引言
ARM处理器以其高性能、低功耗、低成本等优势被广泛应用于各种成功的32位嵌入式系统中。提高执行速度和减小代码尺寸是嵌入式软件设计的关键需求。尽管大多数的ARM编译器和调试器都带有性能优化工具,但是为了保证其正确性,编译器必须是稳妥和安全的,而且它还受到处理器自身结构的限制。因此,编程人员必须在理解编译器工作特点的基础上来实现代码优化。代码的优化方法较多,本文针对函数优化方法进行阐述。
1 函数局部变量的数据类型
局部变量包括函数内局部变量、函数参数、函数返回值。由于ARM数据操作都是32位,即使数据本身只需要8位或16位,对于这三类局部变量也应尽可能使用32位的数据类型int或long,以提高代码执行效率。下面以简单求和函数为例进行分析。
函数add1计算包含10个字的数组array的累加和,add2与add1功能相同,只是将函数add1的参数array类型改为16位的short,函数内局部变量i类型改为8位的char,sum改为16位的short。add1、add2的C源代码如下:
int add1(int *array){
unsigned int i;
int sum=0;
for(i=0;i<10;i++)
sum=sum+array[i];
return sum;
}
short add2(short *array){
char i;
short sum=0;
for(i=0;i<10;i++)
sum= sum+array[i];
return sum;
}
add1经编译产生的汇编代码:
add1
mov r2,r0
mov r0,#0
mov r1,#0
add1_loop
ldr r3,[r2,r1,lsl #2]
add r1,r1,#1
cmp r1,#0x0a
add r0,r3,r0
bcc add1_loop
mov pc,r14
add2经编译产生的汇编代码:
add2
mov r2,r0
mov r0,#0
mov r1,#0
add2_loop
add r3,[r2,r1,lsl #1];增加语句①
ldrh r3,[r3,#0]
add r1,r1,#1
and r1,r1,0xff;增加语句②
cmp r1,#0x0a
add r0,r3,r0
bcc add2_loop
mov r0,r0,lsl #16;增加语句③
mov r0,r0,asr #16;增加语句④
mov pc,r14
比较add1和add2两个函数的汇编代码,可以发现add2_loop循环比add1_loop循环增加了4条语句。
语句①:函数add2中变量sum为16位short类型,ARM指令中ldrh指令不支持移位地址偏移,因此增加add指令计算数组下标地址。
语句②:由于函数add2中循环变量i为8位的char类型,而ARM处理器的寄存器为32位,此语句用于处理循环变量累加过程中引起的溢出问题。即:当i累加到255时,再加1应该为0,而不是256。
语句③、④:函数add2中返回结果sum为short类型,在返回前需将32位寄存器的前16位用符号位填充,即转换为16位short类型。
2 函数局部变量的个数
为了加快程序的执行速度,函数编译时应尽可能将局部变量都分配在寄存器中。*部变量多于可用的寄存器时,编译器会将多余的变量压入堆栈(即存入存储器中),因此必须控制局部变量的个数。
ARM处理器采用RISC结构,带有丰富的内部寄存器。在编译器使用apcs开关选项,即支持ATPCS(ARMThumb Procedure CallStandard)标准时,理论上有14个寄存器(R0~R12,R14)可以用来存放局部变量。但是实际上有些寄存器有自身特殊的用途,例如R9在与读写位置无关(RWPI)的编译情况下作为静态基址寄存器使用,R12作为子程序内部调用的临时过渡寄存器使用。ATPCS规则中的寄存器名称及说明如表1所列。
表1 ATPCS规则中寄存器说明
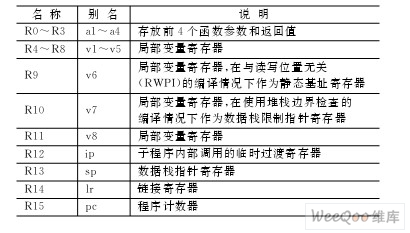
因此,应尽量限制局部变量的数目:①对于函数的参数个数应控制在4个以内,只有R0~R3可用来保存参数,当参数多于4个时将被压入堆栈。如果由于实际应用的需要,参数多于4个,也可以采用结构体来组织参数,传递结构体指针来实现。②函数内部局部变量的个数应控制在12个以内(R0~R11),R12~R15都有特定用途。
3 函数内代码的编写
3.1 循环代码的编写
循环的控制条件设为递减到零的形式,可以减少指令条数。以求10个数的累加和为例进行分析。
代码1:
int sum=0;
for(int i=0;i<10;i++)
sum=sum+i;
代码2:
int sum=0;
for(int i=10;i!=0;i--)
sum=sum+i;
汇编代码1:
mov r0,#0
mov r1,#0
add1
add r1,r1,#1
cmp r1,#0x0a
add r0,r1,r0
bcc add1
汇编代码2:
mov r0,#0
mov r1,#0x0a
add2
subs r1,r1,#1
add r0,r1,r0
bne add2
比较代码1和代码2,两者的功能是相同的,但是代码2在循环中少了1条指令。该循环的执行次数为10次,即在执行时共减少了10条指令。
3.2 内联函数的使用
当函数体代码较少(通常只有一两条语句),且又被经常调用时,可将它设为内联函数(inline)。对内联函数的调用类似于宏定义的展开,因此没有函数调用的开销(即参数的传递和函数值的返回),只是增加了被调用函数的代码量。
例如在嵌入式系统中,经常访问的外设端口的读写代码就可以设成内联函数,以提高执行效率。外设寄存器的读写函数如下:
inline unsigned short reg_read(unsigned short reg){
return (unsigned short)*(volatile unsigned short *)( reg);//外设寄存器的读函数
}
inline void reg_write(unsigned short reg, unsigned short val){
*(volatile unsigned short *)(reg)=val;//外设寄存器的写函数
}
这两个函数的共同特点是:函数体的代码很少,只有1个语句;使用的局部变量很少,只有1~2个参数。由于定义为内联函数,程序的可读性较好;在执行时由于没有调用开销,执行效率较高;函数体很小,在被展开时空间开销不大。
结语
由于嵌入式系统对存储空间的限制和实时性的需求,在编写代码时必须采用相应的方法和原则以减少代码的空间开销和时间开销。代码优化需要花费时间,并且代码优化后将降低源代码的可读性。因此,只有对经常被调用且对性能影响较大的函数进行优化,才能最有效地优化系统。