1.概述
本文是Stratix和Cyclone器件架构中各种所见即所得原语用户手册的部分内容。本文为设计者可以或者更详细的细节,确保在设计布线的时候能够更容易让设计布通。使得设计者更好、更合法地使用LAB、DSP等底层硬件模块。
2.坐标系统和位置约束
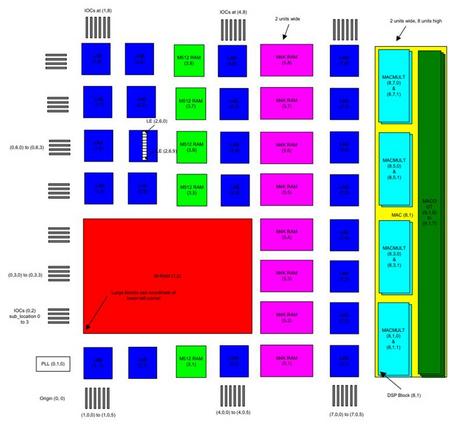
图1:Stratix坐标系统
图1是Stratix和Cyclone器件架构的坐标系统,只是注意图中有些模块中Cyclone系统中是没有的,比如M512 RAMs,M-RAM和DSP)。
将图1看成一个X-Y坐标系,那么左下方就是坐标原点,我们看到最小的格子都有一个(x,y)坐标表示,而有些大的格子可能横跨多个小格子,那么就由其左下方左边表示其位置信息。根据坐标,设计者可以为一个逻辑设计模块分配一个逻辑区域,一般都是矩形区域。
3.布线延迟与布线距离以及布线规则的关系
在Stratix和Cyclone器件中,没有严格的布线层次结构,所以布线延迟会随着“曼哈顿”距离而线性地增加。对于Stratix和Cyclone来说,走线速度由快到慢的顺序排列如下:
走线起始和终点位于同一个LAB 从一个逻辑单元(LE)的组合逻辑输出到这个LE下方相邻位于同一LAB之中的LE的DATAD输入的布线是最快的(extra-fast)。所以从LE#0的.combout到LE#1的.datad的走线是一条超级快速的路径,fitter总是试图自动采用这种超快走线。 走线终点位于起点紧挨的右侧或者左侧的LAB中。这种走线可以由一个LE直接驱动它邻近LAB的LAB line实现。 延迟会随着曼哈顿(Manhattan)距离的增加而增加。对于曼哈顿距离一样的布线,布线的起点和终点位于同一行或者同一列那么会得到更小的布线延迟,因为这种走线没有从垂直到水平或相反的走线切换。Stratix中长距离走线延迟会比Cyclone增加的要慢一些,这是因为Cyclone只有R4和C4,而Stratix有R8、V8、R24以及C16。
Stratix器件的水平布线资源大概是垂直布线资源的两倍,所以设计的时候可以考虑使用布局规划多使用大部分设计布线使用水平布线资源。而Cyclone的水平和垂直布线数量是一样的。
4.Netlist Recommendations
多数WYSIWYG原语的输入端口硬件上都有可编程取反(Programmable inversion)结构。(笔者注:此特性在笔者研究FPGA TDC设计时使用ECO修改设计中得到验证)。为了利用这种取反特性,如果电路设计需要可以直接在网表中将信号的补码链接到输入端口。例如,如果电路需要在下降沿触发寄存输入到一个LE,那么网表可以连接!clock到stratx_lcell的.clk端口。这种情况下,LE中的可编程取反硬件将会将时钟取反。如果不这么做,那么一个新的信号,nclock,将会产生,fitter会将这个新产生的时钟信号连接到LE的时钟端口.clk,来使用负沿触发寄存器。这种网表会导致额外的一个LE被消耗,从而导致资源的大量浪费,并带来更差的时钟偏斜(Skew)。下面三个Stratix Lcell使用实例,从好到差进行展示。
stratix_lcell good_cell {
.clk(!clock), // good way to make an inverted clock
...
stratix_lcell unneeded_inverter {
.dataa(clock),
.combout(nclock) // half of bad way to make an inverted clock
}
stratix_lcell bad_cell {
.clk(nclock), // bad way to make an inverted clock
...
