摘要:介绍了基于ARM+DSP架构的嵌入式机器视觉系统的特性,分析了制约嵌入式机器视觉系统性能的因素。从操作系统和应用程序方面,讨论了嵌入式机器视觉系统的优化方案。通过对嵌入式Linux内核和文件系统进行裁剪,对应用程序代码进行大量的优化,并充分利用Cotex —A处理器独有的NEON加速技术,使系统开机启动时问缩短25 s,应用程序运行速度提高2.5倍。
关键词:嵌入式;机器视觉;优化;ARM;NEON
嵌入式系统是以应用为中心,以计算机技术为基础,并且软硬件可裁剪,适用于应用系统对功能、可靠性、成本、体积、功耗有严格要求的专用计算机系统。嵌入式机器视觉系统是指用嵌入式计算机处理由光学传感器接收到的图像信息,以实现对物体的检测和识别的装置,如数码相机、手持二维码识别设备,体感交互游戏机等。由于机器视觉系统需要进行大量复杂的数据运算,因此目前大多数的机器视觉系统还是基于PC系统构建,但随着近年来嵌入式系统的高速发展,嵌入式机器视觉系统越来越多地应用于工业检测与控制、智能交通、安防、医疗器械、机器人导航及消费电子等领域。
嵌入式机器视觉系统的性能主要取决于硬件和软件两方面。目前应用于嵌入式机器视觉系统的硬件平台主要有Intel基于x86架构的Atom平台、TI基于ARM—DSP的OMAP系列平台、NVIDIA基于ARM—GeForce的Tegra系列平台、IBM等基于PowerPC的处理平台等,其中ARM—DSP是一种高性价比的、应用广泛的体系结构。除了硬件平台之外,嵌入式操作系统的选择对机器视觉系统的性能也很重要,如开机时间,系统稳定性等。嵌入式操作系统的种类比较多,其中较为流行的主要有μC/OS、Windows CE、VxWorks、Android、iOS、Meego、QNX和Linux等。在诸多嵌入式操作系统中,Linux以其内核稳定、支持多种硬件平台、完全免费、源代码完全开放、可裁剪定制、易于移植的特性,成为大多数厂家的绝佳选择。此外,由于嵌入式机器视觉系统具有处理数据量大,算法复杂的特点,对嵌入式机器视觉应用程序的优化也至关重要。
文中以采用ARM—DSP结构的Beagleboard—xM开发板为例,构建了用于目标检测跟踪的嵌入式机器视觉系统,从操作系统和机器视觉应用程序方面对系统进行优化,并充分利用Cotex—A处理器的NEON加速技术,显著提高了嵌入式机器视觉系统的性能。
1 系统软硬件组成
文中所采用的嵌入式机器视觉系统的硬件组成如图1所示。其中DM3730处理器是由TI生产的单片系统(SoC)处理器,采用了POP(Package on Package)封装技术,内含1G主频的ARM Cortex—A8,主频800 M的TMS320C64+内核和512 M的LPDDR内存。该处理器有较强的多媒体图像、视频处理能力,特别适合于构建嵌入式机器视觉系统。Beagleboard—xM没有Flash,系统是从MicroSD卡启动的。PMIC为电源与音频管理模块,它通过McBSP总线与处理器连接。摄像头和以太网数据通过USB接口传给处理器,处理器运行目标检测与跟踪程序,并将处理结果送到LCD显示。Minicom用于和上位机进行通讯,便于调试。
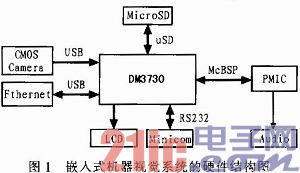
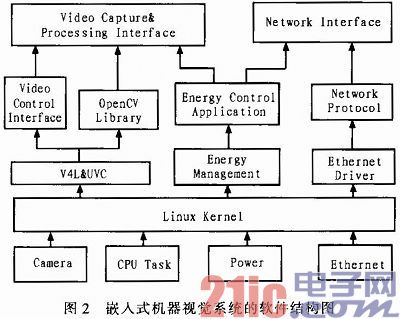
