摘要
随着生活水平的不断提高,卡拉OK练歌房在我国已经非常普遍。卡拉OK机的自动评分功能往往会引起一些人的兴趣,觉得机器能够自动评分是件挺神奇的事。但同时也会发现它有一个很大的缺点--评分不太准。本项目立足于近几年出现的一些数据处理和控制集成芯片,将一些语音信号处理的专用算法应用到评分系统中来,以改进现行系统,增强评分的准确性。
研究背景
近年来随着我国经济的飞速发展,人民的生活水平不断地提高。全国各地的KTV产业蓬蓬勃勃的发展,大街小巷随处可见KTV练歌房的身影。而我们的邻邦韩国和日本,KTV产业更是庞大,到卡拉OK练歌房唱日本民歌甚至已经逐步演变为日本的一种民族风俗。正是由于卡拉OK目前如此的流行,促使卡拉OK设备生产商对这个领域进行大量的投入和研发,因此卡拉OK系统不断地得到完善,功能也不断地增强。从上世纪90年代开始,人们逐渐开始关注卡拉OK的自动评分功能。当演唱完一首歌以后,经过一段延迟时间,机器便能自动算出一个分数来,这始终是一件让人觉得挺有意思的事情。
当这个想法被一个叫唐骏的中国留学生提出并付诸实践后,立即在日本引起了巨大的轰动。人们普遍都感到非常的新奇,都想尝试尝试这种有趣的机器,这就造就了第一个买下这项专利的三星公司的卡拉OK设备的销售量的飞涨,甚至有人评价说是这项发明挽救了当时处在市场危机中的三星公司。不过,过了一段时间人们发现这种机器有一种问题——评分不准。后来这项专利的发明者唐骏也公开表示,该系统的评分效果不是很准确,演唱时只要尽力模仿唐骏的声音就一定能得到高分。
正是由于这套系统的这些缺点与不足,后来又有很多专家学者陆续投入到语音打分系统的研究中来,激起了一次研究卡拉OK打分系统的热潮——1990年到1998年。这些研究人员主要是日本人,因为日本的卡拉OK非常的盛行。在这期间,他们申请了将近十几项专利,不过没有发表过一片论文,毕竟这是一个可以赚大钱的东西。这些专利可以分为以下几类:
从时域波形出发,对演唱者的音频信号和机器自带的原唱信号进行采样,然后比较各个采样点的大小,如果比较一致则得分高,否则得分低。
从能量的角度出发,对演唱者的音频信号和伴奏音乐分别用A/D进行数字化,然后对两种数字信号的规格化能量进行比较和差异测量,最后根据两者差异情况给分。
从频域分析的角度出发,首先将机器自带原唱信号与伴奏乐声进行小波变换,再将演唱者的音频信号与伴奏音乐进行小波变换。比较两次得到的频谱信号的分布情况,越是一致则得分越高。
到98年以后,这一领域才逐渐开始降温,也没有多少新的专利或者是相关文献出现。而且,即使是上文叙述的那些专利也没有多少投入到商业生产中。这些专利发明有一个共同的特点,那就是计算量非常大,受限于当时的硬件水平,实现起来不是很令人满意。这也可以理解,毕竟要是一首4分钟左右长的歌曲唱完后需要几十分钟的计算后才能得到一个分数,那将是令人无法容忍的事情。