当然也有一些WYSISYG原语输入端口没有可编程取反硬件(可参考Stratix LE所见即所得描述文档中的详细列表),所以这些端口无法直接使用输入信号补码连接到端口,所以必须额外使用一个LE来产生信号的取反逻辑。
大部分WYSISYG原语输入端口可以直接接GND或VCC。对于这样的端口,这样是最好的接法,而不是另外创建一个LE,使其输出为0或者1后再接到这些端口。当然有些端口不能直接接VCC和/或者GND,所以必须为这些端口额外创建一个LE来产生逻辑0或1输出到这些端口。
stratix_lcell make_preset_using_aload {
.aload(aloadsig),
.datac(VCC), // OK, but can’t connect .datac to GND directly
...
5.LE和LAB的Fitting规则
这一节主要列出了综合工具应该遵守的一些规则,如此才能确保一是所有逻辑单元都符合电路有效性,二是当所有逻辑单元能够被合法地综合进LAB,并保证其布通性。
5.1单个LE规则
当clk端口连接时,regout端口必须被连接或者sum_lutc_input=qfbk。(什么是QFBK,似乎是一种工作模式) 当regout端口连接时,clk端口必须连接 当aclr端口连接时,clk端口必须连接 当sclr端口连接时,clk端口必须连接 当sload端口连接时,clk端口必须连接 当aload端口连接时,clk端口必须连接 当sum_lutc_input=qfbk时,clk端口必须连接 当sload连接时,datac端口必须连接 当aload端口连接时,datac端口必须连接 Datac端口不能被取反,当它用于同步数据加载或者异步数据加载的时候。 Datac端口被直接设置为GND 当ena端口连接时,clk端口必须连接 关于cin端口 只能被连接到另一个逻辑单元的cout端口 不能被设置为VCC或者GND 不能被连接到一个被取反的信号(比如!my_carry) Cout端口要么被连接到另一个LE的cin端口,要么就什么也不接 关于regcasin端口 只能在register_cascade_mode=on的时候连接 只能连接到另一个逻辑单元的regout端口的信号源上 不能被设置为VCC或者GND 不能连接到一个取反的信号 Cout端口只能在逻辑单元的operation_mode=arithmetic的时候才能被连接,而且是在operation_mode=arithmetic时候必须被连接。 Sload端口只能是在逻辑单元的synch_mode=on的时候才能被连接 Sclr端口只能是在逻辑单元的synch_mode=on的时候才能被连接 Inverta端口只能是在逻辑单元的cin和cout中的一个或两个被连接的时候才能被连接。这是Quartus II的一个软件限制,是为了防止极端不易fitting的情况发生。
5.2从链(Chain)到LAB
Altera器件的逻辑单元中含有丰富的链,这些链主要是以一个LE的cout驱动下一个LE的cin这样的进位链(Carry Chain),以及一个LE的regout驱动下一个LE的regcascin而形成的寄存器级联链(Register Cascade Chain)。
Stratix和Cyclone的LE基本架构是一样的,一个LAB都是由10个LE组成。而所谓的链的中LE都是一个紧邻一个。比如一个进位链的第一个LE位于一个LAB的第一个LE,那么进位链的第二个LE应该位于该LAB的第二个LE,那么进位链的第11个LE就必须布局到刚才那个LAB的下一个LAB的第一个LE,如图2所示。
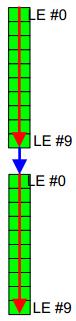
图2:进位链连接
我们可以看到一个很明显的现象,进位链的这个特点使得链中的10个相邻LE,如果第一个LE被布局到一个LAB的第一个LE位置,那么链中所有10个LE就必须被布局到这个LAB中。需要注意的是,LAB之间没有寄存器级联连接,所以寄存器级联链的最大长度只能是10,否则将会导致一个不确定性no-fit。
