引 言
1946年,第一台电子计算机的诞生开创了计算机发展的新纪元。随着计算机科学技术的迅速发展,计算机的应用领域越来越广泛,并逐渐形成科学发展中的一个新的分支。在计算机的主要工作中,处理大量的数据是其一项基本功能;因而数据运算是必不可少的。于是人们设法在硬件设计与数据结构方面努力进行工作[1],使计算机的速度不断提高。
十几年前,单片微型机脱颖而出,逐渐应用于微型计算机的各个领域,它不仅适用于一般的自动控制,而且还可以承担高精度的数据处理工作。诚然,在许多系统中近来采用DSP来提高微机的数据处理能力,以便完成复杂的图像处理、音频处理、网络通讯等功能,而且是一个趋势;但在这些系统中仍不可忽视运算程序的执行速度,因为好的算法可以大大提高程序的执行效率[2]。同时,考虑到目前8BITMCU的主导地位及某些系统不适合配置DSP来进行数据处理[3]。因此,这里仍有必要对高精度高速度的浮点多字节运算进行进一步研究。
1浮点多字节标准乘法
普通的计算机都采用标准的加法-移位技术来实现乘法,Mowle曾经对这些基本的乘法算法和问题作了详细的描述[4]。对于二进制数A,B来说,设其数值为AV,BV
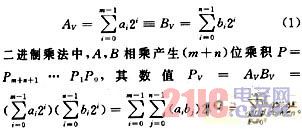
由此原始矩阵乘法产生了标准的移位加算法[5,6]。一般的标准浮点乘法运算分为阶码运算与尾数运算两部分,其主要部分为尾数运算。标准尾数相乘是采用边乘边相加的办法(即加法-移位)来实现的,即乘数向左移位,产生中间结果,中间结果被加至积区的方法;在整个过程中,积也与乘数一起移位。此过程如图1所示。上述方法对于两个n位二进制尾数的相乘结果,即乘积为2n位,也就是部分积要点n位,在运算过程中,这2n字节都有可能要有相加的操作,需2n个字节加法器。对于标准算法,相当于进行了8n次2n字节的移位,还有![]() 次2n字节的加法。其中Pj(bj)为其每个bit位的布尔取值,其为1则取1,反之则为0。
次2n字节的加法。其中Pj(bj)为其每个bit位的布尔取值,其为1则取1,反之则为0。
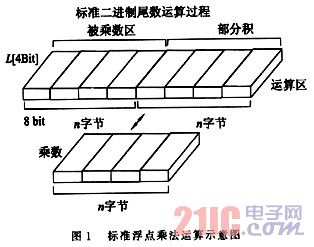
为了节省运算时间,标准乘法应用标准右移乘法方法以便减少加法器的数量,有关这方面的具体论述请参见文[2]。
2扫描乘法的基本原理
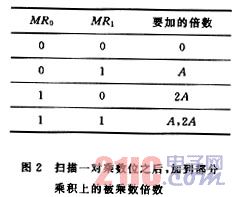
在执行乘法指令时,如果每个周期所检查的乘数位多于一位,乘法的速度便可以加快。例如,每次检查二位,那么加法移位周期的总数就可以减半。这些逐次扫描的位组可以是分离的,也可以是重叠的。这里先简述一下分离扫描的原理。对于乘数来讲是以字节为单位的,其字长按二进制BIT来计是偶数,设被乘数A=(AX),乘数B=(MR);则在扫描了最低一对乘数位(MR1,MR0)后,有四种可能的动作,如图2所示。对于m=(MR1,MR0)2来说,被乘数A的倍数m×A被加到当前的部分乘积上,用来生成下一个部分积。上述原理可以推广到任意大小的扫描位组,其具体实现方法和分析结果请参见文[2],这里不再叙述。
以上所描述的是分离扫描的情况,下面再介绍重叠多位扫描的情况。一般在乘数中bj为0的个数越多,则程序运行的时候对为0的情况仅仅是移位越过,而不用作加法的运算,在此种情况下的运算相对加快。因此希望对乘数的bj能否进行适当的操作,使这之在bj为1的区域也能使运算时间减少。
现考虑乘数中有一串k个连续的1,如下
列的位置…,i+k,i+k-1,i+k-2,…,i,i-1,…
列的内容…,0,1,1,…,1,0,… (2)

按常规,在移位加时,被乘数A与部分积要进行k次加法操作,但是存在
