2003年,互联网泡沫破灭的时候,Altera开始了他的第三个十年。这是大结局的一年:哥伦比亚号航天飞机悲剧谢幕,先驱者10号失去联络,最后一台大众甲壳虫驶出装配线。但这也是开始的一年:伊拉克战争,美国股市大牛市的开始,私人开发的SpaceShipOne第一次超音速飞行,中国第一次载人航天。
在系统设计领域,FPGA悄然向下一阶段发展。使用最先进的CMOS技术,FPGA的逻辑密度和速度足以在一个芯片中实现CPU内核及其外设。Altera发布了Nios,这一RISC CPU内核针对FPGA进行了优化,合作伙伴也开发了在FPGA中实现的其他流行CPU内核。Avalon是一种多主机总线体系结构,适用于CPU和芯片系统之间的可编程逻辑规范互联。市场上还出现了SoPC Builder,这款工具可以自动的在基于FPGA的SoC中装入知识产权(IP)。
以CPU为中心的时期
即使在这十年中,SoC也趋向于采用简单模式,以它们所替代的电路板级计算机为基础。一片SoC通常包括一个CPU内核,一个本地高速缓存或者紧耦合SRAM,一个DRAM控制器,一条片内微处理器总线,以及应用程序所需要的外设控制器等(图1)。这类应用会包括DMA控制器或者应用加速器,适用于经常性的繁杂任务,例如,数据传送、加密计算,或者快速傅里叶变换(FFT)等。
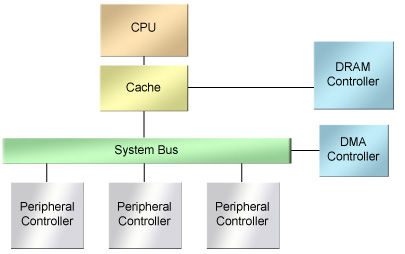
图1.一个典型的以CPU为中心的Soc设计
在FPGA中实现SoC有很大的优点。设计人员可以只选择CPU内核中需要的硬件模块。数字加速器可以使用Altera FPGA中的高速数字信号处理(DSP)模块,其算术性能要远远高于微处理器和DSP芯片组合所能达到的水平。设计人员还可以使用嵌入在FPGA架构中的可编程逻辑、DSP模块以及RAM模块实现定制加速器。可以把这些加速器设计用作微处理器总线单元,或者独立直通处理器,开发与微处理器控制平面相独立的数据平面。
据Altera产品规划经理Bernhard Friebe,提高集成度的一个重要优点是能效。FPGA中的RAM和DSP模块等硬件功能的能效不会低于等价的ASIC或者货架功能产品的能效。在可编程逻辑中实现的功能的功耗通常要比等价的标准产品高,但并不总是这样。但是,在这一时期,很多系统的主要能耗来自I/O。数据通过FPGA架构传送不但非常快,而且效率要远远高于通过芯片边界进行传送。通过限制FPGA内部宽带数据传送,系统设计人员能够有效的降低系统级能耗。
由于已经有了硬件和IP来支持以CPU为中心的SoC,因此,Altera的重点放在了工具流程上。很显然,SoC开发人员的工具需求与传统逻辑设计人员的完全不同。传统上,接口或者数据通路组件设计人员会以VHDL或者Verilog的形式详细的表达他们的设计,然后,每一个单元要通过逻辑验证、映射至FPGA资源以及时序收敛等步骤。
而SoC设计人员更关注抽象级。硬件足够快,片内RAM容量足够大?总线和存储器带宽够用吗?总线接口能够互联吗?由于能够充分重新使用IP,因此,设计投入的重点由全部SoC逻辑转向编写软件,利用已有IP开发一个或者两个新模块,将其置入到设计中。换句话说,SoC开发人员就像系统设计人员那样进行思考,而不像芯片设计人员那样。
这样带来的一个结果就是Altera于2005年首次推出的渐进式编译功能。设计投入一般是集中在SoC的一个或者两个模块上,而硬件大部分工作保持不变。Altera的渐进式编译特性支持设计人员对设计中的一部分重新进行设计,一般是固定位置和引脚约束,不需要通过工具链重新运行整个设计。这不仅节省了编译时间,而且降低了已经设计好的硬件部分受到干扰的风险。
SoC设计还导致偏向使用FPGA I/O引脚。作为总线桥接或者加速器,FPGA会有突发或者流形式的数据流过芯片,一般是从一条标准总线到另一条总线。一般而言,只有较少的时钟域,大部分是由总线定义的。
以CPU为中心的SoC带来了新需求。通常会有标准外部总线,例如,PCI或者USB。而现在,FPGA会最先使用总线,而不仅仅是总线上的一个用户。当然还会有DRAM端口,使得FPGA面临如何使用DDR SDRAM接口技术的难题。在片内外设控制器和外部器件之间还会有很多串行或者并行连接。这种多样性意味着更多的引脚,I/O上更多的信号和更大的电压变化,以及更多的时钟域。这些变化反映在越来越复杂的FPGA I/O单元和时钟网络上。
内核和多核
半导体工艺一直在不断改进,晶体管密度也越来越高。但是在Altera的第三个十年中,越来越难以进一步提高电路速度了。相应的,CPU生产商关注的重点从提高时钟频率转向两个、四个甚至管芯上更多的CPU内核——多核体系结构。SoC设计人员在ASIC设计和FPGA设计上都紧随其后。