还请注意的是,任何使用inverta信号并且依赖该信号(cin位置)的lutmask的进位链必须从某个LAB的第一个LE开始。因此这里就有了一个办法可以将一个进位链前10个LE分派到一个LAB,下10个LE分派到另一个LAB,依次类推。
5.3 LAB-wide信号限制
许多连接到LE的信号其实是所谓的“LAB-wide”信号,这些信号单独为LAB产生并可以由LAB内的逻辑共享。因此,在一个LAB布置的逻辑单元如果需要过多的LAB-wide信号将是非法的。由于链布局约束要求,必须将一组10个相邻LE放在同一个LAB中,所以综合工具在产生链的时候必须格外小心,确保链能放在合法的LAB之中。如果链无法被fit进一个LAB,那么Quartus会通过插入“feedthrough”逻辑单元,直到它能被fit进合法的LAB,然后插入feedthroug逻辑单元的这个方法,会降低电路速度同时增加电路的面积。所以最好的办法还是避免让综合器去处理这样非法的链。一个非常保守但却非常简单的可以用于综合器的规则是,假设一个链中的所有逻辑单元一起总共使用的LAB-wide信号数量不能超过一个合**AB所能提供的数量。如此确保了fitter将可能分派一个链进入合法的LAB而不用插入feedthroughs。
如果一个布局是由第三方布局工具通过位置约束得到并发送到Quartus,并且这个布局里的逻辑违反了LAB-wide信号限制,Quartus将会报告出一个no-fit(即Quartus将不会试图修复这个布局)。如果这个布局导入的时候通过“preferred location”方式,那么Quartus将会试图修复这个非法的布局。
在Stratix和Cyclone架构中,连接到LE端口.clk,.ena,.aclr,.aload,.sclr,.sload和.inverta的信号都属于是LAB-wide信号。
所以关键的是,了解一个给定类型的一组LE在一个LAB中到底需要多少个LAB-wide信号。一个LE的端口连接到一个“regular”信号一般消耗一个LAB-wide信号。同一个信号的取反,算作消耗一个独立的LAB-wide信号。所以,如果LAB中一个LE使用了clock,而另一个LE使用了!clock,那么就需要两个LAB-wide线来连接时钟。LE上连接到VCC和GND的端口也需要LAB-wide线。还有一种情况是LE某些端口处于悬空状态,这种unconnect情况可能需要LAB-wide线,也可能不需要,这取决于端口以及LE的配置。表1显示了LE中悬空端口的处理情况。
表1:LE悬空端口处理
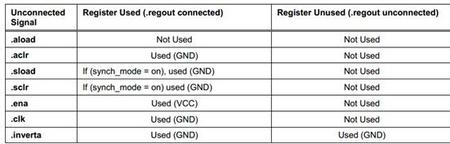
下列所以规则都是表1定义的,重要的是统计被认为“used”但是却未连接信号的LE端口。
所有LE上的.clk和.ena信号都成对地组成LE时钟,如图3所示。在任何LAB中,可以有不超过2个不同的LE时钟对。 同一个.clk信号和2个不同的.ena信号可认为是两个不同的LE时钟对 同一个.ena信号和2个不同的.clk信号可认为是两个不同的LE时钟对
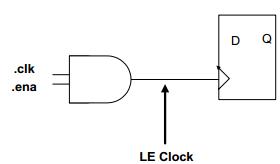
图3:时钟和时钟使能组合成LE时钟对
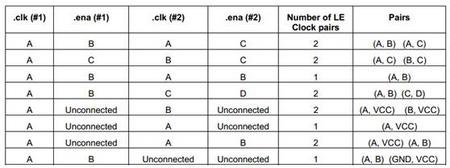
表2显示了一个时钟加时钟使能如何创建LE时钟对的例子。该例显示了两个LE的寄存器使用的两组时钟和两组时钟使能,clk(#1)和ena(#1)属于Logic Cell(#1),clk(#2)和ena(#2)属于Logic Cell(#2)。没有连接的.ena端口被配置为VCC,如表1指定那样。A,B,C和D对应信号网络。
表2:逻辑单元的时钟和时钟使能如何组成LE时钟的例子(.regout未连接)