2i+k-2i=2i+k-1+2i+k-2+…+2i+1+2i (3)
因此可以用下面的数符串来代替k个连续的1
列的位置…,i+k,i+k-1,i+k-2,…,i,i-1,…
列的内容…,1,0,0,…,-1,0,… (4)
上面的-1表示执行一次减法。利用这种乘法再编码的方法,只要在数字串开始时作一次加法,结束时作一次减法,使这能够代替原来的k次连续加法。显然,当k很大时,能节省大量的加法时间。
为了方便扫描,乘数位仍按二位一组分成许多组,但一次扫描三位,二位来自现在的组,第三位来自下一次高次组的低位,实际上每一组的低位被检测了二次。为了与右移算法取得一致,假定扫描乘数从右端到左端,重叠和非重叠两种扫描模式表示见图3。
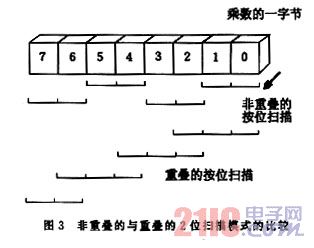
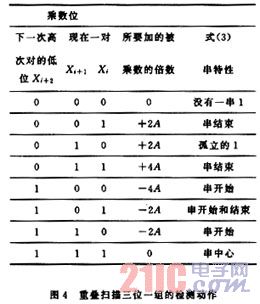
设扫描组XR=[Xi+1,Xi]2;下一扫描组XR′=[Xi+3,Xi+2]2;每三位一组检测后的动作说明见图4。其指出了每个机器周期或执行一次单纯的移位,或者执行一次加法,或者执行一次减法,这里只需要倍数2A或4A。当下一对的低次位xi+2为0时,三位中最左边的1经常指示一串1的左端(结束)。依式(3)所描述的特性,在具有非零的乘数位时应该执行加法。另一方面,当xi+2=1 时,即意味着是一串1的右端(开始)或中心,按照串特性需要作一次减法,在每个加法周期中,部分乘积每次要右移二位。这就使部分乘积比它应该具有的数值少了4倍被乘数(-4A)。这可以用在下一步扫描中加上所需被乘数的倍数与4倍数的差值来校正。倍数2A或4A进入加法器的地点是重要的。如果一对的尾数是 0,那么所得到的部分乘积是正确的,而且下一次的操作是一次加法。如果一对的结尾是1,则所得到的部分乘积太大,所以下一次操作将是一次减法。
3单片机重叠扫描乘法运算的实现
从以上原理可知,针对二位一组的情况需要五个被乘数的倍数,其数值可取为0,±2A,±4A。由于其每移二位至多操作一次加减法,在多字节的运算中对提高执行效率有很大的益处;不过考虑到8BITMCU的移位操作并没有二位一移的指令,对这种扫描算法有很大的障碍,必须重新考虑扫描运算如何在微型机上进行实施。
根据文[2],MCU对字节与半字节操作的指令较强,因此可以在扫描算法的基础上扩展其扫描位组,这样在每个加法周期中的运算变得很复杂,因此首先必须研究清楚这种情况。
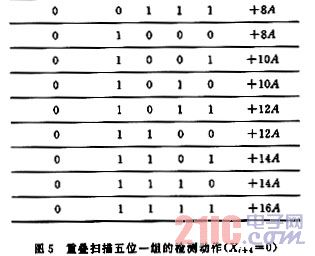
将乘数位按4BIT分成一组,一次扫描五位;设本组为BMi=[Xi+3,Xi+2,Xi+1,Xi],下一次要扫描的BMi′的低位为Xi+4;这样在扫描过程中的情况与文[3]所介绍的情况有类似之处,但这里进行运算的次数不但与BMi有关,同时下一次扫描的低位对本算法也有重大的影响作用。假定在运算数中0,1的概率出现机会均等,对4位一组的扫描进行分析。根据重叠扫描算法的原理,BMi′低位为0时(如图5所示),组中最左端的1指示一串1的左端(结束)。依据式(3),很容易得到每次扫描部分积所要加的被乘数倍数(见图5),可以得到其倍数,即相加的倍数
Pj={BMi-2G[BMi/2]}A+BMi.A=2(BMi-G[BMi/2])A (5)
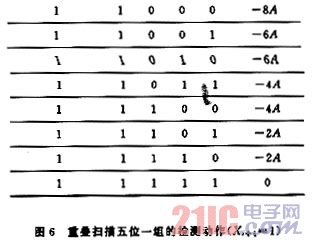
其中G[]为取整函数。Pj实质上均与2A有关,这一点从图中可以看到。如果一组的结尾是零,那么所得到部分乘积是正确的,按正常操作;如果一组的结尾是1,那么所得的部分积同上一次扫描有关;所以此时只是在扫描第一组时做一下记录,在最后完成时针对它在最尾端减一次A即可。这一点对于BMi′低位为1时也成立。其部分积加的情况如图6所示。
