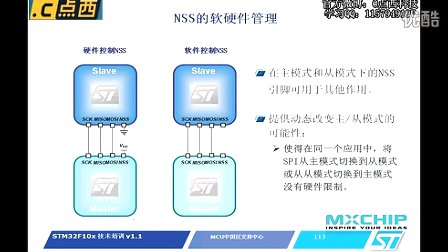
能从PC机器编程去看嵌入式问题,那是第一步;学会用嵌入式编程思想,那是第二步;用PC的思想和嵌入式的思想结合在一起,应用于实际的项目,那是第三步。很多朋友都是从PC编程转向嵌入式编程的。在中国,嵌入式编程的朋友很少是正儿八经从计算机专业毕业的,都是从自动控制啊,电子相关的专业毕业的。这些童鞋们,实践经验雄厚,但是理论知识缺乏;计算机专业毕业的童鞋很大一部分去弄网游、网页这些独立于操作系统的更高层的应用了。也不太愿意从事嵌入式行业,毕竟这条路不好走。他们理论知识雄厚,但缺乏电路等相关的知识,在嵌入式里学习需要再学习一些具体的知识,比较难走。
从事嵌入式行业的工程师,要么缺乏理论知识,要么缺乏实践经验。很少两者兼备的。究其原因,还是中国的大学教育的问题。这里不探讨这个问题,避免口水战。我想列出我实践中的几个例子。引起大家在嵌入式中做项目时对一些问题的关注。
01
第一个问题:
同事在uC/OS-II下开发一个串口的驱动程序,驱动和接口在测试中均为发现问题。应用中开发了个通讯程序,串口驱动提供了一个查询驱动缓冲区字符的函数:GetRxBuffCharNum()。 高层需要接受一定数量的字符以后才能对包做解析。一个同事撰写的代码,用伪代码表示如下:
bExit = FALSE;
do {
if (GetRxBuffCharNum() >= 30)
bExit = ReadRxBuff(buff, GetRxBuffCharNum());
} while (!bExit);
这段代码判断当前缓冲区中超过30个字符,就将缓冲区中全部字符读到缓冲区中,直到读取成功为止。逻辑清楚,思路也清楚。但这段代码是不能正常工作。如果是在PC机上,定然是没有任何问题,工作的异常正常。但在嵌入式里真的是不得而知了。同事很郁闷,不知道为什么。来请我解决问题,当时我看到代码,就问了他,GetRxBuffCharNum()是怎么实现的?打开一看:
unsigned GetRxBuffCharNum(void)
{
cpu_register reg;
unsigned num;
reg = interrupt_disable();
num = gRxBuffCharNum;
interrupt_enable(reg);
return (num);
}
很明显,由于在循环中,interruput_disable()和interrupt_enable()之间是个全局临界区域,保证gRxBufCharNum的完整性。但是,由于在外层的do { } while() 循环中,CPU频繁的关闭中断,打开中断,这个时间非常的短。实际上CPU可能不能正常的响应UART的中断。当然这和uart的波特率、硬件缓冲区的大小还有CPU的速度都有关系。我们使用的波特率非常高,大约有3Mbps。uart起始信号和停止信号占一个比特位。一个字节需要消耗10个周期。3Mbps的波特率大约需要3.3us传输一个字节。3.3us能执行多少个CPU指令呢?100MHz的ARM,大约能执行150条指令左右。结果关闭中断的时间是多长呢?一般ARM关闭中断都需要4条以上的指令,打开又有4条以上的指令。接收uart中断的代码实际上是不止20条指令的。所以,这样下来,就有可能出现丢失通信数据的Bug,体现在系统层面上,就是通信不稳定。
修改这段代码其实很简单,最简单的办法是从高层修改。即:
bExit = FALSE;
do {
DelayUs(20); //延时 20us,一般采用空循环指令实现
num = GetRxBuffCharNum();
if (num >= 30)
bExit = ReadRxBuff(buff, num);
} while (!bExit);
这样,让CPU有时间去执行中断的代码,从而避免了频繁关闭中断造成的中断代码执行不及时,产生的信息丢失。在嵌入式系统里,大部分的RTOS应用都是不带串口驱动。自己设计代码时,没有充分考虑代码与内核的结合。造成代码深层次的问题。RTOS之所以称为RTOS,就是因为对事件的快速响应;事件快速的响应依赖于CPU对中断的响应速度。驱动在Linux这种系统中都是与内核高度整合,一起运行在内核态。RTOS虽然不能抄袭linux这种结构,但有一定的借鉴意义。
从上面的例子可以看清楚,嵌入式需要开发人员对代码的各个环节需要了解清楚。
01
第二个例子:
同事驱动一个14094串转并的芯片。串行信号是采用IO模拟的,因为没有专用的硬件。同事就随手写了个驱动,结果调试了3、4天,仍旧是有问题。我实在看不下去了,就去看了看,控制的并行信号有时候正常有时候不正常。我看了看代码,用伪代码大概是:
for (i = 0; i < 8; i++)
{
SetData((data >> i) & 0x1);
SetClockHigh();
for (j = 0; j < 5; j++);
SetClockLow();
}
将数据的8个bit在每个高电平从bit0到bit7依次发送出去。应该是正常的啊。看不出问题在哪啊?我仔细想了想,有看了14094的datasheet,明白了。原来,14094要求clock的高电平持续10个ns,低电平也要持续10个ns。这段代码之做了高电平时间的延时,没有做低电平的延时。如果中断插在低电平之间工作,那么这段代码是可以的。但是如果CPU没有中断插在低电平时执行,则是不能正常工作的。所以就时好时坏。
修改也比较简单:
for (i = 0; i < 8; i++)
{
SetData((data >> i) & 0x1);
SetClockHigh();
for (j = 0; j < 5; j++);
SetClockLow();
for (j = 0; j < 5; j++);
}
这样就完全正常了。但是这个还是不能很好移植的一个代码,因为编译器一优化,就有可能造成这两个延时循环的丢失。丢失了,就不能保证高电平低电平持续10ns的要求,也就不能正常工作了。所以,真正的可以移植的代码,应该把这个循环做成一个纳秒级的DelayNs(10);
像Linux一样,上电时,先测量一下,nop指令执行需要多长时间执行,多少个nop指令执行10ns。执行一定的nop指令就可以了。利用编译器防止优化的编译指令或者特殊的关键字,防止延时循环被编译器优化掉。如GCC中的__volatile__ __asm__("nop;\n");
从这个例子中可以清楚的看到,写好一段好代码,是需要很多知识支撑的。你说呢?
这真的是一个充满挑战的领域。