1 对称多核体系结构FPGA仿真模型
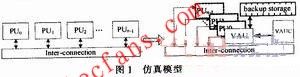
对称多核如SMP(Symmetry Multi-Processor)体系结构中,通常包含多个对称的处理器核或计算核心,这里统称为计算核。计算核占据了多核体系结构的主要硬件开销,且对称多核体系结构的硬件仿真平台FPGA资源消耗随计算核数目成线性增加。这里提出的对称多核体系结构FPGA仿真模型,解耦合计算核数目与系统硬件开销的线性关系,其核心设计思想是:在构建仿真系统时,使用一个与目标系统中单个计算核等同的处理单元,称为虚拟计算单元VAU(Virtual Arithmetic Unit)代替所有的对称计算核,通过分时复用VAU实现一个计算单元虚拟多个计算核的行为。
图l中的左图是当前具有对称结构的多核体系结构模型抽象,n个对称的计算核通过特定的互连结构连接,其连接关系由目标处理器的工作模式决定;右图是本文提出的仿真模型。可以看出,仿真系统中采用一个VAU代替了目标系统中所有对称的处理单元PU。在对目标系统进行仿真时,计算页控制器VAUC(VAU Controller)控制1个VAU分时复用的方式工作,虚拟多个PU并行执行。分时的粒度与处理单元之间的耦合度相关。虚拟计算单元将目标系统中并行执行模式转变为串行执行的方式进行仿真,以时间换取空间,减少系统中计算资源的消耗。BS(Backup Storage)用于存储VAU虚拟各PU执行时的中间结果。
2 仿真系统执行模式
2.1 多核/众核体系结构仿真系统执行模式
对称多核处理器中处理单元之间的耦合度不同,使得对应的仿真系统的执行模式也不一样。多核/众核体系结构通常采用粗粒度耦合执行的方式。如图2(a)所示.多个处理单元之间相互比较独立,其同步和通信通常处于任务级,即多个处理单元间的通信和同步的次数远小于它们执行的指令数。图中PUi和PUj之间有一次通信,PUi、PUj和PUk之间有一次同步。对应的仿真系统的执行模式如图2(b)所示,VAU先对PUi进行仿真,执行到与通信点时,将PUi的执行信息导入BS,然后VAU对PUi进行仿真,执行到与通信点时,将PUj的执行信息导入BS,将PUi的执行信息由BS导入VMU,对PUi的后续行为进行仿真,以此类推,如图2所示,箭头每穿过中线一次,表示计算页切换一次仿真对象,指向下的箭头表示VMU的信息导入BS,指向上的箭头表示BS中的信息导出至VMU。为了减少现场切换的次数,对两个PU通信时的执行过程进行优化,如图2(c)所示,VAU仿真PUi执行至通信点时,切换至PUj进行仿真,只有在PUj遇到其他同步或通信时,才进行现场切换,否则VAU一直对PUj进行仿真,直至PUj执行结束。PUj执行到与通信点时,PUj将通信数据发送至网络缓冲,并写入PUi对应的存储空间,如图2(c)中虚线所示。
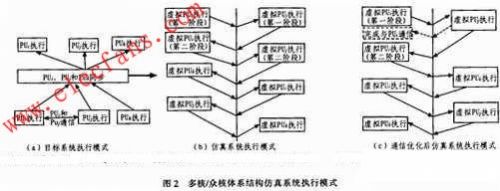
2.2 SIMD体系结构仿真系统执行模式
SIMD体系结构的处理单元之间是紧密耦合的,所有处理单元的执行过程都是严格同步的,即同一时钟周期内每个处理单元都对不同的数据进行完全同样的操作,如图3(a)所示。

在SIMD体系结构仿真系统中,必须在逻辑上保持这种完全同步的执行模式。本文采用的方式是,一条指令流出之后,让它在指令流水线中保持n个时钟周期(可以在连续的n个时钟内都发射同一条指令),VAU在这n个周期内分别对各处理单元对应的数据进行处理。若将n个时钟周期看作系统的工作周期,则n个数据是在同一工作周期内被处理,如图3(b)所示。这样则在逻辑上保持SIMD的执行模式。
3 仿真系统评估
