引言:现有的嵌入式软件设计技术已经不能满足复杂的多处理器架构的通信(IPC)软件开发需求。本文介绍了一种基于功能事务级建模方法的虚拟原型设计技术,使用这种技术,所有的软件开发任务都能在硅片出现之前完成,提高了开发效率和缩短产品的面市时间。
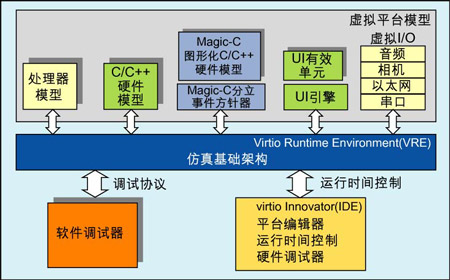
图1:虚拟原型技术框图。
在当前的嵌入式系统中,为满足不断增长的计算需求、吞吐量以及集成的系统功能,多处理器架构正在开始广泛采用。例如,高端智能电话已经包含了很多的微处理器(MPU)和数字信号处理器(DSP)来提供先进的2.75G和3G调制解调器和应用处理功能,以及WiFi、GPS和蓝牙功能。
当前的嵌入式软件设计实际并没有为这些不同架构开发处理器间的通信(IPC)软件的复杂性做好准备。然而,虚拟原型设计技术正在出现,这种技术允许创建嵌入式系统的高性能功能性软件模型,这种软件模型非常完整,能完全反映出硬件功能。
基于功能事务级建模方法(F-TLM),通过将高速处理器指令集仿真器与高级的全功能硬件构建模块的C/C++模型结合起来,可以产生一种虚拟的平台。产生的这种虚拟平台是一种高级的硬件模型,这种模型足够完善,软件开发者可以用来替代实际设备。
采用这种平台(见图1),软件团队能在得到硅片之前的很长时间就可以开始开发、整合以及测试软件代码。这种技术促成了各层次软件的并行开发,包括ROM代码、固件代码、设备驱动程序、操作系统的移植、中间件和应用程序的开发。
F-TLM平衡了多处理器软件的要求
基于F-TLM的虚拟平台模型提供了指令集仿真器、硬件/外设模型和系统I/O之间的恰当平衡,这样就可以允许早期和并行的软件开发。F-TLM专注于与软件开发者相关的硬件方面,一般回避那些在软件编程模型中接触不到的硬件细节。正确的F-TLM环境结合了三种主要的元素:
精确指令ISS:在一个典型的多处理器设计中,为不同设备而生成的基于F-TLM的CPU模型能对CPU状态进行建模以及执行目标程序二进制代码。生成的CPU模型包括MMU(内存管理单元)模型,它能与功能性缓存模型互补,提供运行时的缓存命中/错过的数目的统计信息。利用精确指令,它们能逐指令执行目标程序二进制代码,因此与二进制代码兼容。然而,这种CPU模型没有包含CPU管线的模型,没有保持周期的细节。
高级事务级总线模型:在多处理器设计中,复杂的总线传输信息流被简化成简单的读和写事务。这种抽象由许多方面组成,包括不同的总线阶段、芯片选择、重试、仲裁之后的总线转向等等。在简单的总线模型上以读和写函数调用来执行事务。这些总线模型对地址解码和不同总线单元(例如总线桥、仲裁器等)的控制寄存器进行建模。
功能外设模型:针对多处理器设计中的每个硬件外设,对寄存器接口、编程模型、功能和与其它外设或者其系统I/O的通信建模。建模关注于软件和外设功能之间的相互作用和影响。例如,对一个相机接口控制器的某个控制/命令寄存器的编程可能启动来自第二个电话相机的数据流。
这种类型的交互和功能可以包含在功能模型中。硬件方面,例如内部管线、内部硬件加速器的仲裁、访问系统总线的流控制等等,从运行的软件来看,它们一般没有相关性,因此没有包含在平台模型中。
表1显示了对于一个完整的板级仿真器来说,F-TLM可以获得的执行时间(绝对的时钟时间以及主PC每GHz的规格化MIPS(每秒百万条指令)。板级仿真器由基于多处理器的复杂系统级芯片(SoC)和几个板级分立器件组成。注意,在OS引导阶段,每GHz的有效MIPS数(OS对不同的外设编程,并等待外设在初始化之后返回结果)越低,则有效的MIPS额定值越低。
准确周期模型与F-TLM模型
相对于F-TLM模型,准确周期模型尽管提供了非常好的细节和时序规格,但非常难以评估,需要花费很多的时间来进行开发,并且执行速度也更慢,一般在每秒500k周期的数量级。尽管对于低级的软件开发任务(例如软件运行代码很少的ROM代码和固件开发)来说这种性能等级是可以接受的,但是对于高效率的高级操作系统移植、中间件整合以及应用程序开发来说还是太慢了。
基于F-TLM的虚拟原型方法在很多嵌入式消费类设备中采用的复杂多处理器环境中具有几个优势。
作为这种系统核心的高度集成的SoC包含数十个外设和多个片上和片外总线,由于引脚或者JTAG限制,其中一些在物理目标上可能是不可见的,使得对这些器件的编程和调试更加复杂。
