随着技术的发展,在导弹控制和通信等领域,需要处理的任务规模越来越大。虽然随着VLSI技术的发展,已产生了运算能力达每秒几十亿次的处理器,但还远远不能满足这些领域的需求。而VLSI技术的发展已受到其开关速度的限制,进一步提高处理器主频遇到的困难越来越大。为此,把用于大型计算机的并行处理技术应用到信号处理中来,在信号处理系统中引入并行多处理器技术是必然趋势。传统弹载计算机一般针对特定场合,先确定算法,再根据算法确定系统结构,由于系统结构与算法严格相关,因此通用性较差。随着一些标准技术(标准板型、接口、互联协议等)在弹上控制系统中的应用,设计标准化、模块化的通用型计算机成为了可行。而且所设计的还要可扩展、可重构,进而根据不同的应用场合和算法构建各种弹载计算机系统。
1 并行弹载计算机处理结构模型
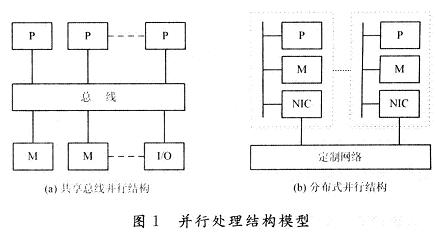
普遍的两种并行处理结构如图1所示,一种是共享总线结构,另一种是分布式并行结构。其中,P(Proces-sor):处理器;M(Memory):存储器;MB(Memory Bus):存储器总线;NIC(Network InteRFace Circuitry):网络接口电路。共享总线结构中多个处理器P经由高速总线连向共享存储器,每个处理器等同地访问共享存储器、I/O设备和操作系统服务。分布式并行结构中多个处理节点通过高通信带宽、低延迟的定制网络互联,每个处理节点都有物理上的分布存储器,节点间通过消息传递相互作用。
并行处理的目的是采用多个处理器同时对任务处理,从而减小任务执行时间,它主要反映在加速比(S)和并行效率(E)上。加速比是指对于一个特定应用,并行算法的执行速度相对串行算法加快了很多倍。效率则是针对每个处理器来衡量的。依据并行处理中可扩放性(Sealability)评测的等效率度量标准可从理论上评测这两种结构。
首先考虑共享总线结构。设![]() 分别是并行系统上第i个处理器的有用处理时间和额外开销时间。设每个处理器上子任务的运算量和通信量之比为r,即平均r次运算中有一个数据需要交换。总线被p个处理器轮流访问,tio。是处理器完成一次总线存取所需的相对时间,等效为处理器运算能力和总线访问能力之比。一般情况下,总的处理时间和额外开销时间如下:
分别是并行系统上第i个处理器的有用处理时间和额外开销时间。设每个处理器上子任务的运算量和通信量之比为r,即平均r次运算中有一个数据需要交换。总线被p个处理器轮流访问,tio。是处理器完成一次总线存取所需的相对时间,等效为处理器运算能力和总线访问能力之比。一般情况下,总的处理时间和额外开销时间如下:

假设任务均匀分成p部分,就有:Te=pt。在最坏情况下,p个处理器总是同时访问总线,考虑最后得到总线访问权的处理器:
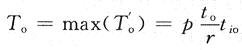
Tp是每个处理器上并行算法运行时间,在最坏情况下,Tp=Te+To。设问题规模W为最佳串行算法完成的计算量,即W=Te,加速度比:
显而易见,共享总线系统的并行效率随着处理器数目p的增大而下降。
而在分布式并行系统中,理想情况下任一时刻都可有两个处理器通过其通信口相互交换数据,设一个通信口传送一个数据的相对时间为tcomm,等效为处理器运算能力和通信口传输能力之比。同时,假设每次交换还需对本地存储器访问。这样就有通信开销:
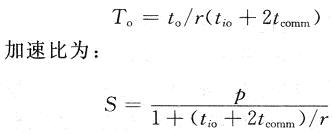
和处理规模p成线性关系,并行效率与p无关。
以上讨论的是假设任意两个处理器之间可以直接进行数据交换,而在实际情况下,尤其是处理器数目p多于处理器的通信口数量时,两个非直接相连的处理器之间的数据交换所需开销与其经过的路径成正比关系。但这并不影响以上讨论的公式。因为在规则网络拓扑结构中最大或平均路径是一个定值n,那么这时,分布式并行系统的加速比公式为:
![]()
可见,在这种情况下分布式并行系统同样能获得线性加速比。由以上理论分析可知,共享总线并行结构适合共享存储编程模型,进行细粒度的并行处理,但其扩展性能较差,处理器的数目有限,单机处理性能有限;分布式并行结构采用消息传递的机制,适合进行粗粒度的并行处理,便于大规模的系统扩展,提供强大的整体性能。
2 弹载计算机的设计实现
