目前,关于视觉系统的研究已经成为热点,也有开发出的系统可供参考。但这些系统大多是基于PC机的,由于算法和硬件结构的复杂性而使其在小型嵌入式系统中的应用受到了限制。上述系统将图像数据采集后,视觉处理算法是在PC机上实现的。随着嵌入式微处理器技术的进步,32位ARM处理器系统拥有很高的运算速度和很强的信号处理能力,可以作为视觉系统的处理器,代替PC机来实现简单的视觉处理算法。下面介绍一种基于ARM和CPLD的嵌入式视觉系统,希望能分享嵌入式视觉开发过程中的一些经验。
1 系统方案与原理
在嵌入式视觉的设计中,目前主流的有以下2种方案:
方案1图像传感器+微处理器(ARM或DSP)+SRAM
方案2图像传感器+CPLD/FPGA+微处理器+SRAM
方案1系统结构紧凑,功耗低。在图像采集时,图像传感器输出的同步时序信号的识别需要借助ARM的中断,而中断处理时,微处理器需要完成程序跳转、保存上下文等工作[1],降低了图像采集的速度,适合对采集速度要求不高、功耗低的场合。
方案2借助CPLD来识别图像传感器的同步时序信号,不必经过微处理器的中断,因而系统的采集速度提高,但CPLD的介入会使系统的功耗提高。
为了综合以上2种方案的优势,在硬件上采用“ARM+CPLD+图像传感器+SRAM”。该方案充分利用了CPLD的可编程性,通过软件编程来兼有方案1的优势,具体体现在以下方面:
① 功耗的高低可以控制。对于功耗有严格要求的场合,通过CPLD的可编程性将时序部分的接口与ARM的中断端口相连,仅仅是组合逻辑的总线相连,可以降低CPLD的功耗从而达到方案1的效果;对于采集速度要求高而功耗要求不高的情况,可以充分发挥CPLD的优势,利用组合与时序逻辑来实现图像传感器输出同步信号的识别,并将图像数据写入SRAM中。
② 器件的选择可以多样。在硬件设计上,所有总线均与CPLD相连;在软件设计上,不同的模块单独按功能封装。这样以CPLD为中心,系统的其他器件均可更换而无需对CPLD部分程序进行改动,有利于系统的功能升级。
作为本系统的一种应用,开发了视觉跟踪的程序,可以在目标和背景颜色对比强烈的情况下对物体进行跟踪。通过对CMOS摄像头采集来的数据进行实时处理,根据物体的颜色计算出被追踪物体的质心坐标。下面分别描述系统各部分的功能。
2 系统硬件
2.1 硬件组成及连接
系统的硬件主要有4部分:CMOS图像传感器OV6620、可编程器件CPLD、512 KB的SRAM和32位微处理器LPC2214。
OV6620是美国OmniVision公司生产的CMOS图像传感器,以其高性能、低功耗适合应用在嵌入式图像采集系统中,本系统图像数据的输入都是通过OV6620采集进来的;可编程器件CPLD采用Altera公司的EPM7128S,用Verilog硬件编程语言在QuartusII下编写程序;作为系统的数据缓冲,SRAM选用的是IS61LV5128,其随机访问的特性为图像处理程序提供了便利;而LPC2214在PLL(锁相环)的支持下最高可以运行在60 MHz的频率下,为图像的快速处理提供了硬件支持。
OV6620集成在一个板卡上,有独立的17 MHz晶振。输出3个图像同步的时序信号:像素时钟PCLK、帧同步VSYNC和行同步HREF。同时,还可以通过8位或16位的数据总线输出RGB或YCrCb格式的图像数据。
在硬件设计上,有2个问题需要解决:
① 图像采集的严格时序同步;
② 双CPU共享SRAM的总线仲裁。
解决第一个问题的关键在于如何实时、准确地读取OV6620的时序输出信号,据此将图像数据写入SRAM中。这里采用的解决方案是用CPLD来实现时序信号的识别以及图像数据的写入。CPLD在硬件上可以识别信号的边沿,速度更快,通过Verilog语言编写Mealy状态机来实现图像数据的SRAM写入,更加稳定。
对于双CPU共享SRAM,可以通过合理的连接方式来解决。考虑到CPLD的可编程性,将OV6620的数据总线,LPC2214的地址、数据总线以及SRAM的总线都连接到CPLD上。通过编程来控制总线之间的连接,只要在软件上保证总线的互斥性,即在同一时刻有且仅有一个控制器(CPLD或者LPC2214)来操作SRAM的总线,就可以有效地避免总线冲突。这样,硬件上的仲裁就可以通过软件来保证,该过程可以通过在CPLD中编写多路数据选择器来实现。