图2为系统的软件结构图。在嵌入式Linux内核中包含了对CPU、USB摄像头、电源管理设备及USB以太网等的驱动支持。其中V4L是Linux内核中关于视频设备的API接口,UVC(USB Video Class)是为USB摄像头提供即插即用功能的驱动模块,在此基础上将开源的跨平台机器视觉库OpenCV2.2移植到了嵌入式平台上,并在应用程序中实现对视频信号的采集和处理。
2 嵌入式LinuX操作系统优化
嵌入式系统硬件资源较为有限,作为以应用为中心的专用计算机系统,需要对其在启动速度、实时性、系统尺寸、电源管理等方面进行优化。近年来,Linux凭借其优良特性广泛地应用于嵌入式系统。但是,作为一种原本为PC机设计的操作系统,设计者开始并没有考虑嵌入式应用对启动速度的要求,导致其典型的启动时间一般在几十秒或以上,这对用户来说是不能容忍的。此外,随着Linux内核的不断膨胀,启动时间越来越长。因此,加快启动速度已经成为嵌入式Linux系统亟待解决的关键问题之一。
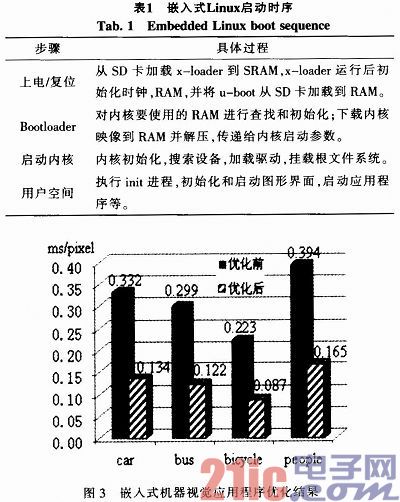
由于成本的考虑,Beagleboard—xM平台没有Flash,它是从MicroSD卡启动的。嵌入式Linux系统启动时序如表1所示。系统上电后,内部ROM程序会从SD卡加载x—loader到SRAM。x—loader负责初始化系统(如时钟、RAM等),并将u—boot从SD卡中加载到RAM。u—boot负责将内核镜像从SD卡加载到RAM中。内核解压并运行,挂载文件系统,执行init进程,登录系统,最终完成系统的启动。编写perl脚本记录串口输出的时间,开机启动过程各部分耗时如图3所示。在系统启动过程中,内核解压与运行时间、系统自启动项加载时间占了整个系统启动的大部分时间。
本文对嵌入式Linux操作系统采取的优化策略如下。
1)修改并重新编译u—boot源码,取消开机3 s等待时间
系统会检测在开机等待时间内用户按钮是否被按下,如果被按下,则可以进行设置系统环境变量,修改启动选项等操作。这里可以跳过这一步,减少开机时间。
2)裁剪内核中不必要的功能部分
嵌入式Ldnux操作系统内核中除了进程管理、内存管理、任务调度等核心部分外,还提供了多种文件系统、网络、硬件驱动、内核调试等功能模块,但它们并非必不可少,例如手持移动终端通常不需要NTFS等文件系统,也不需要RAID和SCSI设备支持。所以,根据嵌入式系统应用的具体需求配置Linux内核才能减小Linux内核的静态映像体积,同时也能够相应减少这些功能模块运行时间的开销。
3)采用“-Os - mthumb”编译选项进行优化以减小内核镜像大小
-Os是gcc优化选项中最深层次的优化,相当于是对代码进行了-O2的优化,但不增加代码尺寸。-mthumb表示使用16位短指令集,它具有更高的代码密度,即占用存储空间小,仅为32位ARM代码规格的65%,但其性能却下降的很少。
4)去掉内核打印输出
Linux系统启动时,一般使用串口控制台或VGA控制台打印内核启动信息,打印速度取决于串口的速度和处理器的速度,这在大多数嵌入式系统中要用数百毫秒的时间。
5)用buildroot构建轻量级的根文件系统
常用于构建根文件系统的工具有OE(OpenEmbedded)和buildroot等。OE是重量型的交叉编译系统工具,可以用来构建复杂的根文件系统,但配置和定制过程难度很大,而且要耗费约20 G的硬盘空间和十几个小时的编译时间。buildroot则是一个相当小巧灵活的交叉编译工具,用它定制和调整软件包十分方便,而且buildroot提供了类似Linux kernel配置采用的配置菜单,易于使用。
