摘要:描述了一种基于消息机制构建的片上多处理器系统。该系统采用主从结构,运用消息进行通信,并且从处理器之间彼此相互独立,在硬件结构与软件设计上保持一致。这样不仅简化了系统的设计,更使得系统具有一定的容错性与稳定性。最后在Quartus软件中设计并且综合,在该系统下运行JPEG编码算法,当运行于100 MHz时,测得系统在不同个数处理器时的处理性能,满足了设计要求。
关键词:多处理器;消息机制;FPGA;DMA
引言
如今,数字处理技术已得到了广泛的应用,各种复杂算法的提出与处理精度的提高,都使得需要处理的数据量变得越来越大。而提高系统处理性能主要有提高处理器的频率、采用多处理器系统2种方法。在单处理器频率提升达到瓶颈的情况下,多处理器系统成为提高系统性能的一种有效方式。
近年来,多处理器系统的应用已经越来越广泛,但大部分的多处理器系统都是针对特定的应用对象进行设计,这类系统耦合度高,任务分解充分,执行效率高。同时,这类系统开发难度较大,针对性强,不具有通用性,且当系统中的某个处理器出现问题时,整个系统将面临崩溃。为了简化系统设计,提升多处理器系统的稳定性,本文提出了一种基于消息机制构建的多处理器系统。该系统采用主从结构,主处理器运行管理系统,从处理器完成用户指定的任务。从处理器彼此之间相互独立,可相互替代,并在硬件结构与软件设计上保持一致。这样不仅简化了系统的设计,更使得系统具有一定的容错性与稳定性。实验结果表明,本设计达到了预期效果。
1 多处理器系统体系结构
本文所设计的多处理器系统体系结构框图如图1所示,它主要包括一个主控制器模块及多个从处理器模块。
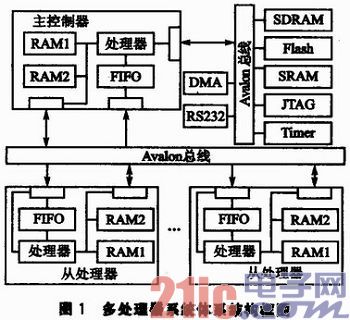
主控制器主要负责消息的分配与跟踪,控制DMA进行数据的快速移动等。从处理器则根据主控制器分配的任务执行相应的处理。系统上还集成了多种系统外设,如RS232、定时器、JTAG接口、多种存储控制器等。
主控制器模块及从处理器模块中使用的处理器是Nios Ⅱ嵌入式软核处理器,选用的是快速型。该处理器是Altera公司推出的32位RSIC嵌入式处理器,可根据需要配置为快速、标准、经济3种类型,提供满足性能与成本的最佳方案。每个模块中都配备1个FIFO,用于存储消息;配备2个RAM存储器,组成乒乓结构,用于存储原始数据或结果数据,同时可用于DMA传输控制。
主控制器模块与多个从处理器模块构成主从结构。主控制器集中管理所有的从处理器模块;所有的从处理器模块相互独立,互不影响,运行时可相互替代。主控制器模块与系统的所有外设及所有的从处理器模块都是通过Avalon总线相互连接。该总线是一种协议较为简单的片内总线,处理器可通过该总线与外界进行数据交换。
2 通信机制的设计
在本文所设计的系统中,各个模块之间都采用消息进行通信,如主控制器与从处理器之间的通信、处理任务的分配、处理结果的反馈等。对于数据的传递,如果数据量比较小,可以把数据附在消息中进行传递;如果数据量比较大,则用DMA进行存储器到存储器之间的快速移动。
2. 1 消息结构的设计
消息是该系统的通信基础,也是系统运行的重要环节,因此定义一种结构通用又易于识别的消息结构显得十分重要。在该系统中,采用的是可变长度的消息结构:{类型;长度;子类型;参数1;参数2;…;参数N}。