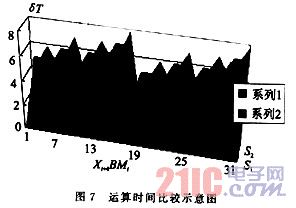
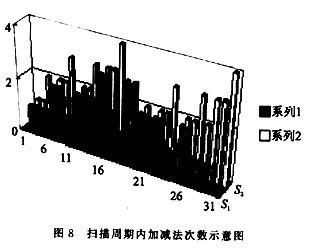
区别只是改加为减,因为部分积的减值在以后的扫描中可以修正回来,不用采用补码的运算也能完成,最常用的方法是设置辅助运算区,采用临时记录的方式保证其部分积在扫描任一周期保持正确结果,也称为临时扩展方法,这里就不重复。这样,在每次扫描仅剩下一个问题,即如何处理Pj,这里Pj与文[3]中处理的方法有类似之处。以2A为基础,将Pj形成一个加(减)法序列,也就是将Pj变为2qA的序列,如12A=22A+23A。这样就可以在一个扫描周期完成部分积的加法。这里建议读者去探索Pj更好的形成方法,因为形成2qA的序列,1≤q≤3,要占用时间(24A可以通过半字节操作做左端拼加处理,因为24A相当于A左移半字节,运算时直接依靠辅助运算区),同时在特殊处理上也额外占有一些运算时间,这一点在图7中也可以看出来。这样一来,在Pj的加法过程中,扫描算法在某些BMi值上并不都占优势,这一点在图5,6中也可以体现(BMi中Xi+3,Xi+2,Xi+1,Xi为1的个数决定了在标准算法中的加法次数);但重叠扫描毕竟节省了时间,其与标准算法在一个扫描周期内的加法次数情况如图8所示(其中系列1为重叠扫描算法,系列2为标准算法)。加之在移位中节省的时间,重叠扫描全过程的运算时间与标准右移算法的比较情况如图8所示(S1为重叠扫描算法,S2为标准算法)。在局部区域,由于采用上述的Pj处理方法,运算时间节省情况还不甚理想,但在总体上还是有很大的改进。
4 结 论
以上介绍的是重叠均匀移位扫描算法,前面谈到重叠非均匀移位扫描算法,有关这种算法的详细介绍请参见其他文献。
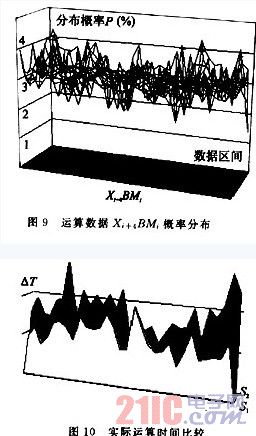
在以上过程中,是假定BMi中的Xi+3,Xi+2,Xi+1,Xi值的1,0分布服从自然概率,然而在运算中由于Xi+4的作用,在对某区间数据进行操作时存在差异,通过对一些运算区间的数据进行了统计,其Xi+4与BMi值的分布概率如图9所示;以实际的一组分布来验证重叠算法运算时间的缩短情况,如图10所示(S1为重叠扫描算法,S2为标准算法;图中前面为S1,后面阴影为S2)。可以看到重叠扫描法对浮点多字节乘法运算有很大的改进,它打破了移位加法的传统乘法算法,有了算法的预测功能,提高了乘法运算的速度。本算法在某军工项目中得到应用,效果很好。
参考文献
1黄凯.计算机算术运算原理、结构与设计.北京:科学出版社,1980.106~110
2陈宇,王遵立.MC-51单片微型机上实现的快速扫描浮点乘法运算.数据采集与处理,1992,(9):151~153
3陈宇,毕淑艳,王遵立,等.MCS-51单片机实现的快速浮点多字节BCD乘除运算.电子技术应用,1998,(2):17~19
4Chen T C.A binary multiplication scheme based onsquaring.IEEE Trans Comput,1971,C-20(6):678~680
5Booth A D.A signed binary multiplication technique.Quart Journ Mech and Appl,Math,1951,4(2):236~240
6Garner H L.A ring model for the study for a binarymultiplier using 2,3 or 4-bit at a time.IEEE Trans,1959,EC-80(1):25~30