在实时控制系统中,选择微控制器的指标时最重要的是计算速度的问题。指令周期是反映计算速度的一个重要指标,为此本文对三种最具代表性的微控制器(AT89S51单片机、ARM7TDMI核的LPC2114型单片机和TMS320F2812)的指令周期进行了分析和测试。为了能观察到指令周期,将三种控制器的GPIO口设置为数字输出口,并采用循环不断地置位和清零,通过观察GPIO口的波形变化得到整个循环的周期。为了将整个循环的周期与具体的每一条指令的指令周期对应起来,通过C语言源程序得到汇编语言指令来计算每一条汇编语言的指令周期。
1 AT89S51工作机制及指令周期的测试
AT89S51单片机的时钟采用内部方式,时钟发生器对振荡脉冲进行2分频。由于时钟周期为振荡周期的两倍(时钟周期=振荡周期P1+振荡周期P2),而1个机器周期含有6个时钟,因此1个机器周期包括12个晶振的振荡周期。取石英晶振的振荡频率为11.059 2 MHz,则单片机的机器周期为12/11.059 2=1.085 1 μs。51系列单片机的指令周期一般含1~4个机器周期,多数指令为单周期指令,有2周期和4周期指令。
为了观察指令周期,对单片机的P1口的最低位进行循环置位操作和清除操作。源程序如下:
#include
main() {
while(1) {
P1=0x01;
P1=0x00;
}
}
采用KEIL uVISION2进行编译、链接,生成可执行文件。当调用该集成环境中的Debug时,可以得到上述源程序混合模式的反汇编代码:
2:main()
3: {
4:while(1)
5:{
6:P1=0x01;
0x000F759001MOVP1(0x90),#0x01
7:P1=0x00;
0x0012 E4CLRA
0x0013 F590MOVP1(0x90),A
8:}
0x001580EDSJMPmain (C:0003)
其中斜体的代码为C源程序,正体的代码为斜体C源程序对应的汇编语言代码。每行汇编代码的第1列为该代码在存储器中的位置,第2列为机器码,后面是编译、链接后的汇编语言代码。所有指令共占用6个机器周期(其中“MOV P1(0x90),#0x01”占用2个机器周期,“CLR A”和“MOV P1(0x90),A”各占用1个机器周期,最后一个跳转指令占用2个机器周期),则总的循环周期为6×机器周期=6×1.085 1 μs=6.51 μs。
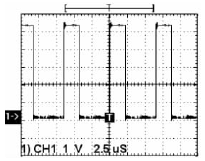
图1 P1口最低位的波形
将编译、链接生成的可执行文件下载到AT89S51的Flash中执行可以得到P1口最低位的波形,如图1所示。整个循环周期为6.1 μs,与上面的分析完全一致。
2 LPC2114工作机制及指令周期的测试
LPC2114是基于ARM7TDMI核的可加密的单片机,具有零等待128 KB的片内Flash,16 KB的SRAM。时钟频率可达60 MHz(晶振的频率为11.059 2 MHz,时钟频率设置为11.059 2×4 =44.236 8 MHz,片内外设频率为时钟频率的1/4,即晶振的频率)。ARM7TDMI核通过使用三级流水线和大量使用内部寄存器来提高指令流的执行速度,能提供0.9 MIPS/MHz的指令执行速度,即指令周期为1/(0.9×44.236 8)=0.025 12 μs,约为25 ns。
为了观察指令周期,将LPC2114中GPIO的P0.25脚设置为输出口,并对其进行循环的置位操作和清除操作。C源程序如下:
#include"config.h"
//P0.25引脚输出
#defineLEDCON0x02000000
intmain(void)
{//设置所有引脚连接GPIO
PINSEL0 = 0x00000000;
PINSEL1 = 0x00000000;
//设置LED4控制口为输出
IO0DIR = LEDCON;
while(1)
{IO0SET = LEDCON;
IO0CLR = LEDCON;
}
return(0);
}
采用ADS1.2进行编译、链接,生成可执行文件。当调用AXD Debugger时,可以得到上述源程序的反汇编代码:
main[0xe59f1020]ldrr1,0x40000248
40000224[0xe3a00000]movr0,#0
40000228[0xe5810000]strr0,[r1,#0]