6)桌面环境使用X11而非Gnome或KDE
X11即X Window系统,它是一种可以用于Unix和类Unix操作系统的位图显示视窗系统。Gnome和KDE是两种相对复杂的桌面环境。对于嵌入式机器视觉系统,如果用户界面不追求华丽,可以使用更为简洁的X11,以及简单的桌面管理器twm。
7)禁用或暂缓启动某些启动项
为了加速启动,可以禁用不必要的启动项,甚至一些必要的启动项可以在系统完成登录后再启动。具体可以通过修改/etc/init.d/下自启动项快捷方式名称的方法实现。
$cd/etc/init.d/
$mv S20network K20network
当系统完成开机启动后再启动该项目,可以用如下命令:
$K20network start
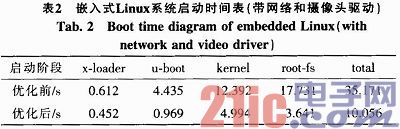
如表2所示,经过优化后,内核镜像大小由3.046 MB减小到2.797 MB,系统的启动时间(从复位到开启应用程序)由35.171 s缩短到10.056 s,基本满足实际应用的需要。嵌入式Linux操作系统优化取得了明显的效果。
应用在移动载体上的嵌入式机器视觉系统通常对能耗也有较高的要求。Beagleboard—xM是一款功耗较低的产品,不需要风扇冷却。电源管理主要是由PMIC模块实现的。另外,通过更改系统的显示设置,如屏保时间、待机时间等,来降低能耗。
3 应用程序优化
机器视觉系统往往涉及大量复杂的计算,大多采用C/C++等高效率的语言进行开发。嵌入式系统对应用软件的质量要求很高,在嵌入式开发中须注意对代码进行优化,尽可能地提高代码效率。本文从算法、代码效率以及处理器的特性等方面出发,为开发高效率嵌入式机器视觉应用程序提供了些经验。
3.1 选择合适的算法
在机器视觉算法优化过程中,速度和内存不可兼得,要想得到较快的运行速度必须适当增加内存空间的使用量。例如,在JPG图像有Huffman编码表,从YUV到RGB的变换也有变换表,本文计算梯度方向直方图HOG时需要用到18个方向的三角函数。这些运算原本较复杂,采用查表的方法之后,虽然占用了内存,但显著提高了运行速度。
3.2 代码效率的优化
代码效率优化的前提是要保证程序结果的正确性,在此基础上对空间复杂度和时间复杂度进行调整,以达到性能的提升。代码效率优化可以采用多种方法。
1)采用较短的数据类型
本文实验中浮点数据类型用float代替double,目标检测结果基本不变,但是运算量和所占用内存空间都相应减少。
2)switch语句优化
对于switch语句,编译器是按照顺序进行条件比较,发现匹配时,就跳转到满足条件的语句执行。为了提高速度,可以把发生频率较高的条件放在前面。
3)用指针代替数组
在许多情况下,可以用指针运算代替数组索引,编译后常常能产生又快又短的代码。与数组索引相比,指针一般能使代码速度更快,占用空间更少,这在使用多维数组时差异更明显。
4)用宏函数取代函数
函数和宏函数的区别就在于,宏函数占用大量的空间,而函数占用了时间。当函数被多次调用时,会反复进行压栈和弹栈操作,从而消耗一些额外的时间。使用宏函数不会产生函数调用,所以仅仅占用了空间,不会增加额外的运行时间。
5)循环优化:采用循环合并与循环展开