由于弹上信号处理算法的复杂性,信号处理系统具有复杂多样的并行处理模式,如基于空间的数据并行处理、基于时间的流水并行处理等。另外,弹上计算机系统具有多种类型的数据流,如原始数据流(A/D采集之后的数据流)、中间数据流(各处理节点之间传递的数据流)、定时同步信号以及控制数据流等。这些不同的数据流的传输带宽不同,因此系统中要有与这些不同数据流相匹配的互联网络。
高性能通用并行弹载计算机是构建信号处理系统的基础。它除了选用高性能的处理器外,为了具有通用性,还要具有标准化、模块化、可扩展、可重构的特点,以便构建各类控制和信号处理系统。同时为了适应控制和信号处理系统复杂并行处理模式和多种数据流的特点,它要具有混合的并行模式和多层次的互联网络。基于这些要求和上文中对并行处理结构模型的理论分析,笔者选用当前业界最高性能的浮点DSP芯片TS201和大规模FPGA,设计了一个标准化、模块化、可扩展、可重构、混合并行模式、多层次互联的高性能通用并行弹载计算机。图2是其结构框图。
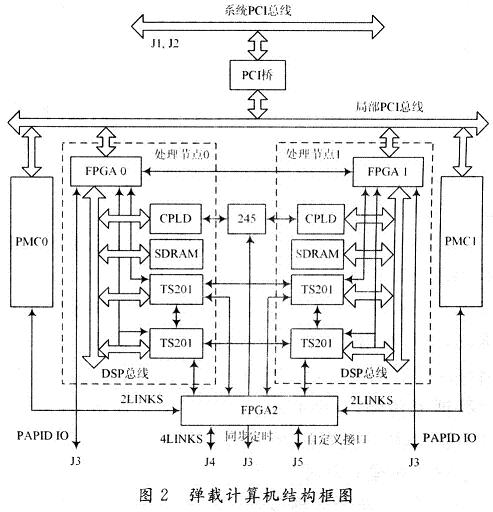
该弹载计算机选用标准cPCI 6U板型,板内集成了两个处理节点,同时可承载两个PMC子板。
2.1 DSP+FPGA共享总线型处理节点
弹上控制和信号处理系统中,低层的信号处理算法处理的数据量大,对处理速度要求高,但运算结构相对简单,适于用FPGA实现,这样能同时兼顾速度及灵活性。高层处理算法处理的数据量较低层算法少,但算法的控制结构复杂,适于用运算速度高,寻址方式灵活,通信机制强大的DSP来实现。
为此,笔者设计的弹载计算机主要包括DSP,FP-GA,SDRAM和CPLD。DSP主要实现数据的高层算法处理和控制,FPGA实现对外的接口,并可对输入输出的数据进行低层算法预处理,SDRAM用来缓存数据,CPLD用来实现一些辅助逻辑。选用的DSP芯片是ADI公司的TS201,单片处理能力3.6 GFLOPS,内核时钟频率600 MHz,片内内存24 Mb,125 MHz/64 b片外总线,具有1 GB的SDRAM访问能力,还有4个Link口,每个Link口收发独立,最高带宽为1.2 GB/s。
所有特点都使得TS201适合多片扩展,构成一个大规模高性能的信号处理系统。选用的FPGA芯片为Xilinx公司的VirtexⅡpro系列XC2VP20,它的规模约200万门,内部集成了1 584 Kb的RAM,88个18×18 b的乘法器,8个传输速率可达3.125 Gb/s的Rock-etIO高速通道,这些特点使得该FPGA适合实现数据的传输和预处理。而且它的管脚兼容XC2VP30/40,可实现FPGA规模的进一步扩展。每个处理节点包括两片TS201,一片FPGA,最高4 GB的SDRAM,以及一片CPLD,并共享总线。之所以只用两片TS201,是考虑到总线上设备太多,会使得总线时钟频率降低,带宽变小,并行度和效率都不高。两片TS201共享总线充分发挥了处理能力、传输能力、存储能力的匹配性。TS201总线上的SDRAM最高支持1 GB的空间,通过CPLD进行逻辑控制,可使SDRAM扩展到4 GB,增加了存储能力,适应大容量存储应用的场合。
2.2 多层次互联网络
互联网络是构建一个并行处理和控制系统的关键。本弹载计算机利用系统PCI总线、TS201的Link口,基于FPGA的RocketIO物理通道实现的串行RapidIO协议,以及利用CPLD实现的同步定时总线,构成了不同层次的互联网络,以便适应信号处理系统中不同类型的数据流传输。cPCI标准通过J1,J2连接64 b系统PCI总线,PCI桥把系统PCI总线转换为局部PCI总线。每个处理节点通过FPGA(FPGA 0和FPGA 1)实现PCI接口,两个处理节点和两个PMC子板共享局部PCI总线,并通过PCI桥与系统PCI总线连接在一起。这使得系统主控模块可以通过PCI总线实现对每个处理节点以及PMC子板的控制。同时各个节点之间也可通过。PCI总线交换数据。但由于总线的限制,只能实现一些低速、非实时的数据交换。TS201具有4个高速Link口,可实现多片TS201之间的高速数据传输。对于板内的4片TS201,利用各自2个Link口构成1个环形Link连接,使得板内4片TS201紧密耦合在一起。