4000022c[0xe5810004]strr0,[r1,#4]
40000230[0xe3a00780]movr0,#0x2000000
40000234[0xe1c115c0]bicr1,r1,r0,asr #11
40000238[0xe5810008]strr0,[r1,#8]
4000023c[0xe5810004]strr0,[r1,#4]
40000240[0xe581000c]strr0,[r1,#0xc]
40000244[0xeafffffc]b0x4000023c
40000248[0xe002c000]dcd0xe002c000
每行汇编代码的第1列为该代码在存储器中的位置,第2列为机器码,后面是编译、链接后的汇编语言代码。循环部分的语句最关键的就是下面3句:
4000023c[0xe5810004]strr0,[r1,#4]
40000240[0xe581000c]strr0,[r1,#0xc]
40000244[0xeafffffc]b0x4000023c
在AXD Debugger中,将其调用到RAM中运行程序得到循环部分GPIO的P0.25的输出波形,如图2所示。 从图中可以看出,循环周期中保持为高电平的时间为1350 ns左右,低电平的时间为450 ns左右,即指令“str r0,[r1,#4]”和指令“str r0,[r1,#0xc]”均需350 ns左右,而跳转指令则需100 ns左右。这主要是由于以下原因造成的: ① ARM的大部分指令是单周期的,但是也有一些指令(如乘法指令)是多周期的;② 基于ARM核的微控制器只有加载、存储和交换指令可以对存储器的数据进行访问,这样从存储器读数据或向存储器写数据要增加1个时钟周期;③ 访问片内外设要增加一个外设时钟周期。当然,每个指令还要有1个时钟周期,跳转时要清空流水线还要另加一定的时钟周期。

图2 GPIO的P0.25脚输出波形
为了观察乘法指令,特地采用下述汇编语言进行了实验。首先是没有乘法指令的汇编源程序:
INCLUDELPC2294.INC ;引入头文件
; P0.25引脚控制LED4,低电平点亮
LEDCONEQU0x02000000
EXPORTMAIN
;声明程序代码块
AREALEDCONC,CODE,READONLY
;装载寄存器地址,PINSEL0
MAINLDRR0,=PINSEL0
;设置数据,即设置引脚连接GPIO
MOVR1,#0x00000000
STRR1,[R0]; [R0] ← R1
LDRR0,=PINSEL1
STRR1,[R0]
LDRR0,=IO0DIR
LDRR1,=LEDCON
;设置LED控制口为输出
STRR1,[R0]
;设置GPIO控制参数
LOOPLDRR1,=LEDCON
LEDSETLDRR0,=IO0SET
; LED控制I/O置位,即LED4熄灭
STRR1,[R0]
LEDCLRLDRR0,=IO0CLR
; LED控制I/O复位,即LED4点亮
STRR1,[R0]
;无条件跳转到LOOP
B LOOP
采用ADS1.2进行编译、链接后的汇编代码为:
LOOP [0xe3a01780]movr1,#0x2000000
LEDSET[0xe59f0028] ldrr0,0x40000128
400000fc[0xe5801000]strr1,[r0,#0]
LEDCLR[0xe59f0024] ldrr0,0x4000012c
40000104 [0xe5801000]strr1,[r0,#0]
40000108 [0xeafffff9] bLOOP
在AXD Debugger中,将其调用到RAM中运行程序得到循环部分的GPIO的P0.25脚输出波形,如图3所示。 从图中可以看出,循环周期中保持为高电平的时间为450 ns左右,低电平的时间为550 ns左右。

图3 GPIO的P0.25脚输出波形2
在上例的LOOP循环部分中加入乘法指令,即将循环部分改为:
LOOP LDRR1,=LEDCON
LEDSETLDRR0,=IO0SET
STRR1,[R0]
MOVR2,#0x0234
MULR2,R1,R2
LEDCLRLDRR0,=IO0CLR
STRR1,[R0]
B LOOP
采用ADS1.2进行编译、链接后的汇编代码为:
LOOP[0xe3a01780]movr1,#0x2000000
LEDSET[0xe59f0030]ldrr0,0x40000130