目前市场上正在销售的那些卡拉OK机一般都带有自动评分的功能。但基于上文分析的原因,90年代研究者申请的那些专利都没有在这些商品中得到实际的应用。各个生产厂家正在使用的那些评价标准基本都是当年唐骏发明的那套设备,俗称“唐骏标准”。但还是多少有一些差别,高档一点的可能做一下FFT,进行频频分析;低档次的甚至是直接比较音量的大小,音量越大得分越高。有人曾做过实验,让一个三岁小孩在万利达的卡拉OK机前大声哭着喊妈妈,结果由于小孩子声带小,发声频率高,音量又大,竟得了98分,非常匪夷所思。前一段时间流行的江苏卫视的《谁敢来唱歌》栏目也应有了机器打分系统。他们从国外引进了一套叫SAM的系统,使用时先将每首歌的原音预录进去,然后设置10个关键字点。得分的高低,取决于这10个关键字唱得准不准,也许别的地方唱得不特别准,但关键字唱对了,选手也能得高分。使用后被很多观众抱怨评分不准。
经过近几十年的发展,硬件设备尤其是大规模集成电路技术取得了巨大的进步。目前最新的DSP芯片每秒能进行上百万次的运算,XILINX的FPGA的并行处理能力也已经非常强大了。用这些芯片对音频信号进行一些FFT运算和频域分析,硬件方面已经没有问题了。因此,本文提出一种基于FPGA和DSP的新型卡拉OK评分系统。本系统除了运用一些新型的集成芯片来进行运算处理,还提出了一种改进了的评分算法,来尽量减小评分所需的运算量,同时使评价结果与演唱者实际水平尽量吻合。
语音信号的基本特征
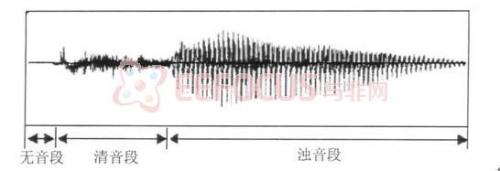
图1:一段语音的时域波形图
图[1]是一小段语音的时域波形图,可以看出,语音一般由三部分组成:无音段、清音段和浊音段。无音段不存在语音信号,在背景噪声较低的情况下,幅度近似为零。清音信号的幅度很小,没有规律,类似于随机噪声。浊音信号幅度较大,波形的上下起伏近似呈现周期性,称之为准周期性。语音信号有两个重要的时域参数:短时能量和基音周期。从图2.1可以看出信号的幅度随时间改变而变化显著,短时能量可以反映这一特性,其定义如下:
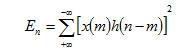 (2.2.1)
(2.2.1)
短时能量的主要意义在于给出了区分清浊音的基础,清音的短时能量明显小于浊音的短时能量,用短时能量可以大体分辨出清音、浊音以及清音变成浊音的时刻,对于质量很高(高信噪比)的语音,也可用来区分有音与无音。
从图[1]可以看出,浊音信号是一个准周期信号,其周期称为基音周期,基音周期的倒数称为基频 (Pitch)。基音周期实际上是声门波往复一次的时间长度。声门波是指声门气流的速率随时间变化的函数曲线。通常而言,当声带闭合时,声门处受阻聚积的气流会逐渐冲开声带,气流速率也随之开始缓慢地增大,达到最大值后由于声带突然闭合,气流速率陡降为零,如图[2]所示。
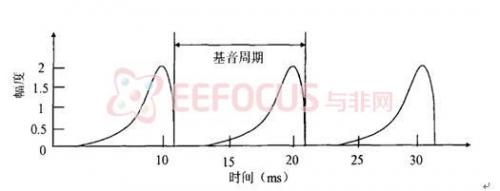
图2:周期性变化的声门气流速
不同说话人发出同一浊音时,基频差异明显,尤其是男女声。一般来说,正常成人男声的基频在0—200Hz左右,正常成人女声的基频为200—450Hz,小孩的基频比女声的基频还要高,老人的基频则比正常成年男声还要低。
语音信号还有一个很重要的特性即短时平稳性,语音信号是非平稳信号,但在某一个比较短的时间里,语音信号可以被看成是平稳的。这段时间一般可取为5—50ms。短时平稳性是语音信号处理的基础。
频域特性
