1引言:功耗在芯片设计中的地位
长期以来,设计者面临的最大挑战是时序收敛,而功耗处于一个次要的地位。近年来,下面的因素使功耗日益得到设计者的关注:
1)移动应用的兴起,使功耗的重要性逐渐显现。大的功耗意味着更短的电池寿命。
2)芯片集成度的提高,使供电系统设计成为挑战。
随着工艺的进步,芯片内的电路密度成倍提高,并且运行在以前数倍的频率之上,而片上连线则越来越细,片上供电网络必须将更多的电力以更少的连线资源送至每个单元,如果不能做到这一点,芯片的稳定性和预定工作频率都将成为问题。IR压降和供电网络消耗的大量布线资源成为困扰后端设计者的重要问题,现在这种压力正在一步步传导到前端设计者的身上,要求在设计阶段减少需要的电力。
3)功耗对成本的影响日益显著
功耗决定了芯片的发热量,封装结构需要及时把芯片产生的热量传递走,否则温度上升,造成电路不能稳定工作。因此,发热量大的芯片需要选择散热良好的封装形式,或者额外的冷却系统,如风扇等,这意味着成本的增加。
基于以上原因,功耗成为产品的重要指标与约束。下面的因素在设计之初,就应当列入设计者的考虑范围:
1)功耗目标的确定
a)产品的应用领域中功耗指标的商业价值;
b)封装,制程的成本影响;
c)实现的可行度,复杂度,由此带来的设计风险和时程影响的评估;
d)参考值的选取:根据同类产品,经验值,工具分析确定,并随着设计的深入不断修正。
2)优化方案(策略)的设定
在进一步分析之前,我们先看一下功耗的组成。
2功耗的组成
2.1 core power
功耗的组成包含RAM、ROM、时钟树(clock tree)和核心逻辑电路(Core logic)等四部分,下面依次来分析。
1)RAM
RAM功耗的计算是项复杂的任务,幸运的是,memory compiler可以为我们进行此项工作。关键点在存取每个端口的速率,这可以通过考虑存取pattern类型得到,或者通过仿真得到。建议在设计初期即生成不同参数(宽度,深度,速度,port数)的RAM/ROM的功耗数据,以利于设计探索。
2)时钟树
时钟树的功耗占到整个芯片功耗的40%~60%,因为它的高活动率(100%)和正负边沿均消耗电力。
其中,电容包含寄存器的电容,驱动单元的电容和连线电容三部分。
3)核心逻辑电路
定义核心逻辑电路功耗为除时钟树外的组合与时序单元消耗的电力。由两部分组成:
leakage current和capacitive loads
4)宏单元(macro cell)
多数芯片包含PLL等模拟macro,可以从库提供商的数据手册找到其功耗参数。设计者可以通过切分系统模式关闭不需工作的模块,以减小功耗。
2.2 IO power
IO功耗包含IO单元、外部负载、外部终端等。因为需要驱动板级的连线,IO的电容会是内部单元的数百倍量级,因此消耗较多的电力。有时候,IO的功耗可以占到整体功耗的很大比例,系统架构可能因之改变,如:重新定义系统的划分,以减少芯片-芯片的连接;选择不同的IO接口协议,以减少能量消耗。IO功耗通常由系统架构,接口带宽与协议要求决定。一旦库选定,设计者可以优化的空间很小,但是核心的功耗是设计者可以减小的,在后面的篇幅中,我们将以核心功耗的估算与优化作为主题。
3功耗估算
功耗估算的价值是尽可能早地以定量方式看到优化结果,以助于设计者的初期架构探索。在每个阶段,如产品规划、架构制订、代码书写、综合、P
3.1估算的方法
功耗的估算可以在设计流程的各个阶段进行,对应设计表征的不同形式。