400000fc[0xe5801000]strr1,[r0,#0]
40000100[0xe3a02f8d]movr2,#0x234
40000104[0xe0020291] mulr2,r1,r2
LEDCLR[0xe59f0024] ldrr0,0x40000134
4000010c[0xe5801000]strr1,[r0,#0]
40000110[0xeafffff7]bLOOP
在AXD Debugger中,将其调用到RAM中运行程序得到循环部分的GPIO的P0.25脚输出波形,如图4所示。 从图中可以看出,循环周期中保持为高电平的时间为550 ns左右,低电平的时间为550 ns左右。与上例比较可知,多出的MUL乘法指令和MOV传送指令共占用100 ns。
综上所述,得出如下结论: 当ARM指令放在RAM中运行时,指令“str r0,[r1,#4]”和指令“strr0,[r1,#0xc]”均需350 ns左右,相当于14个指令周期;指令“ldr r0,0x4000012c”的执行时间为100 ns,相当于4个指令周期;MUL乘法指令和MOV传送指令共占用100ns,相当于4个指令周期;跳转指令共占用100 ns,相当于4个指令周期。
3 TMS320F2812工作机制及指令周期测试
TMS320F2812是TI公司的一款用于控制的高性能和高性价比的32位定点DSP芯片。该芯片最高可在150 MHz主频下工作(本文将其设置到100 MHz),并带有18K×16位0等待周期片上SRAM和128K×16位片上Flash(存取时间为36 ns)。TMS320F2812采用哈佛总线结构,即在同一个时钟周期内可同时进行一次取指令、读数据和写数据的操作,同时TMS320F2812还通过采用8级流水线来提高系统指令的执行速度。
为了观察指令周期,对TMS320F2812的GPIOA0进行循环的置位操作和清除操作。C源程序如下:
#include "DSP28_Device.h"
void main(void) {
InitSysCtrl();/*初始化系统*/
DINT;/*关中断*/
IER = 0x0000;
IFR = 0x0000;
InitPieCtrl();/*初始化PIE控制寄存器*/
InitPieVectTable();/*初始化PIE矢量表*/
InitGpio();/*初始化EV*/
EINT;
ERTM;
for(;;) {
GpioDataRegs.GPADAT.all=0xFFFF;
GpioDataRegs.GPADAT.all=0xFFFF;
GpioDataRegs.GPADAT.all=0xFFFF;
GpioDataRegs.GPADAT.all=0x0000;
GpioDataRegs.GPADAT.all=0x0000;
GpioDataRegs.GPADAT.all=0x0000;
}
}

图4 GPIO的P0.25脚输出波形3
其中最重要的是要对通用输入/输出进行初始化和确定系统CPU时钟。其中系统的时钟通过PLL设定为100 MHz,而初始化 InitGpio() 的源程序为:
#include "DSP28_Device.h"
void InitGpio(void)
{ EALLOW;
//多路复用器选为数字I/O
GpioMuxRegs.GPAMUX.all=0x0000;
//GPIOAO为输出,其余为输入
GpioMuxRegs.GPADIR.all=0x0001;
GpioMuxRegs.GPAQUAL.all=0x0000;
EDIS;
}
通过在主程序for(;;)的地方加断点,可以很容易找到上面主程序中循环部分程序编译后的汇编指令:
3F8011 L1:
3F8011761FMOVWDP,#0x01C3
3F8013 2820 MOV@32,#0xFFFF
3F8015 2820 MOV@32,#0xFFFF
3F8017 2820 MOV@32,#0xFFFF
3F8019 2820 MOV@32,#0xFFFF
3F801B 2820 MOV@32,#0xFFFF
3F801D 2820 MOV@32,#0xFFFF
3F801F 2B20 MOV@32,#0
3F8020 2B20 MOV@32,#0
3F8021 2B20 MOV@32,#0
3F8022 6FEF SBL1,UNC