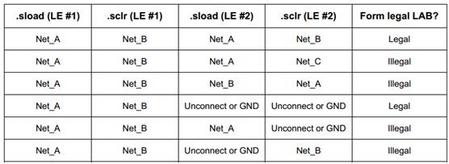
最多连个不同的信号可能被连接到.aclr端口。(从表1,可以看到一个LE如果使用了它的寄存器,那么未连接的.aclr将会认为是连接到GND) 最多只有一个信号能被连接到.aload端口 如何LAB中的任何LE使用了.aload那么 该LAB中所有使用.aload的LE必须使用和第一个LE一样的.aclr信号 该LAB中所有未使用.aload的LE必须使用相同的.aclr信号 最多只有一个信号可以连接到.inverta端口,从表1可知,.inverta信号影响所有的Lcell(因为它总是连接)。没有4输入组合单元能被布局到一个使用inverta的LAB,除非这个LAB正好使用同一个inverta。 最多只有一个信号可以连接到.sload端口,而且.sclr端口最多也只能有一个信号连接。 一个LE如果其synch_mode=off,那么它可以和另一个使用LAB的.sload或者.sclr端口的LE布局到同一个LAB 一个LE如果其synch_mode=on,那么它布局所在的LAB中的LE只能使用相同的sload或者sclr或者其中所有的LE都不使用同步加载和同步清零。
表3:同步加载和同步清零端口使用情况举例
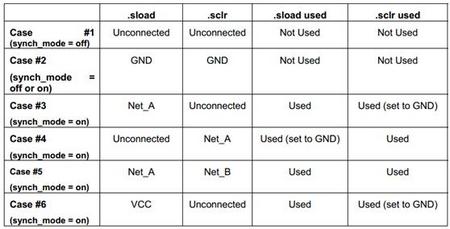
表4:合**AB布局和两个非法组合单元使用同步清零和同步加载举例
5.4 LAB控制信号可布通性约束
这里有一些规则可以确保LAB内所有必需的控制信号能被布局进这个LAB。任何连接到LE端口的信号网络(非VCC和非GND),如果其未使用全局布线资源,那么它布进LAB,需要占用LAB-wide输入端口。一个信号如果在LAB内正和负都被用到,那么该信号必须被布线两次。如果一个LE的一个端口连接(或者说可以如表1那样认为连接)到VCC或者GND信号,那么它可能需要也可能不需要占用LAB-wide输入端口,这取决于这个端口是否存在LAB-wide配合。最后,如果连接到.clk和.aclr端口的信号使用了全局布线资源,那么它们不需要LAB-wide输入端口,因为,在这种情况下,它们有一个专用端口进入LAB。表5显示了当一个LE的端口连接到一个信号或者连接(或者说可以如表1那样认为连接)到VCC或者GND时需要LAB-wide输入端口的情况。
表5:需要LAB-wide输入端口的情况
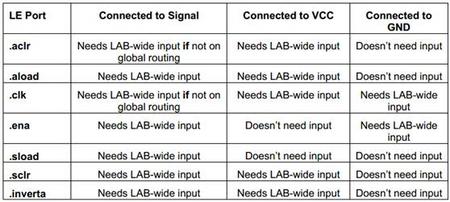
下面还列举的这些规则,是适用于根据表5需要LAB-wide输入端口信号的实例。例如,一个全局.aclr信号不应该计算在内,当评估下述原则的时候。
使用LAB-wide输入端口的信号总数必须不能多于6个,下列LE端口如表5所示是可能使用LAB-wide输入端口的。 .clk .ena .aload .sload .aclr .sclr .inverta 如果一个.sload信号需要一个LAB-wide输入端口,那么只有一个不同的.ena信号能被这个LAB使用。 如果一个LAB内需要一个.aload信号,那么这个LAB只能有一个不同的.clk信号能使用LAB-wide输入端口。 布进一个LAB的.aclr加上.sclr 信号总数是2。 能布进一个LAB的信号总数,Stratix是30,Cyclone是26。这些信号不包括cin或者LAB内部LE产生的信号。为了获得更好的布通性,Stratix最好不要有超过26个不同的信号,而Cyclone 最好不要有超过23个不同的信号需要布进同一个LAB。不包括时钟和异步清零,这些信号一般都使用特殊的全局布线资源。
5.5获得好的Fitting结果建议