对一段语音进行分帧加窗后再进行傅立叶变换就可以得到该帧语音的短时谱。清音的短时谱类似于随机信号的频谱。而浊音信号的短时谱有两个特点:第一,有明显的周期性起伏,这是因为浊音的激励源为周期脉冲气流;第二,频谱中具有几个明显的凸起点,它们对应的频率与声道的谐振频率一致。这些凸起点称为共振峰(Formant),其频率称为共振峰频率,简称共振峰。共振峰按频率由低到高排列依次为第一共振峰、第二共振峰、…,一般用字母F1、F2…来表不。一般浊音中前二个共振峰对说话人的个性特征影响较大,而前两个对于区别不同语音至关重要。
语音信号的特征参数 短时频谱
语音信号特征在较短的时间间隔中保持基本不变,即语音信号具有时变特性,因而可以将语音信号看作是一个短时平稳过程。语音信号具有一些重要的短时特征。短时频谱是语音信号的一个重要的短时特性。
B:短时自相关函数
S:自相关函数Rw(г)称为S(n)的短时自相关函数。
T:短时平均幅度
S(n)的短时平均幅度计算公式如下:
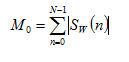 (3.1)
(3.1)
短时过零率
信号按段分割就称为短时,段可是帧大小。过零就是信号的幅度值从正值到负值、负值到正值要经过零点,统计信号在一秒钟内有几次过零就是过零率。以短时能量为主,短时过零率为辅,可对语音信号中的清音进行较精密的检测。
倒谱
倒谱是一段语音信号的一组重要参数。要计算信号SW(n)的倒谱,首先要计算SW(n)的离散傅立叶变换,然后对离散傅立叶变换的模取对数,最后再做傅立叶反变换,这样得到的c(n)被称做是“倒频谱”或“倒谱”。
还有其它的一些特征参数,由于在本文中或者在音频信号的研究中应用的较少,在这里就不一一介绍了。
实现原理与方案
下面来详细叙述一下本文提出的评分算法。在叙述中将会遇到两种音频信号,为方便起见,我们称卡拉OK机内自带的专业歌手原唱的音频信号为原唱,称卡拉OK机的使用者演唱的音频信号为翻唱。评价过程分为两个部分来完成。
首先进行时域分析,判断演唱者的协调性。由前几段对音频信号的特点可知,音频信号的时域波形并不是连续的,而是一段一段的,每一段大约持续10ms—30ms,称为一个音节。时域分析主要是针对各个音节进行分析,先用短时加窗法将信号进行分帧,然后计算出各帧信号的能量主要集中区域。比较根据两种信号得到的能量主要集中区域,如果比较吻合则说明演唱者的协调性很好,可给一个较高的分数;如果两种情况下的区域对得不是很齐,则说明协调性不好,得到应该给低一点。每次比较完一帧便将比较结果记录到存储器的特定区域。
在时域分析的同时进行频域分析,如软件流程图[3]所示,时隙分配是每取出一帧,先对它进行时域分析,记录完分析结果后,再将信号进行FFT变换,做频域分析。主要是比较原唱和翻唱频谱曲线的一致性,借助于频谱分析分别比较高频段和低频段。根据相似性得到一个得分。
本项目的实现是通过用System Generator 进行仿真,用MatlabaZ中的Simulink来实现具体的仿真, 并将最后的结果导入到FPGA中已实现最终的目的。
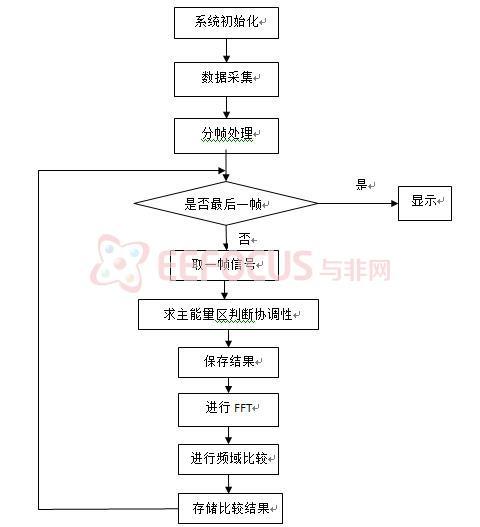
图3:软件流程图
当把所有帧都分析完以后,再将各帧的得分相加,进行百分制处理,即可得到总得分。最后将该得分送入液晶显示。
其中的系统框图如图[4]所示:
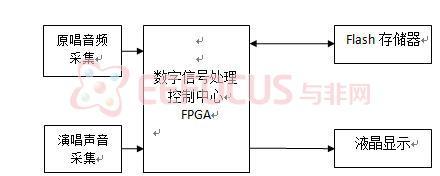
图4:系统框图