多核思路体现在FPGA使用上有两个明显的方向。一个思路就是简单的复制CPU内核。这相对比较容易将多个处理器内核编译到FPGA中。但是将其连接起来就不那么容易了。这里,可编程逻辑提供了丰富的资源,设计人员几乎可以实现从阵列到紧耦合内核,直至共享L2高速缓存体系结构的所有一切,设计实现多主机Avalon总线上的独立CPU。
多核的另一个思路采用了不同的方法:异构系统。实现一个CPU内核例化的同一总线、IP和工具支持同时实现CPU内核和多个对等的加速器 (图2)。这也导致完全不同的多核设计思路:以软件为中心的方法。
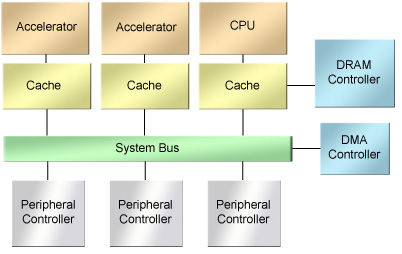
图2.一个异构多核SoC设计
设计同构多核系统非常直观,极其简单。您需要知道比单个CPU速度快多少倍。使用更多的CPU,多出一个或者两个也有可能降低效率。根据您期望的线程之间共享的存储器等级,选择互联体系结构。在CPU之间划分软件线程,仿真系统,并重复直至符合规范要求。这一过程一直是以硬件为中心的,选择一种体系结构,实现它,然后,划分代码,适配到硬件中。
但是,能够建立自己的加速器则创立了全新的方法。它是这样工作的。分析您的代码,找到热点。对于最难处理的代码部分,建立定制加速器,这节省了CPU周期,降低了能耗。仿真系统,然后再分析步骤,并重复,直到性能满足要求。这一方法从一个CPU内核上的工作软件开始,产生定制满足实际系统软件要求的多个硬件加速器。系统第一次反映了软件需求,而不是强制软件符合要求。
2006年,Altera推出了两项创新,支持这种异构多核设计风格。一项是编译器,将一组可执行ANSI C代码转换成加速器,针对Altera FPGA中的Nios CPU内核进行了优化。这种C语言至硬件加速(C2H)编译器工具自动完成以软件为中心的设计中最耗时和最容易出错的步骤:生成加速器。
第二项创新则不太明显。如果您对比一个快速单核处理器与时钟速度较慢的一组等价处理器的功耗,由于高效的加速器,动态功耗会大幅度下降。但是泄漏——多年来一直难以解决的问题,不论电路是否工作,都随着晶体管数量的增加而增大。因此,对于多核设计,泄漏电流对能效的影响最大。
Altera以第二项创新——可编程功耗技术来解决这一问题。硬件和软件工具相结合,对于时序不关键的通路,选择慢速低泄漏电路,减小了FPGA中的泄漏电流,同时实现了时序收敛。结果是,不管深亚微米工艺的泄漏有多大,都满足了异构多核设计的能耗要求。
一致性和增强
最后阶段标志着Altera第三个十年的结束:IP选择的一致性。逐渐的,系统设计领域更加关注最棘手问题的特殊解决方案。特别是,嵌入式系统开发人员几乎都采用了C语言,嵌入式计算普遍采用ARM内核,一些接口标准开始成为某些应用的主要标准,例如,高速系统总线、背板链接和芯片间互联等。由此,Altera开发创新技术来支持这些解决方案。
一个例子是,编程人员表达并行代码的方式。C语言虽然能够很好的定义顺序执行的程序,但是无法表达熟练的编程人员使用的并行处理方法。但是,名为OpenCL的C衍生语言可以。2011年,Altera推出了一组工具,支持编程人员采用越来越流行的OpenCL编写并行算法,将其翻译成FPGA中的并行硬件以及传统CPU中的控制代码,这不需要专门的FPGA设计知识。
多核SoC越来越一致的使用ARM Cortex-A类CPU内核带来了第二项创新。只要每一个设计团队希望有不同的CPU,FPGA供应商就要满足这些需求,在可编程逻辑中实现软核。但是这种灵活性有其成本:占用逻辑单元、高功耗和低速。
Altera则采用了别的方法:在越来越多的嵌入式和无线应用中使用Cortex-A9。2012年,公司开始推出具有管芯硬核处理器子系统的FPGA样片:双核Cortex-A9群,有自己的高速缓存、本地RAM、经过优化的存储器控制器,以及部分外设控制器,这些都在ASIC类型基于单元的硬件中实现。芯片设计人员非常小心的优化子系统和可编程逻辑架构之间的互联,以实现异构多核系统。
这种多核处理器系统和FPGA之间不断的融合带来了另一项更关键的创新。2013年,Altera发布其下一代高端FPGA不仅由传统的代工线合作伙伴制造,而且还由Intel公司制造,使用了14 nm三栅极工艺,这源自Intel自己的CPU和SoC。从ASIC定位的代工线市场转向擅长CPU的代工线,Altera FPGA独辟蹊径来解决功耗和性能问题,优化半导体工艺特性,而不是优化满足ASIC代工线要面对的各种市场需求,这对于工艺单元、本地RAM和高速互联都非常关键。
Altera相信,这种选择的结果是打破FPGA业界多年以来所习惯的性能和能耗模式。这是新十年最好的开始。