本文的目标系统如图4(a)所示。它由多个计算节点以Torus片上网络连接构成,其计算节点数目可以根据应用需求进行扩展。对应的仿真系统如图4(b)所示。在仿真系统中,采用一个虚拟计算节点(VAU)代替目标系统中的p个计算节点,图4(b)以p=4为例,展示了仿真系统的结构。目标系统中p个计算节点的计算操作都由VAU以图2的工作模式完成。VAU中包含一个现场保存存储器(context backup),用于保存目标系统中p个计算节点的中间结果。contextbackup的容量为每个计算节点中本地存储器容量的p倍,这样,context backup就有足够的能力存储p个计算节点的中间结果,从而减少与外部存储器的数据交换,减少VAU的停顿时间。
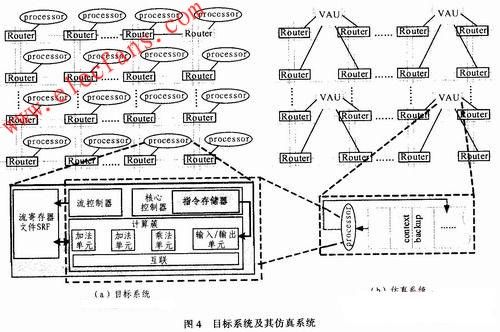
采用FPGA EP2S180(拥有143 520 ALUT,相当于18万逻辑门)实现了多种结构(计算节点的数目不同)的目标系统和基于仿真模型的仿真系统,并利用相应的硬件综合工具Quartus分析仿真系统的FPGA资源开销。系统采用包含1个cluster的MASA流处理器作为计算节点。为更好地验证仿真模型,流处理器中采用功能裁剪的cluster,如图4所示,cluster中仅包含3个计算单元和1个I/O单元,并相应降低指令和数据存储器的容量。在仿真系统中,VAU中的processor为流处理器中的核心计算部件,context backup代替了片上存储部件,其容量为SRF的p倍。该实验的目的是分析所提出的仿真模型对仿真系统的硬件资源消耗和仿真速度的影响。
3.1 资源消耗分析
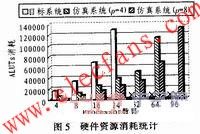
图5是目标系统和仿真系统的FPGA资源消耗统计。由于布局布线的需求,FPGA芯片的资源使用率最高通常只能达到70%~80%。图5中“×”标识表示当前配置超出EP2S180的仿真能力。可以看出,在不采用仿真优化技术时,EP2S180可仿真的最大规模目标系统为24个计算节点。基于本文的仿真模型,当p值等于4时,EP2S180的仿真能力提高至64个节点;当p值等于8时,其仿真能力提高至96个节点。当p值增大时,其仿真能力可进一步提升。实验结果表明,本文提出的仿真模型能够增大FPGA芯片可仿真系统的规模。
3.2 仿真速度分析
本文采用矩阵乘运算,分别在8、16、32个节点的目标系统和仿真系统上执行,测试二者的仿真速度。目标系统和仿真系统的工作频率为75 MHz。图6展示了二者的执行时间。
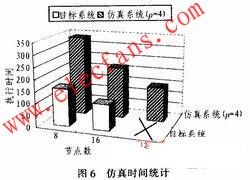
可以看出,仿真系统的执行时间大于目标系统。其时间增量主要是由于仿真系统将目标系统中多个processor并行处理的任务移植到一个VAU上串行执行造成。仿真系统没有改变目标系统的数据传输路径和模式,因此,数据传输的时间并没有增加。另外,由于VAU虚拟的p个pro-cessor共享了存储空间,仿真系统中消除了p个processor之间的数据传输时间。虽然仿真系统相对于目标系统执行时间有所增加,但其时间增量处于秒级。相对于缓慢的软件模拟器,并综合考虑仿真模型对FPGA仿真规模带来的好处,因此认为该仿真模型带来的仿真时间增量是可以接受的。
4 结束语
本文提出了面向对称多核体系结构的FPGA仿真模型,以及基于该模型的多核/众核、SIMD体系结构的执行模式。相对于软硬件联合仿真方法,该仿真模型减少了软硬件协同逻辑并避免了设计复杂的软件划分算法。实验结果表明,面向对称多核体系结构的FPGA仿真模型能有效地减少仿真系统FPGA资源的需求,增大FPGA的仿真规模,并且其带来的仿真时间增量是可接受的。但该仿真模型主要是面向对称体系结构,而不适用于异构多核系统等非对称结构。