software level ->behavior level -> RT -> gate -> circuit
越早的阶段,抽象层次越高,其精确度越差,但可以更早给设计者反馈,同时得到估算结果消耗的时间越少。
1.软件级
首先,定义系统将执行的典型程序。典型的程序通常会有上百万的机器周期,进行一次完整的RTL级的仿真可能需要数月时间,这是不可接受的。解决的方法是在更高层次建立基本组成单元的功耗模型。
比较实用的方法是根据特定的硬件平台,统计出每条指令对应的功耗数据,进行指令级的仿真。
2.行为级
在进行分析前,我们首先应了解电路的功率消耗原理,实际电路的电力消耗如图1所示。
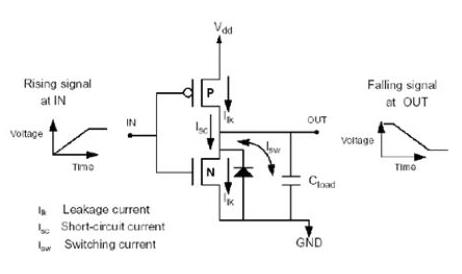
Prms = 1/2 * f * Vdd^2 * sigma(Ci * Ai)
—— f:clock frequency
—— Vdd:voltage
—— Ci is capacitance load of node,
—— Ai is the average switching activity of their node
在行为级设计表征中,物理电路单元尚未建立,难点是得到电容与活动率的值。存在两种思路:
1)理论估计:
根据电路复杂度得到C,复杂度由算术,逻辑操作的数量,状态的数目与转换率衡量。
complex = f(arith ope,boolean ope,state,transition)
可以根据信息理论估算活动率。
2)实验估计:由快速综合得到寄存器传输级的原型,进而估计电容与活动率。
3.寄存器传输级
第一步是在库中为高层的设计组件建立功耗信息算式,得到方式是在不同环境变量组合下通过仿真,统计功耗数据,绘制成曲线形式。然后,通过静态分析电路结构或动态仿真,收集电路动作几率数据,代入上述算式,得到各个组件的功耗值。最后,把所有组件的功耗值求和,得到总功耗。
4.门级
与寄存器传输级的区别在于,基本单元是工艺库中的标准单元,功耗方程通过电路仿真得到,所以更精确。
5.晶体管与版图层
所有的连线的电容、单元的负载,驱动都已得到,根据晶体管和连线模型的电压、电流方程,可以算出精确的功耗数据。
3.2估算的流程
因为指令与行为级估算的精确度太差,电路级估算的耗时过多,所以在业界的实践中采用较少。RTL与gate级估算是常用的选择。实际功耗分析的执行必须借助工具的辅助,目前业界通常的选择是在RTL级采用power compiler,在门级采用primepower.
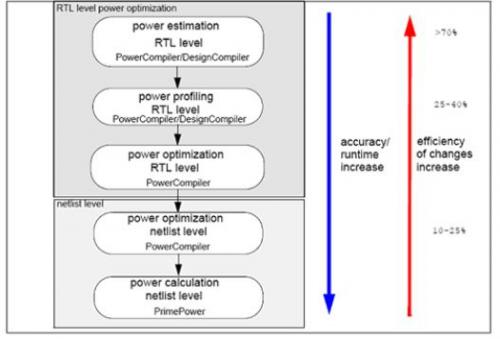
下面以power compiler为例,说明门级估算的步骤。
在dc compile前,设置下面的变量:
power_preserve_rtl_hier_names = false/true
编译
写出ddc文件
仿真生成vcd文件
vcd2saif转化为。saif文件(注意vcd2saif由csh调用,而不是在dc_shell界面调用)
读入ddc网表
read_saif
report_power
4功耗的优化
4.1优化的原则
图3是几个典型设计中功耗分布数据:
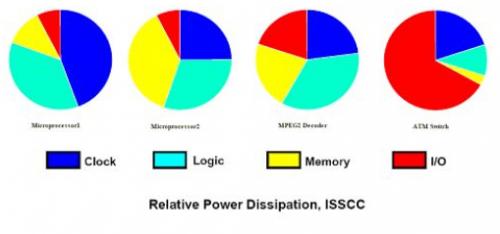
我们的目标是减少时钟树、标准单元和存储器的功耗。功耗与性能通常是充满矛盾的:
1)使时钟变慢(更少的转换),但我们想要更快的处理速度。
2)减小Vdd,但Vdd变小会限制时钟速度。
3)更少的电路,但更多的晶体管可以做更多的工作。