其中长度指的是其后的数据个数,不包括类型及自身。这样处理有利于消息的传递与读取。在消息结构中,类型、长度、子类型这3个字段在消息中的位置固定,有利于消息的解析。如根据消息中的类型与子类型字段,可快速转到相应的处理函数进行处理,根据长度字段,可准确地判断消息中参数的个数;将“子类型”排在“长度”之后,则有利于消息的读取。
2.2 消息的传递
消息的传递过程就是向目标消息存储器FIFO写入消息数据的过程。由于系统采用的是主从结构,当消息在控制器与处理器之间的不同方向传递时,传递过程并不相同。
2.2.1 控制器到处理器方向
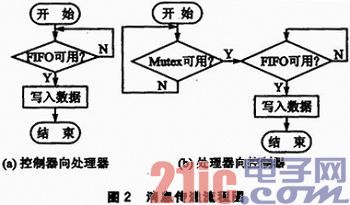
控制器到处理器方向的连接属于一对多的模式,每条通路各自独立,因此该方向上的传递比较简单,由控制器直接向目标FIFO写入数据即可。该方向的传递流程图如图2(a)所示。
2.2.2 处理器到控制器方向
处理器到控制器方向的连接属于多对一的模式,当处理器同时有消息要传递给控制器时会引起冲突。为解决该冲突,系统引入了互斥核。因此该方向上的消息传递时需要先锁定互斥核,才能向控制器的FIFO写入消息数据。该方向的传递流程图如图2(b)所示。
2.3 消息的读取
消息的读取过程为处理器从消息存储器FIFO读出数据的过程。由于采用的是双端口FIFO,数据的写入与读取可同时进行。但由于处理器可能存在中断、写入与读出速率不一致等原因,因此消息的读取采用异步读取的方式,即判断FIFO中的数据个数,先读取消息的前两个字节,获得该消息的长度,然后根据该长度等待消息传递完毕,再一次性读取剩余消息数据。
2.4 消息的处理
消息读取完之后,首先发送确认消息给发送者,表示成功收到了消息。然后根据洧息中的类型跳转到该类型的处理函数,接着再根据消息中的子类型跳转到该子类型的处理函数。最后,当任务执行完之后发送任务结束消息。
2.5 数据移动
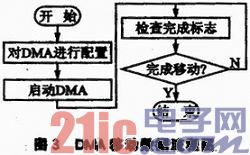
当系统中有大量的数据需要移动时,为了减少系统的开销,加入DMA核。数据的移动由DMA核控制,而DMA核由控制器进行控制。因此,从处理器如果有移动数据的需要,需要用消息先通知控制器,然后由控制器控制DMA进行移动。图3为控制器利用DMA进行数据移动的流程图。
2.6 容错性设计
当系统长时间运行时,不排除处理器出现问题的可能性,因此需要引入容错性设计,保证系统能正确运行。
首先,主控制器中定义一个从处理器列表。从处理器初始化完成时,发送初始化完成消息,主控制器对发送消息的从处理器进行登记,并添加到列表。
接着,主控制器中定义一个任务结构,包含任务所属的组、任务ID、任务允许最长处理时间、任务开始处理的时间等字段。运行时,主控制器根据事先设计的程序生成任务列表,然后根据从处理器列表分配任务,并记录任务处理开始时间。
然后,主控制器反复查询任务列表,检查任务时间。当发现任务超时,则重新分配该任务,使得系统仍能正常工作,并将处理该任务的从处理器从列表中别除,发出警报。
3 实验与结果