各器件之间的连接关系如图1所示。
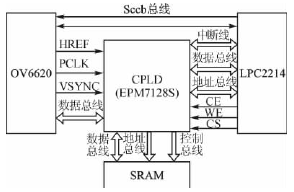
图1 系统结构框图
由图1可见,微处理器的总线接在CPLD上,在对功耗有严格要求的场合中,只需要在CPLD中,将OV6620的同步时序信号所对应的引脚与LPC2214连接在CPLD上的中断引脚相连,系统就可以转换成方案1的形式。对CPLD而言,引脚相连的仅仅是组合逻辑,降低了功耗。方案1的具体工作过程可见参考文献[1]。
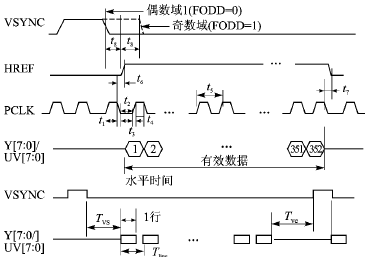
图2 OV6620输出时序图
在Verilog语言中,对上升沿的检测是通过always语句来实现的。例如检测时钟信号cam_pclk的上升沿:
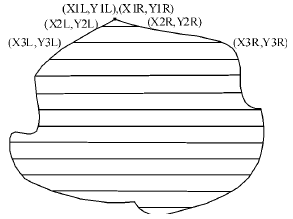
图3 行处理得到的线形图
根据得到的结果,可以计算出更多关于跟踪物体的信息:
① 计算区域面积。计算每条线段的长度l(n),然后将l(n)进行累积叠加,即可获得跟踪区域面积值S。
![]()
② 计算质心横坐标。
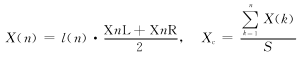
③ 计算质心纵坐标。
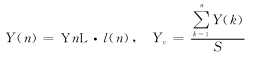
④ 识别物体的形状。根据得到的每行跟踪点的长度,以及同一行中有几段符合要求的连续跟踪点,可以得知物体从摄像头角度看到的形状。特别是在检测平面上线条时,可以识别是否有分支,这一点是帧处理模式无法做到的。
需要指出的是,行处理模式虽然会得到关于跟踪目标的更多信息,但是每行处理的方式增大了处理器的负担,处理速度也没有帧处理快。
4 提高系统的工作速率
目前,系统工作在帧处理模式下的工作速率是25帧/s,作为系统功能的验证,这里采用的算法是颜色跟踪。如果仅做纯粹的图像采集,而不做图像处理,那么系统可以达到OV6620的最高工作速率,即60帧/s。而在图像处理方面,不同的图像处理程序效率对系统的工作频率有较大的影响。下面给出在通用ARM处理器下提高程序效率的几个建议:
① 内嵌(inline)可通过删除子函数调用的开销来提高性能。如果函数在别的模块中不被调用,一个好的建议是用static标识函数;否则,编译器将在内嵌译码里把该函数编译成非内嵌的。
② 在ARM系统中,函数调用过程中参数个数≤4时,通过R0~R3传递;参数个数>4时,通过压栈方式传递(需要额外的指令和慢速的存储器操作)。通常限制参数的个数,使它为4或更少。如果不可避免,则把常用的前4个参数放在R0~R3中。
③ 在for(), while() do…while()的循环中,用“减到0”代替“加到某个值”。比如:
for (loop = 1; loop <= total; loop++) //ADD和CMP
替换为:for (loop = total; loop != 0; loop--) //SUBS
第1种方式比较需要2条指令ADD和CMP,而第2种方式只需一条指令SUBS。
④ ARM核不含除法硬件,除法通常用一个运行库函数来实现,运行需要很多个周期。一些除法操作在编译时作为特例来处理,例如除以2的操作用左移代替余数的操作符“%”,通常使用模算法。如果这个值的模不是2的n次幂,则将花费大量的时间和代码空间避免这种情况的发生。具体办法是使用if()作状态检查。
比如,count的范围是0~59:
count = (count+1) % 60;
用下面语句代替:
if (++count >= 60)
count = 0;
⑤ 避免使用大的局部结构体或数组,可以考虑用malloc/free代替。
⑥ 避免使用递归。
结语
本文介绍了一种基于ARM和CPLD的嵌入式视觉系统,可以实现颜色跟踪。在硬件设计上,图像采集和图像处理分离,更利于系统功能的升级。而视觉处理算法更注重处理的效率和实时性,同时根据不同的需要有两种模式可供选择。最后给出了提高程序效率的一些建议和方法。与基于PC机的视觉系统相比,该系统功耗低、体积小,适合应用于移动机器人等领域。