简言之,我们想用最少的能量完成最大量的任务。实现方式是对电路动作的控制精细化,仅让恰好需要的电路,在需要的时间内动作,而不浪费分毫。完成这一任务,需要设计者有效率地管理电路的动作。
现代系统是如此复杂,以致设计者必须切分为若干层次,分步前行才能把握:
软件->架构->逻辑->电路
每一层次中,设计者对电路动作的控制范围和手段都是不同的。软件是硬件动作的总调度师,设计者可以根据特定应用,关掉整个模块或减少无效的动作。进入架构层,视角转为怎样将设定任务合理分配到各个模块,协调动作最有效率,如pipeline、分布式计算、并行计算等。在逻辑层,则考虑怎样实现一步动作仅使需要的电路动作。电路层的视角更为精细,通过调节平衡信号到达时间,驱动单元大小等手段,使电路的动作耗能最小。这里存在一个重要规律,称作效率递减率:
在高的抽象层次减少功耗的效率会比低的层次更高。
所以,降低功耗是一个系统工程,需要软件、硬件、电路、工艺等人员的共同努力。这里,我们将采用架构与逻辑的视角进行下面的讨论。
4.2架构考虑
1)切分工作模式,硬件要可以提供一个接口,以使软件可以控制电路模块的动作与否。不工作的模块挂起。
2)分布式计算:将整个任务切分到不同模块,在内部处理高活动性信号。虽然总计算量没有改变,但对单个模块,时间要求降低,可以降频或降压。
3)并行计算:相同时间内计算量相同,但可降频/压。(计算量=开关的次数,开关次数没变,但每次开关的功耗成本降了)
4)pipeline:每步的计算量减少,可以在性能相同的情况下,降低工作频率。
5)可编程性与hard-wire的权衡:可编程性越强,完成相同的任务耗电越多。
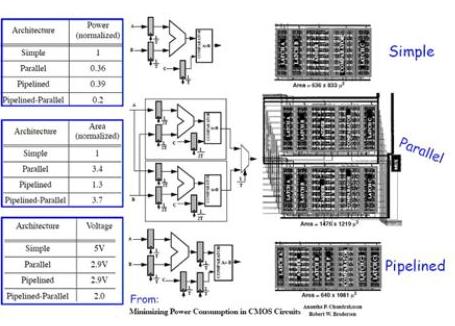
4.3 RAM的功耗优化
很明显,大的RAM比小的RAM耗电要多,将整块的RAM分成小块可以降低存取功耗。
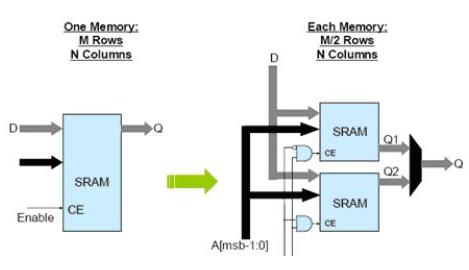
值得注意的一点是,多数设计者认为片选信号无效,RAM即进入最小功耗。实际上,若此时其数据/地址端口信号有翻转,会耗费相当的电力(约占激活功耗的20%)。在不存取时,最佳的方式是,保持片选无效,地址、数据是恒定值。
4.4时钟树单元/连线
4.4.1时钟门控的原理
在典型的数字芯片中,时钟网络的功耗可以占到总量的50%,这是一个庞大的数字。一个行之有效的方案是使用时钟门控,将当前未工作逻辑的时钟树关闭。比如下面的逻辑,在EN是0时,可以将右侧的register bank的时钟关闭。
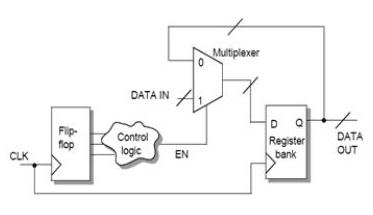
时钟门控逻辑加入的方式有两种:手动和自动。
a)手动方式
在每个IP模块的时钟根节点加入,EN信号可以由程序设定产生。
b)自动方式
dc_shell > set_clock_gating_style(options)选择时钟门控的方式和条件
dc_shell > analyze -f design.v读入设计
dc_shell > elaborate MY_DESIGN构造设计
dc_shell > insert_clock_gating将符合条件的逻辑门控
dc_shell > create_clock -period 10 -name CLK创建时钟
dc_shell > propagate_constraints -gate_clock加入时钟门控单元的时序约束
手动和自动结合的方式可以达到最好的效率。