提供对对象更高的可见性和控制对于提高这些新SoC的软件开发效率来说是很必要的。为了获得高的整体执行速度,以及观察发现95%的仿真速度用在CPU ISS以及存储器模块上,推动了仿真器开发向着CPU ISS和存储器模块这些关键器件使用本地的、编译的C++代码方向发展。
在这样的F-TLM环境中,为捕获外设和它们的功能,需要一种图形化的有限状态机(FSM)语言,例如“Magic-C”。“Magic-C”把一些规范与描述语言(SDL)的图形化描述能力与ANSI-C的执行能力结合起来。

图2:通信FSM执行范例截屏图。
并行的通信FSM执行范例(见图2)可以很容易地描述并行硬件实体,同时其图形化的特性能实现一种图形化的硬件调试器,这种调试器可连接到正在运行的仿真,还能支持如硬件断点和硬件单步调试的全新功能。
采用这种图形化的语言,开发者可以同时通过Magic-C硬件调试器调试硬件,通过一个与运行中的仿真相连接的软件调试器调试软件。仿真框架也应该尽可能多地利用标准的模型接口和API,促进器件模型的复用。通常,这意味着一组标准的事务级接口和一种标准的抽象层,所有的外设模型用这些与总线相连。
采用F-TLM构建一个多处理器SoC
图3:OMAP虚拟平台的截屏图。
通过了解怎样运用F-TLM方法在基于TI OMAP平台上进行应用开发,该方法在对多处理器架构进行建模中的功能显而易见。OMAP是一种具有鲁棒性的软件基础架构,具有对于快速开发互联网设备、2.5G和3G无线手机和PDA以及其它多媒体增强设备的全面支持网络。
为实现这些特点,这些SoC利用一种先进的不同的RISC/DSP架构,结合了专用的2D/3D图形加速器和图像视频加速器(IVA),其中有些加速器包含一个额外的RISC核,产生不同的并行片上CPU网络。
仿真器使用模型-为加速OMAP架构的内部和外部软件开发,TI与Virtio合作开发了几个OMAP虚拟平台,这些平台早于硅片出现几个月。图3中显示了OMAP虚拟平台的截屏图。
通过协调内部软件开发阶段与OMAP平台提交时间,软件开发可以在平台开发开始后四个星期就开始。所有这些在架构规范和硬件设计还在确定的过程中就可以开始,从而实现真正的并行开发。
基于F-TLM的虚拟平台首先实现了能使用低级ARM(调试)工具提前开发开放的操作系统引导加载程序,其次是OS HAL的开发、内核移植,最后能使得设备驱动程序扩展集进一步开发,这些都是通过使用目前的目标开发工具,而不需要改变开发流程。
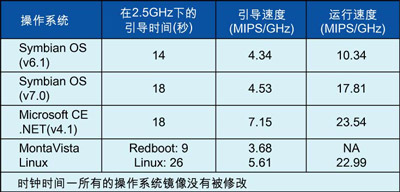
表1:几种嵌入式操作系统时钟时间的比较。
与此同时,DSP团队进行DSP/BIOS实时操作系统的移植与开发。在后期阶段,开发团队开发处理器间通信(IPC)层以及RISC内核与DSP之间的器件,并将这些添加到高级操作系统和DSP/BIOS端。
一旦板级支持包(BSP)开发完成并经确认,TI就将由OMAP虚拟平台和BSP组成的桌面开发环境提交给初始客户,使客户能开始整合设备中间件和关键应用,加速他们的设备开发。
处理器间通信的好处:对不同处理器组成的网络IPC软件开发一般是对这些SoC的全部软件开发中最具有挑战性的一个任务,虚拟平台的几个关键特性对加速这种开发提供了非常大的帮助,并提高了开发的效率。
虚拟平台提供了增强的系统可见性,这使开发者能更简单地隔离和调试IPC问题。Magic-C硬件断点和调试功能提供了在任何时间点对片上IPC硬件状态(例如片上信箱区和信号量)、整体的系统状态和CPU状态的可见性。
与物理开发对象相比不同的是,当CPU在与JTAG调试器连接的运行过程中停止工作时,整个系统包括硬件外设时钟(不仅仅特定的CPU实例)都会停止工作。这导致IPC硬件(以及所有的其它外设)停止工作,这些IPC硬件与CPU同步。这样一来,在任何时间点,系统状态不受影响,例如不会被中断触发破坏。像每当CPU停止工作时系统状态的维持不受影响这样的功能,有利于提高开发效率。
确定性仿真执行和多内核调度算法确保了可预测性,这可以使设计缺陷轻易再现,并可反复运行仿真。
此外,通过提供对对象的低级多内核JTAG式控制,仿真支持紧凑的多内核调试。例如,每当DSP或者RISC中发生一个值得关注的事件时,任何一个调试器都能停止整个平台的执行,工程师就可以查看DSP和RISC中的事件点。
由于采用先进的仿真技术,所有的软件开发任务,包括DSP/BIOS操作系统移植和IPC软件开发,都能在硅片出现之前完成。最初的内部软件开发效率调查显示,相比于使用物理对象的开发,测得的效率提升达2倍到5倍。