另外,每片TS201的1个Link口共4个Link口连到FPGA 2(称之为Link Switch)上,同时每个PMC的PJ4上也定义两个Link口,板卡的J4上定义4个Link口,所有这些Link口都连到FPGA2上。通过FPGA2,可以灵活地配置板内、板内与PMC子板、板间不同节点构成不同的Link互联网络,并且可以利用。FPGA的动态加载功能,动态地配置不同的Link互联网络结构。FPGA2同时还与J5上的32 b自定义接口连接,可实现一些用户自定义接口。同时每个处理节点内的2片TS201还有1个Link口都连到了节点内总线上的FPGA(FPGA0和FPGA1),与该FPGA对外的串行RapidIO接口相配合,实现外部串行RapidIO数据流与TS201内部数据的交换。Link口具有大带宽、低延时的特点,因此适合用来传输原始数据流和一些带宽大,实时性强的中间数据流。串行RapidIO是基于包交换的第三代互联协议,相比TS201的Link协议,它具有更为完善的分层协议定义(包括逻辑层、传输层和物理层)。该协议使得模块具有更强的通用性,不仅可以与同类型的各模块互联,还可以与任何具有串行RapidIO接口的异构模块互联。利用FPGA的Rocke-tIO物理通道,通过FPGA编程可实现串行RapidIO协议。FPGA0和FPGA1通过4个RocketIO通道直接相连,可实现二者之间4个1×模式或1个4×模式的串行RapidIO接口。同时,FPGA0和FPGAl还各自通过4个RocketIO与J3相连,这样通过J3,弹载计算机就可以以8个1×模式或2个4×模式的串行RapidIO接口与其他模块互联,构成多个模块之间的串行Ra-pidIO互联网络。串行RapidIO网络也具有大带宽的特性,而且相比Link口具有更为完善的协议控制,但正是由于复杂的协议控制,使它的传输延时相比Link口更大。因此,它可与Link网络形成很好的互补,用来传输大带宽,延时要求不高的数据流。在J3上定义了8 b同步定时信号,用来实现各个节点之间的同步定时控制。这些信号通过RS 245驱动后与每个节点内部的CPLD相连。每片TS201可通过中断或读写寄存器等方式对节点内的CPLD进行操作,进而通过CPLD内部逻辑产生相应的同步定时信号进行各个节点之间的同步。RS 245的双向性使得每个节点既可以发出同步信号,也可以接收同步信号,更加灵活。该模块所有对外的互联接口都是通过J1~J5接插件连接,这样就可以在底板上把各个模块之间的各个接口连接起来。而且既可以使用固定拓扑结构的无源底板,也可以使用带有交换芯片的有源底板或专门的交换板,灵活构建各类互联网络。
3 应用验证
该弹载计算机具有通用化、可扩展、可重构的特点。可根据不同的需求,通过增减弹载计算机来改变处理能力,通过改变各模块之间的互联形式来适应不同的算法。下面以基于该弹载计算机构建数据并行的相控阵雷达信号处理系统来验证这些特点。图3是以该弹载计算机构建的某相控阵雷达信号处理系统结构框图。
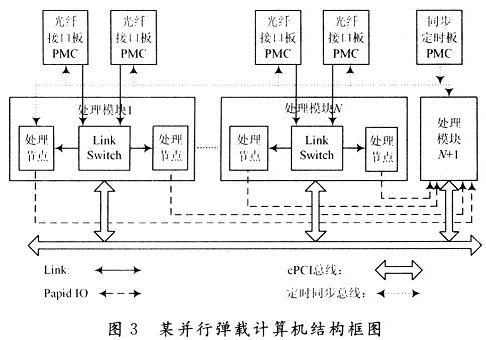
该系统采用光纤与相控阵天线阵列之间传输数据,把光纤接口板做成标准PMC板型,可以集成在弹载计算机中。每个弹载计算机集成两个光纤接口板,一个光纤接口板接收一个子阵的回波数据,并通过弹载计算机上每个PMC板卡的PJ4上定义的Link口,经LinkSwitch把数据传给每个处理节点。每个处理节点对数据进行波束形成,然后再把形成的子阵波束通过J3定义的串行RapidIO接口传给进行子阵级波束形成的弹载计算机。该模块进行子阵级波束的形成以及其他雷达信号的处理,并承载PMC板型同步定时模块,由其产生系统中各个模块的同步定时信号,使各个模块同步工作。该处理系统采用数据并行的处理模式,每个节点处理一个子阵的回波,可以通过增减处理节点来灵活适应天线阵列的增减。
4 结 语
并行计算机是解决信号处理控制领域任务规模不断增大、问题不断复杂的关键技术。本文在分析了共享总线和分布式并行两种并行模型优缺点的基础上,设计并实现了一种适应信号处理系统需求的混合并行、多层次互联、标准化、模块化、可扩展、可重构的高性能通用并行弹载计算机。实际中,使用该弹载计算机,配合相应的I/O模块,构建了多个相控阵雷达、合成孔径雷达、图像处理等弹载计算机系统,获得了广泛的应用,验证了该弹载计算机的高性能、通用性。