4.4.2 gating单元的选择
a)latch-based(图7)
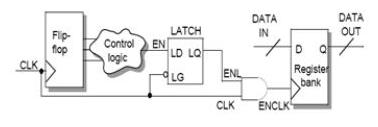
b)latch-free(图8)
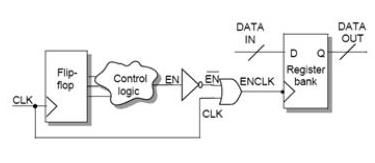
通过set_clock_gating_style的下列选择,设计者可以控制门控单元的选取,如图9所示。

选择考虑:
1)latch:用还是不用,是个问题。
latch-free的方案中,EN信号必须在时钟负沿前稳定,否则时钟会出现毛刺,造成只留给EN产生逻辑半个时钟周期的时间。latch-based方案则不存在这个限制,但引入latch使时序分析,测试复杂性增加。故选择哪种方案需要设计者权衡决定。
2)正沿/负沿寄存器需要指定不同的门控单元
比如latch-based方案:正沿FF用and门,负沿FF用or门
3)integrated clock-gating cell/普通单元
在生成库的过程中,可以创建专门的集成时钟门控单元,以获得较好的时序。
4.4.3时序分析
通过set_clock_gating_style -setup -hold或set_clock_gating_check指定。
AND门(图10)

OR门(图11)
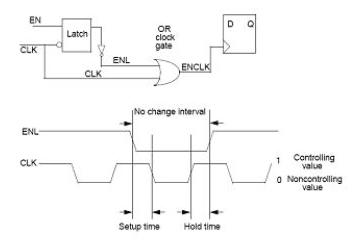
数值需要考虑到时钟歪斜的影响。
4.4.4与dft流程的配合
1)加入控制点(图12)
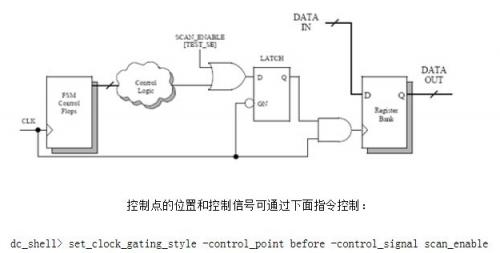
控制点的位置和控制信号可通过下面指令控制:
dc_shell> set_clock_gating_style -control_point before -control_signal scan_enable
2)加入观察点(图13)
在测试中,EN信号和control logic中的信号是测不到的,解决方式是加入观测逻辑。
dc_shell> set_clock_gating_style -control_signal test_mode \
-observation_point true \
-observation_logic_depth depth_value
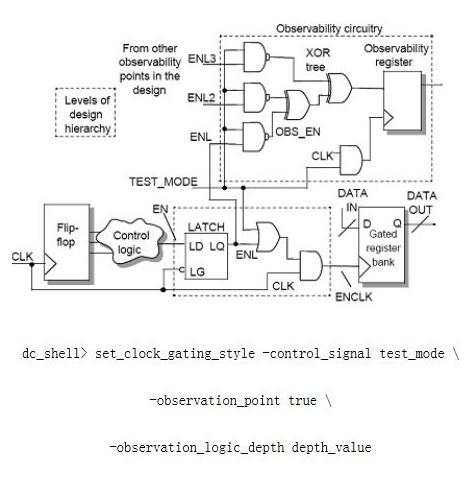
在测试模式,观察逻辑允许观测ENL信号,在正常操作模式,XOR树不消耗能量。
3)测试信号与顶层测试端口连接
时钟门控单元的测试信号需要和顶层的测试端口相连,通过下指令进行,如图14所示。

如果顶层有指定端口,将直接相连,否则,会创建此端口,并连接。
4.4.5结果
在插入时钟树后,可以用report_clock_tree_power来获得时钟网络的功耗信息。
时钟门控经设计实践证明是一个行之有效的降低功耗手段,下图是基于一项真实设计的评估:
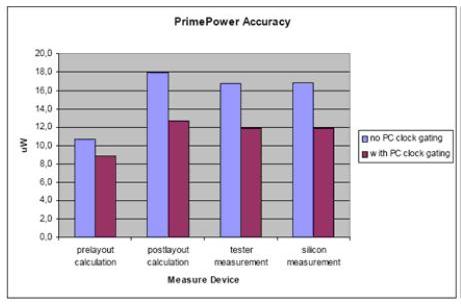
5结语
在现代芯片设计中,功耗越来越引起设计者的关注。在本文中,我们首先分析了功耗的组成部分,然后阐述了功耗估算的方法,通过功耗估算可以使设计者在设计初期及时评估设计方案的效率,以便做出最优的选择。最后,重点分析了功耗优化的手段,包括架构优化,RAM功耗降低,时钟门控三种技术,并对引进时钟门控技术时若干难点逐一提出了解决方案,如门控单元选择,时序分析,测试支持等。功耗分析与优化二者相辅相成,设计者善加使用,方可事半功倍。