第一次使用Xilinx 的FFT的IP core。没有太多的资料和实例可以学习,只有一个软件自带的文档xfft_ds260,而且是英文的,看了很长时间受益不大。然后决定一边用一边再学习,就自己建立了一个工程实验。
这个IP核可以选择多种结构的,什么基4的,基2,基lite,pipelined.streaming i/o,burst i/o ,各种结构。我选择的目的是结口最少,操作最简单。最后选择了基2 lite ,burst i/o 结构的,定点,输出不选顺序的,从而避开了那些没有理解的操作。值得注意的是xk_index与输入数据之间有三个时钟的延时。
最后得到的结口是
module fft8 (
fwd_inv_we, rfd, start, fwd_inv, dv, done, clk, busy, edone, xn_re, xk_im, xn_index, xk_re, xn_im, xk_index
);
input fwd_inv_we;
output rfd;
input start;
input fwd_inv;
output dv;
output done;
input clk;
output busy;
output edone;
input [15 : 0] xn_re;
output [19 : 0] xk_im;
output [2 : 0] xn_index;
output [19 : 0] xk_re;
input [15 : 0] xn_im;
output [2 : 0] xk_index;
。
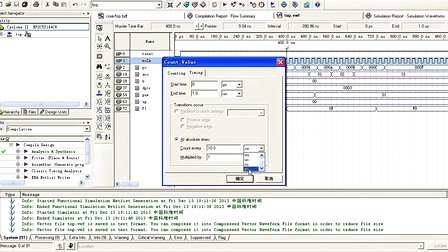
然后进行仿真:
testbench是自动生成的,只添加了下面的部分,很简单的:
nitial begin
// Initialize Inputs
clk = 0;
xn_re = 0;
xn_im = 0;
start =0;
fwd_inv_we=0;
fwd_inv=0;
// Wait 100 ns for global reset to finish
#100;
start =1;
fwd_inv_we=1;
fwd_inv=1;
// Add stimulus here
end
always #5 clk = ~clk;
always @(posedge clk)
begin
xn_re= xn_re + 1;
end
仿真的结果是


这时的的一个输入:8个数据:14至22的8个数,所示的结果为:
0 140+j*0,
1 -4+j*9,
2 -4+j*4,
3 -4+j*1,
4 -4+j*0,
5 -4-j*2,
6 -4-j*4,
7 -4-j*10
然后我们通过matlab 进行一个fft的运算,验证这一结果的准确性:
代码是:
n=0:1:7;
s=n+14;
>> y=fft(s,8);
>> y
y =
1.0e+002 *
Columns 1 through 6
1.4000 -0.0400 + 0.0966i -0.0400 + 0.0400i -0.0400 + 0.0166i -0.0400 -0.0400 - 0.0166i
Columns 7 through 8
-0.0400 - 0.0400i -0.0400 - 0.0966i
考虑到有限精度的问题,显然结果是正确的。
另外需要说明的是FFT输出的结果是二进制补码形式,我在仿真显示结果进行了转换,将二进制补码表示成了有符号的十进制,以便对比。