一个LAB的.inverta端口具有很大的局限性,因为当它使用的时候,常常会影响甚至损害同一个LAB中其他组合单元的布局。它的一个好处是,使用.inverta端口可以强迫进位链从LE#0起始。这个特性最好是用于比较长的进位链,如果进位链长度小于一个LAB,使用.inverta端口很可能会导致的电路fit很困难,且大大增加了资源消耗。 使用LE的.sclr应当慎重,Stratix架构中一个LAB最多只有一个.sclr 。不恰当地使用这个端口,会大幅降低逻辑资源利用率、fitting可能性以及电路速度。举个例子,过去常常在一个LE里使用.sclr 端口来产生一个5输入函数,如此在实现这个电路的时候可以减少逻辑单元的数量,因此从一个综合角度来看这也许是一个好主意。但是,一旦这个LE使用了.sclr,那么这个LE所在的LAB一般无法将其它寄存器逻辑单元打包(Pack)进来,除非这些寄存器逻辑单元都使用同样的.sclr值或者它们的synch_mode=off。这可能在最坏情况下逻辑密度减少90%,因为只有一个LE可以被放置在一个LAB中,而不是10个。所以无原则地使用.sclr会导致非常坏的fitter结果和电路速度,因为fitter在这种情况将LE组合进LAB的灵活性非常小。 应该只有在用户电路中实现同步清零的时候才被使用,因为在这种情况下同步清零信号一般产生非常大的扇出。因此,fitter一般不会过分约束同步清零信号。一个LE链上的所有LE使用同一个同步清零时使用该端口也是合理的。 上述原则同样适用于.sload 端口。同步加载应当会产生高扇出。 时钟使能(.ena)使用起来相对有点宽松,因为每个LAB允许有两个不同的.ena值,这比只有.ena值大大提高了fitter应对多.ena值情况的能力。不过,过多的时钟使能(.ena)使得逻辑利用率超过90%非常困难。我们发现电路如果使用成千上万的时钟使能,通常往往逻辑利用率只能达到90%。更谨慎地使用时钟使能,常常能达到99%的逻辑利用率。因此,注意限制不同.ena信号的数量(尤其是低扇出信号)还是值得的。 不要使用register_cascade_mode=on除非你自己在开发一个非常详细的布局算法。这个模式可以将一个查找表和一个不相干的寄存器组合起来,以达到节省逻辑资源的目的。最好让fitter自己来执行这种组合,因为它能更好地知道哪些不同的查找表和寄存器应该天然地放在一起,什么又是的一个区域周围布线拥塞,诸如此类。如果直接使用这个模式来将查找表和寄存器组合在一起会电路fit成功非常困难,而且降低电路的速度。 Sum_lutc_input=qfbk(什么是qfbk?)现在可以用来将寄存器和驱动其(扇入)的查找表打包一起,而其他模式可以使得寄存器和被该寄存器驱动(扇出)的查找表打包一起,如图4所示,显示了这种选择。
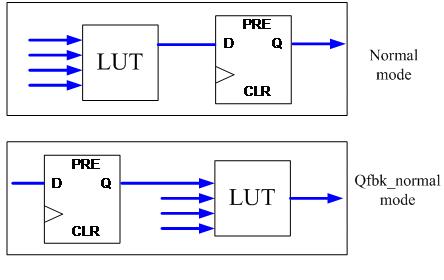
图4:寄存器和查找表组合进LE选项
至于决定到底选择哪种方式来打包寄存器和LUT,应该基于出现的连接哪些是关键时序走线,以及考虑走线的布通性。请注意以下几点:
从一个LE的查找表直接连接到同一个LE的寄存器(或者相反)是最快的走线。 双输出单元往往比单输出单元更难走线。因此,应当将只有一个输出的LE中的LUT和寄存器打包一起。这意味着,如果有从一个LUT到一个寄存器的连接,而该寄存器又是该LUT的唯一扇出,那么sum_lutc_input=datac是个很好的选择来合并这一对连接。同样的,如果有从一个寄存器到一个LUT的连接,且LUT是这个寄存器的唯一扇出,那么sum_lutc_input=qfbk是个很好的选择来合并这一对连接。 使用sum_lutc_input=datac比sum_lutc_input=qfbk有轻微的布通优势。同时,逻辑单元在sum_lutc_input=qfbk时也将使用sload=VCC从.datac加载寄存器的值。这样的逻辑单元fit稍微有些困难,因为他们使用LAB-wide同步加载信号。基于上述两个原因,当需要一个LE需要连接到其它地方的时候最好使用sum_lutc_input=datac。 Quartus的fitter会自动地决定是否使用qfbk模式将寄存器和LUT合并,如果你不确定你的算法以及它的时序预估,最好还是不要将寄存器和LUT合并。