧的一条线到达最右侧的列时,下一步的CNU运算就将其变为本子矩阵的最先处理的数据。因为有这样的运行规律,于是形象的称这种运行方式为“反弹”。即,每当排在最右侧的线碰撞到循环子矩阵的右侧壁时便发生“反弹”,横向处理数据的顺序便进行一次向右的循环移位,将最右侧线的数据移到最左边,其他的数据顺序不变。
如此循环,直到把该循环子矩阵中所有的“1”位置全部处理完毕。每当循环子矩阵中发生一次“碰壁”后“定位位”就加1。
想要知道每条线横向的先后顺序就需要用到前面提到的“穿越”方法。首先确定3条水平直线,3条水平直线位于hor_pos_A,hor_pos_B,hor_pos_C位置上,记为hor_A,hor_B,hor_C,如图5所示。A,B,C 3条线从“初始行号”位置开始向右侧进行编排,A,B,C中的每条线,每当穿越hor_A,hor_B,hor_C中的直线时,A,B,C的横向计数便加1,因为每穿越一次除它本身之外的线时,在它左边就多一条线。因此本方法称之为“穿越”。
先以C线为例进行说明。C线从hor_pos_C点歼始,向右侧移动,当C线的行号“穿越”第一个除hor_C以外的水平直线hor_B的时候.此时C线上数据的编号加1。
5 加入通用化模块的高速译码实现方案
从上面的分析的出结论,当存储器内的数据进行向右侧的循环移位的时候,每当到达最右侧,通用定位模块检测到这一信息便将通用定位模块的输出加1。存储在定位位内。具体说明参见如图6所示。
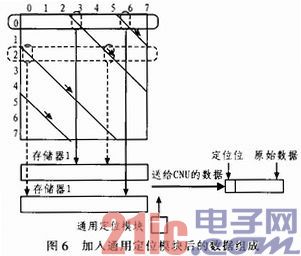
该图说明了加入通用化定位模块后的数据组成。仍以图2所述矩阵为例,而且列初始位置小的一组1的数据从存储器1中读出,列初始位置大的一组1从存储器2中读出。当数据初始化到两个存储器内之后,进行水平运算的时候,首先提取第0行的数据以实线表示,此时的通用定位模块的定位位输出是0,输出到CNU进行运算的数据前端的定位位也是0。随着数据读取的进行,当进行到以虚线表示的第2行进行数据读取的时候,存储器1对应那组1达到了存储器的还没有到达存储器的最右侧,而此时从存储器2中读出的数据已经经过了该存储器的最右侧,开始重新从最左边读数,因此定位位被通用定位模块加1,变为1。
这样进行数据的读取工作,直到读完该循环子矩阵中所有的数据,所有读出的数据都在首位增加了一个“定位位”,然后被送往CNU参与水平运算。
增加了通用定位模块对CNU的结构也有所影响。文献中曾给出CNU运算结果的四维存储方法,存储的信息包括最小值,次小值,最小值的位置和符号位,该存储方法大大节约了存储器开销。然而当每个循环子矩阵中不止有一组1的时候,采用了通用化的定位模块,从存储器中读出的数据也增加了一位“定位位”,此时的CNU结构需要发生改变,来适应做出的调整。具体变化如图7所示。
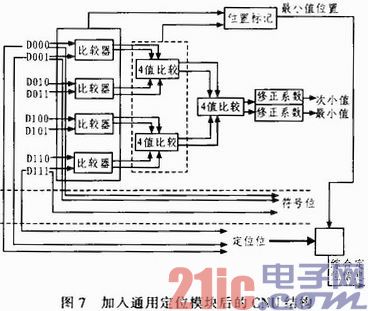
图中的输入端数据的头部都加入了一位“定位位”,该位不参与CNU的比较运算过程,因此单独将改为取出,在图中最下方标记出来。
若每个循环子矩阵中有两组1,使用图7中的CNU进行运算的时候,CNU的输入端总是把每个列块对应的两个M存储器中的存储器1连接在比较器的上方接口,存储器2连接在比较器的下方接口,例如D000连接第一列块的存储器1,D001连接第一列块的存储器2。这样进行的排列在“位置标记”模块的输出端可以得到最小值的位置是在D000~D111中的哪一个。然后将这一输出前加上该列块的“定位位”信息进行存储,这一行数据的其他“定位位”信息全部删除。
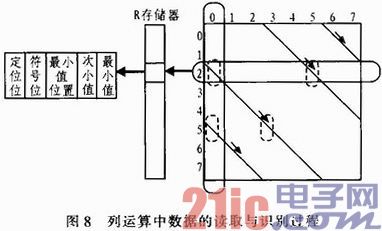
在垂直运算的过程中,需要利用上述信息确定求列和时参与运算数据的具体位置。列运算的实现方案如图8所示。现在假设进行循环子矩阵的第一列的列运算,需要得到的信息是第1列两个数据的值。下面以第2行第1列的数据为例进行说明。
第2行的数据经过水平运算后存储在R存储器中的对应位置上,该位置存储信息的格式如图中最左侧所示。若水平运算求得的最小值不在该子矩阵的列块范围内,那么该子矩阵中所有的数据全部以该行最小值输出参与垂直运算。
但是若水平运算求得的最小值在该子矩阵的列块内,那么就需要用“穿越”的方法确定所需数据在该列块中是水平方向上的第几个数据,确定了这一点后,就能够利用水平运算的结果中的“定位位”来判断该值是最小值还是次小值了。

从整个实现过程中可以看出,陔通用模块引入之后,可以通过流水的操作来消除对速度的影响,而且该模块的引入没有对存储资源构成任何多余的消耗。
另外从该方法的实现过程可以看出,该方法适用于BP算法、最小和算法以及最小和算法的改进算法,所以该方法也具有良好的算法通用性。
通过ISE中Xinlin公司V5-330芯片上的仿真可以看出该方法的资源消耗情况。时钟频率120 MHz。
6 结束语
本章还介绍了通用化模块的设计方法,针对循环子矩阵中不止有一组1的情况,利用了校验矩阵中循环子矩阵的自身特点,设计了能够自动识别1排列情况的模块,以利于垂直运算过程中自动调用水平运算的结果。该模块的加入不会对译码速度和存储资源造成任何消耗,而且有助于未来成熟高效地开发高速译码设备。