其中第1列为程序在RAM中的位置,第2列为机器码,后面就是汇编语言程序。指令“MOV @32,#0xFFFF”使GPIO输出高电平,指令“MOV @32,#0”使GPIO输出低电平。其中含有6个使GPIOA0输出高电平的指令和3个使GPIOA0输出低电平的指令,系统的指令周期为10 ns,因此循环周期中保持高电平的时间为60 ns。通过将该程序放在H0 SARAM中进行调试,可得GPIOA0的波形,如图5所示。其中高电平时间正好为60 ns。注意,由于3个低电平之后要进行跳转,故清空流水线的周期要长一些。

图5 TMS320F2812中GPIOA0的波形1
为了观察乘法指令的周期,将上述循环部分的C源程序修改为:
for(;;)
{Uint16 test1,test2,test3;
test1=0x1234; test2=0x2345;
GpioDataRegs.GPADAT.all=0xFFFF;
GpioDataRegs.GPADAT.all=0xFFFF;
GpioDataRegs.GPADAT.all=0xFFFF;
test3=test1*test2;
GpioDataRegs.GPADAT.all=0x0000;
GpioDataRegs.GPADAT.all=0x0000;
GpioDataRegs.GPADAT.all=0x0000;
}
上述程序经过编译、链接后的汇编指令如下:
3F8012L1:
3F80122841MOV*-SP[1],#0x1234
3F8014 2842 MOV*-SP[2],#0x2345
3F8016 761F MOVWDP,#0x01C3
3F8018 2820 MOV@32,#0xFFFF
3F801A 2820 MOV@32,#0xFFFF
3F801C 2820 MOV@32,#0xFFFF
3F801E 2D42 MOVT,*-SP[2]
3F801F 1241 MPYACC,T,*-SP[1]
3F8020 9643 MOV*-SP[3],AL
3F8021 2B20 MOV@32,#0
3F8022 2B20 MOV@32,#0
3F8023 2B20 MOV@32,#0
3F8024 6FEE SBL1,UNC
其中使GPIOA0为高电平的指令仍然为6个指令周期(其中包括1个乘法指令),因为乘法指令也是单周期的,因此循环周期中保持高电平的时间为60 ns。通过将该程序放在H0 SARAM中进行调试可得GPIOA0的波形,如图6所示。其中高电平时间正好为60 ns,而由于3个低电平之后要进行跳转,要清空流水线,而且还要为乘法做准备,因此保持低电平的时间比图5所需的时间要长。当采用数字式示波器观察时,如果探头采用×1档观察的波形不是很理想,则可以采用×10档,并配合调节探头的补偿旋钮。
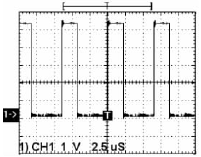
图6 TMS320F2812中GPIOA0的波形2
4 三种微处理器的比较
首先要强调的是,这几种微控制器都可以通过提高晶振的振荡频率来缩短指令周期,但是这些控制器的振荡频率是有一定限制的,例如单片机不超过40 MHz,而LPC2114的频率不超过60 MHz,TMS320F2812的最高频率为150 MHz。在同样的工作频率下,ARM指令运行的指令周期远远高于传统的单片机。 因为传统的单片机没有采用流水线机制,而ARM核和DSP都采用了流水线,但是由于访问外设和RAM等存储器要加一定的时钟周期,因此ARM不是真正可以实现单周期运行的,特别是不能实现单周期的乘法指令,而DSP可以实现真正的单周期乘法指令,速度要远远高于ARM微控制器。
参考文献
[1] 马忠梅,籍顺心,等. 单片机的C语言应用程序设计. 北京:北京航空航天大学出版社,2003.
[2] 薛钧义,张彦斌. MCS51/96系列单片微型计算机及其应用. 西安:西安交通大学出版社,1990.
[3] 周立功,等. ARM微控制器基础与实践. 北京:北京航空航天大学出版社,2005.
[4] Texas Instruments Incorporated. TMS320C28x Assembly Language Tools Users Guide. 2001.
[5] Texas Instruments Incorporated. 软件TMS320C28x Optimizing C C++ Compiler Users Guide. 2003.