当两个循环的负荷都不满时,可以把它们合并在一起组成一个循环。循环展开就是把循环计数小的循环展开,成为非循环形式的串行程序,或者把循环计数大的循环部分展开,减少循环迭代次数,这样可以节省用于循环设置、初始化、增加和校对循环计数器的时间。
6)采用Inline函数
在C++中,当函数前加关键字Inline的声明,编译器会用函数内部的代码替换所有对该函数的调用。这样可以省去调用函数指令需要的执行时间以及传递变元和传递过程需要的时间。通常,这种优化在Inline函数被频繁调用并且只包含较短代码的时候最有效。
7)使用增量和减量操作符
在用到自增和白减运算时应尽量使用增量和减量操作符,因为增量符语句比赋值语句更快。
3.3 充分利用处理器特性进行加速
ARM+DSP的组合在嵌入式开发中堪称理想架构。DSP可专门用于处理密集型信号处理需求、复杂的数学函数以及图像处理算法,而ARM则可用于实现图形用户界面、网络连接及系统控制等。上面的代码优化措施是通用的方法,如果针对处理器的特性对程序进行优化,可以得到更好的优化效果。
1)利用开发工具对DSP程序进行优化
有很多算法在DSP平台可以实现,在ARM上也可以,但有些特定算法,如滤波、视频编解码等放在DSP上运行的效率较高。以往的开发中对DSP程序的优化更多是汇编程序的优化,但用汇编语言做开发和优化往往费时又费力。但是随着开发工具的更新,现在的C代码优化效率可达到手工汇编的90%。TI提供的C6EZRUN工具可以使开发人员能在DSP上运行ARM代码,而无需修改,并且从ARM到DSP代码的转换效率非常高。TI的另一个开发工具C6EZAccel则提供了一个包括数百个DSP优化型信号处理算法的程序库,通过ARM API加快开发进度。开发人员可以将更多的精力投入到算法设计中。
2)充分利用ARM处理器的NEON技术进行加速
ARM高级单指令多数据(SIMD)扩展亦称NEON技术,它是一种由ARM开发的64/128位混合SIMD体系结构,可以提升多媒体和信号处理应用程序的性能。其关键功能包括对齐和未对齐数据访问,支持整型定点和单精度浮点数据类型、与ARM核心的紧密耦合,以及具有多个视图的大型寄存器文件。NEON指令在ARM和Thumb-2中都可用。要生成NEON指令,必须在命令行中指定采用NEON技术的Cortex处理器。ARMv7之前的体系结构不提供NEON支持。如果要对进行优化,需要增加编译选项“-mcpu=cortex-a8-mfpu=neon”。
3.4 应用程序优化结果
在嵌入式实时程序设计时可以运用上面介绍的一种或多种方法来优化代码。以上方法主要是为了提高代码的执行效率,但会增加代码长度,降低可读性。在嵌入式程序设计中应合理地使用这几种技术以达到较好的优化效果。
运用上述方法,对基于HOG特征的物体检测算法进行优化,运行时间如图3所示。该算法是目前公认的准确率最高的目标检测算法。对汽车、大巴、自行车、行人的检测结果如图4所示。考虑到该算法的复杂性以及检测精度的要求,我们采用的是浮点数优化。结果表明,经过优化后程序运行速度约为原来的2.5倍。

4 结束语
随着嵌入式系统的高速发展,嵌入式机器视觉系统的应用也越来越广泛。如何把运算量大、算法复杂的机器视觉应用程序移植到嵌入式平台上并进行优化设计是重要的课题。本文针对嵌入式机器视觉系统的特点,在操作系统方面对内核和文件系统进行了精简,在应用程序方面做了大量的优化,并充分利用Cotex—A处理器的NEON加速技术,显著提高了嵌入式机器视觉系统的性能,对嵌入式机器视觉系统的开发具有借鉴意义。