为了验证该系统的可行性及性能,本文采用JPEG编码器(以DCT变换为基础的有损压缩算法)作为该系统的测试程序。DCT算法的大致流程为:对于一块最小数据处理单元(MCU),先把数据从空间域变换到频率域,从而去除数据的冗余度;量化器用加权函数来产生对人眼优化的量化DCT系数,同时熵编码器将量化DCT系数的熵最小化。
其中前向DCT的变换公式如下:

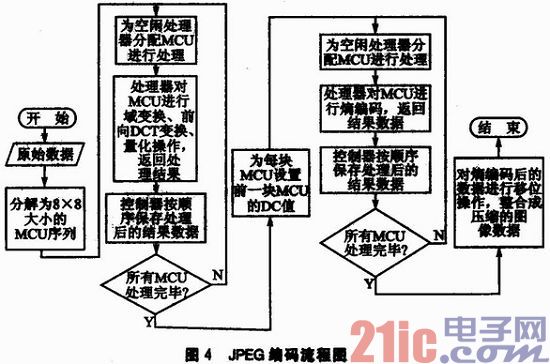
由上述公式可见,前向DCT变换是相当耗时的一部分,因为该部分需要求取余弦值,然后求积与求和,并且进行的都是浮点运算;运用快速算法可减少该部分的处理时间。在JPEG编码框图中,前向DCT处理的都是8×8大小的数据块,每个数据块之间相互独立,因此可同时进行计算。在熵编码过程中,对直流系数DC的编码采用的是差分脉冲编码调制(DPCM)方法,需要用到前一块MCU数据的DC值,所以需要等待前一块MCU的量化结果,结合本文所设计的系统,采用1:1:1的压缩比,可将JPEG编码算法按图4所示的流程进行分解处理。
在Altera公司的芯片EP3C25F324C8上利用SOPC完成了图1所示的系统体系结构。用Quartus软件进行综合,综合结果如表1所列。利用Nios II IDE完成了JPEG编码程序。程序运行时,利用时间戳(timestamp)测得图像编码所用的时间,并用公式Sp==T1/Tp计算得到加速比Sp,其中T1是单处理器时的运行时间,Tp为有p个处理器时的运行时间。结果如表2所列。
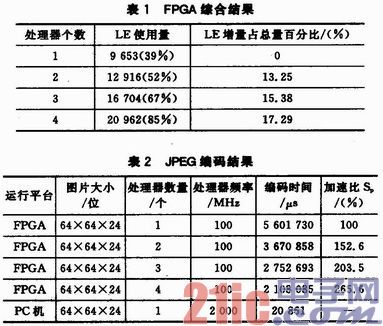
在FPGA中,LE的开销量Z可分为处理器用量X与系统用量Y,因此Z≈N×X+Y,结合表1的数据可计算得出,一个处理器对应的LE使用量约为3 769,占总量的15.3%。
在表2中,PC机的处理频率是FPGA软处理器的频率的2 000/100=20倍,FPGA单处理器的处理时间是PC机的5 601 730/20 861≈268倍,可见与频率不成正比。主要原因为PC机支持浮点运算,而FPGA的软核处理器为定点运算。
由表2可看出,每增加一个处理器,加速比可提升50%,因此增加处理器的数量可明显提升系统性能,而增加一个处理器在硬件上只需增加15.3%的开销,因而具有一定的性价比。另外,由于处理器之间是相互独立的,并在硬件结构与软件设计上保持一致,这使得当增加处理器时,只需修改一些配置参数即可,这有利于减少增加处理时的工作量和开发成本。
系统运行于4个处理器时,运行过程中突然断开一个处理器,模拟处理器出现问题的情况,测得系统仍能正常输出,运行时间为2 551 542 μs。相比正常情况的2 108 085μs,显然处理时间有所延长,但此时系统仍能正常输出,因而证实了该系统具有一定的容错性。
结语
针对目前多处理器系统针对性强、开发难度大、不具备容错性的不足,本文提出了一种基于消息机制的多处理器系统,实现了多处理器系统的通用性设计,简化系统的设计难度,同时具有一定的容错性与稳定性。在文中利用FPGA技术进行仿真验证。系统实验表明,增加处理器数量可明显提升系统的性能,并具有一定的性价比。在系统中的某一个处理器出现问题时,系统仍能正常输出,具有一定的容错性。